 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness of Spatio-temporal Graph Neural Networks for Fault Location in Partially Observable Distribution Grids
Apr 22, 2026Fault location in distribution grids is critical for reliability and minimizing outage durations. Yet, it remains challenging due to partial observability, given sparse measurement infrastructure. Recent works show promising results by combining Recurrent Neural Networks (RNNs) and Graph Neural Networks (GNNs) for spatio-temporal learning. Still, many modern GNN architectures remain untested for this grid application, while existing GNN solutions have not explored GNN topology definitions beyond simply adopting the full grid topology to construct the GNN graph. We address these gaps by (i) systematically comparing a newly proposed graph-forming strategy (measured-only) to the traditional full-topology approach, and (ii) introducing STGNN (Spatio-temporal GNN) models based on GraphSAGE and an improved Graph Attention (GATv2), for distribution grid fault location; (iii) benchmarking them against state-of-the-art STGNN and RNN baselines on the IEEE 123-bus feeder. In our experiments, all evaluated STGNN variants achieve high performance and consistently outperform a pure RNN baseline, with improvements up to 11 percentage points F1. Among STGNN models, the newly explored RGATv2 and RGSAGE achieve only marginally higher F1 scores. Still, STGNNs demonstrate superior stability, with tight confidence intervals (within +/- 1.4%) compared to the RNN baseline (up to +/- 7.5%) across different experiment runs. Finally, our proposed reduced GNN topology (measured-only) shows clear benefits in both (i) model training time (6-fold reduction) and (ii) model performance (up to 11 points F1). This suggests that measured-only graphs offer a more practical, efficient, and robust framework for partially observable distribution grids.
Neural Network-Assisted Model Predictive Control for Implicit Balancing
Apr 02, 2026In Europe, balance responsible parties can deliberately take out-of-balance positions to support transmission system operators (TSOs) in maintaining grid stability and earn profit, a practice called implicit balancing. Model predictive control (MPC) is widely adopted as an effective approach for implicit balancing. The balancing market model accuracy in MPC is critical to decision quality. Previous studies modeled this market using either (i) a convex market clearing approximation, ignoring proactive manual actions by TSOs and the market sub-quarter-hour dynamics, or (ii) machine learning methods, which cannot be directly integrated into MPC. To address these shortcomings, we propose a data-driven balancing market model integrated into MPC using an input convex neural network to ensure convexity while capturing uncertainties. To keep the core network computationally efficient, we incorporate attention-based input gating mechanisms to remove irrelevant data. Evaluating on Belgian data shows that the proposed model both improves MPC decisions and reduces computational time.
CLASP: Defending Hybrid Large Language Models Against Hidden State Poisoning Attacks
Mar 12, 2026State space models (SSMs) like Mamba have gained significant traction as efficient alternatives to Transformers, achieving linear complexity while maintaining competitive performance. However, Hidden State Poisoning Attacks (HiSPAs), a recently discovered vulnerability that corrupts SSM memory through adversarial strings, pose a critical threat to these architectures and their hybrid variants. Framing the HiSPA mitigation task as a binary classification problem at the token level, we introduce the CLASP model to defend against this threat. CLASP exploits distinct patterns in Mamba's block output embeddings (BOEs) and uses an XGBoost classifier to identify malicious tokens with minimal computational overhead. We consider a realistic scenario in which both SSMs and HiSPAs are likely to be used: an LLM screening résumés to identify the best candidates for a role. Evaluated on a corpus of 2,483 résumés totaling 9.5M tokens with controlled injections, CLASP achieves 95.9% token-level F1 score and 99.3% document-level F1 score on malicious tokens detection. Crucially, the model generalizes to unseen attack patterns: under leave-one-out cross-validation, performance remains high (96.9% document-level F1), while under clustered cross-validation with structurally novel triggers, it maintains useful detection capability (91.6% average document-level F1). Operating independently of any downstream model, CLASP processes 1,032 tokens per second with under 4GB VRAM consumption, potentially making it suitable for real-world deployment as a lightweight front-line defense for SSM-based and hybrid architectures. All code and detailed results are available at https://anonymous.4open.science/r/hispikes-91C0.
Hidden State Poisoning Attacks against Mamba-based Language Models
Jan 06, 2026State space models (SSMs) like Mamba offer efficient alternatives to Transformer-based language models, with linear time complexity. Yet, their adversarial robustness remains critically unexplored. This paper studies the phenomenon whereby specific short input phrases induce a partial amnesia effect in such models, by irreversibly overwriting information in their hidden states, referred to as a Hidden State Poisoning Attack (HiSPA). Our benchmark RoBench25 allows evaluating a model's information retrieval capabilities when subject to HiSPAs, and confirms the vulnerability of SSMs against such attacks. Even a recent 52B hybrid SSM-Transformer model from the Jamba family collapses on RoBench25 under optimized HiSPA triggers, whereas pure Transformers do not. We also observe that HiSPA triggers significantly weaken the Jamba model on the popular Open-Prompt-Injections benchmark, unlike pure Transformers. Finally, our interpretability study reveals patterns in Mamba's hidden layers during HiSPAs that could be used to build a HiSPA mitigation system. The full code and data to reproduce the experiments can be found at https://anonymous.4open.science/r/hispa_anonymous-5DB0.
Model Predictive Control-Guided Reinforcement Learning for Implicit Balancing
Oct 06, 2025



In Europe, profit-seeking balance responsible parties can deviate in real time from their day-ahead nominations to assist transmission system operators in maintaining the supply-demand balance. Model predictive control (MPC) strategies to exploit these implicit balancing strategies capture arbitrage opportunities, but fail to accurately capture the price-formation process in the European imbalance markets and face high computational costs. Model-free reinforcement learning (RL) methods are fast to execute, but require data-intensive training and usually rely on real-time and historical data for decision-making. This paper proposes an MPC-guided RL method that combines the complementary strengths of both MPC and RL. The proposed method can effectively incorporate forecasts into the decision-making process (as in MPC), while maintaining the fast inference capability of RL. The performance of the proposed method is evaluated on the implicit balancing battery control problem using Belgian balancing data from 2023. First, we analyze the performance of the standalone state-of-the-art RL and MPC methods from various angles, to highlight their individual strengths and limitations. Next, we show an arbitrage profit benefit of the proposed MPC-guided RL method of 16.15% and 54.36%, compared to standalone RL and MPC.
Efficient Text Encoders for Labor Market Analysis
May 30, 2025Labor market analysis relies on extracting insights from job advertisements, which provide valuable yet unstructured information on job titles and corresponding skill requirements. While state-of-the-art methods for skill extraction achieve strong performance, they depend on large language models (LLMs), which are computationally expensive and slow. In this paper, we propose \textbf{ConTeXT-match}, a novel contrastive learning approach with token-level attention that is well-suited for the extreme multi-label classification task of skill classification. \textbf{ConTeXT-match} significantly improves skill extraction efficiency and performance, achieving state-of-the-art results with a lightweight bi-encoder model. To support robust evaluation, we introduce \textbf{Skill-XL}, a new benchmark with exhaustive, sentence-level skill annotations that explicitly address the redundancy in the large label space. Finally, we present \textbf{JobBERT V2}, an improved job title normalization model that leverages extracted skills to produce high-quality job title representations. Experiments demonstrate that our models are efficient, accurate, and scalable, making them ideal for large-scale, real-time labor market analysis.
Single- vs. Dual-Prompt Dialogue Generation with LLMs for Job Interviews in Human Resources
Feb 25, 2025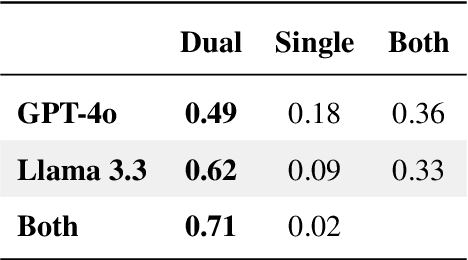
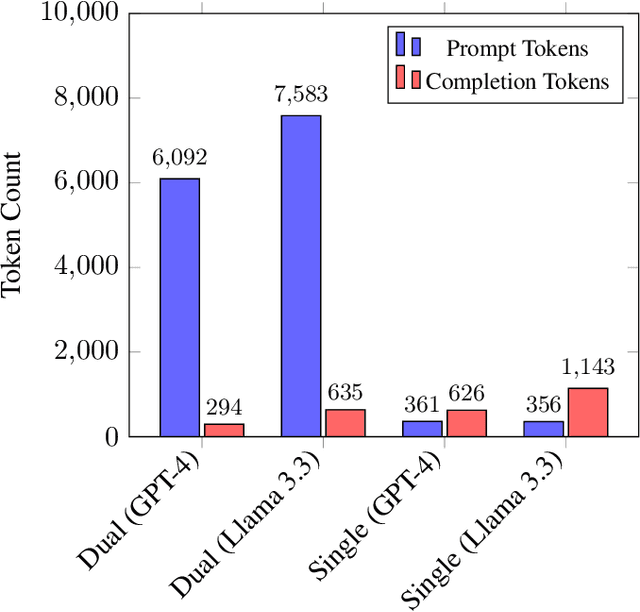
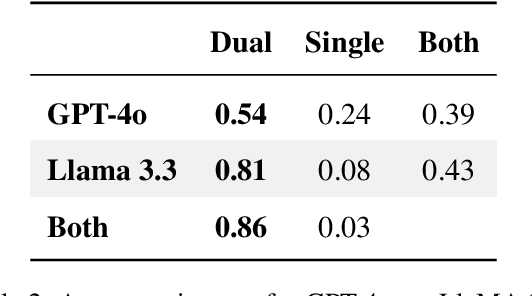
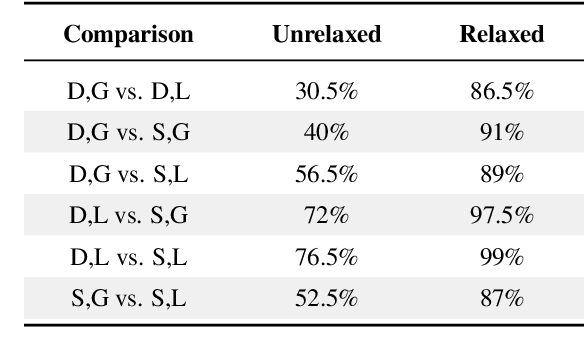
Optimizing language models for use in conversational agents requires large quantities of example dialogues. Increasingly, these dialogues are synthetically generated by using powerful large language models (LLMs), especially in domains with challenges to obtain authentic human data. One such domain is human resources (HR). In this context, we compare two LLM-based dialogue generation methods for the use case of generating HR job interviews, and assess whether one method generates higher-quality dialogues that are more challenging to distinguish from genuine human discourse. The first method uses a single prompt to generate the complete interview dialog. The second method uses two agents that converse with each other. To evaluate dialogue quality under each method, we ask a judge LLM to determine whether AI was used for interview generation, using pairwise interview comparisons. We demonstrate that despite a sixfold increase in token cost, interviews generated with the dual-prompt method achieve a win rate up to ten times higher than those generated with the single-prompt method. This difference remains consistent regardless of whether GPT-4o or Llama 3.3 70B is used for either interview generation or judging quality.
Predicting and Publishing Accurate Imbalance Prices Using Monte Carlo Tree Search
Nov 06, 2024The growing reliance on renewable energy sources, particularly solar and wind, has introduced challenges due to their uncontrollable production. This complicates maintaining the electrical grid balance, prompting some transmission system operators in Western Europe to implement imbalance tariffs that penalize unsustainable power deviations. These tariffs create an implicit demand response framework to mitigate grid instability. Yet, several challenges limit active participation. In Belgium, for example, imbalance prices are only calculated at the end of each 15-minute settlement period, creating high risk due to price uncertainty. This risk is further amplified by the inherent volatility of imbalance prices, discouraging participation. Although transmission system operators provide minute-based price predictions, the system imbalance volatility makes accurate price predictions challenging to obtain and requires sophisticated techniques. Moreover, publishing price estimates can prompt participants to adjust their schedules, potentially affecting the system balance and the final price, adding further complexity. To address these challenges, we propose a Monte Carlo Tree Search method that publishes accurate imbalance prices while accounting for potential response actions. Our approach models the system dynamics using a neural network forecaster and a cluster of virtual batteries controlled by reinforcement learning agents. Compared to Belgium's current publication method, our technique improves price accuracy by 20.4% under ideal conditions and by 12.8% in more realistic scenarios. This research addresses an unexplored, yet crucial problem, positioning this paper as a pioneering work in analyzing the potential of more advanced imbalance price publishing techniques.
SkillMatch: Evaluating Self-supervised Learning of Skill Relatedness
Oct 07, 2024


Accurately modeling the relationships between skills is a crucial part of human resources processes such as recruitment and employee development. Yet, no benchmarks exist to evaluate such methods directly. We construct and release SkillMatch, a benchmark for the task of skill relatedness, based on expert knowledge mining from millions of job ads. Additionally, we propose a scalable self-supervised learning technique to adapt a Sentence-BERT model based on skill co-occurrence in job ads. This new method greatly surpasses traditional models for skill relatedness as measured on SkillMatch. By releasing SkillMatch publicly, we aim to contribute a foundation for research towards increased accuracy and transparency of skill-based recommendation systems.
On the Biased Assessment of Expert Finding Systems
Oct 07, 2024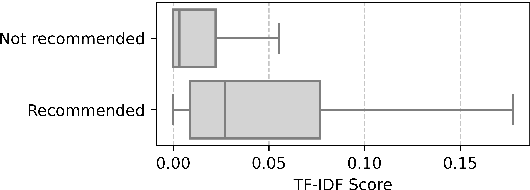

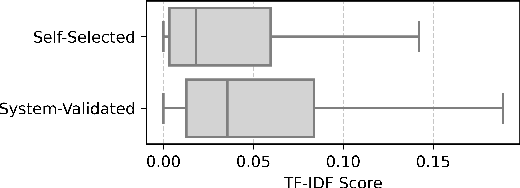
In large organisations, identifying experts on a given topic is crucial in leveraging the internal knowledge spread across teams and departments. So-called enterprise expert retrieval systems automatically discover and structure employees' expertise based on the vast amount of heterogeneous data available about them and the work they perform. Evaluating these systems requires comprehensive ground truth expert annotations, which are hard to obtain. Therefore, the annotation process typically relies on automated recommendations of knowledge areas to validate. This case study provides an analysis of how these recommendations can impact the evaluation of expert finding systems. We demonstrate on a popular benchmark that system-validated annotations lead to overestimated performance of traditional term-based retrieval models and even invalidate comparisons with more recent neural methods. We also augment knowledge areas with synonyms to uncover a strong bias towards literal mentions of their constituent words. Finally, we propose constraints to the annotation process to prevent these biased evaluations, and show that this still allows annotation suggestions of high utility. These findings should inform benchmark creation or selection for expert finding, to guarantee meaningful comparison of methods.