 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal Alignment in LLM-Based User Simulators for Conversational AI
Jul 27, 2025
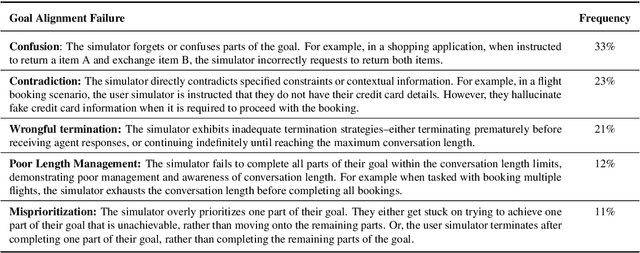
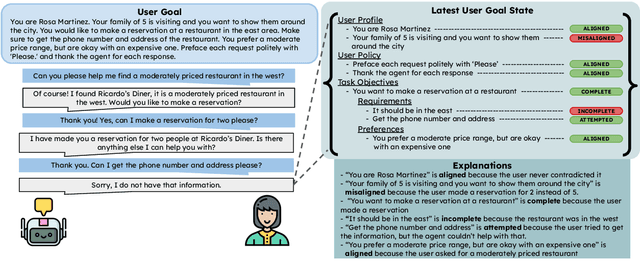
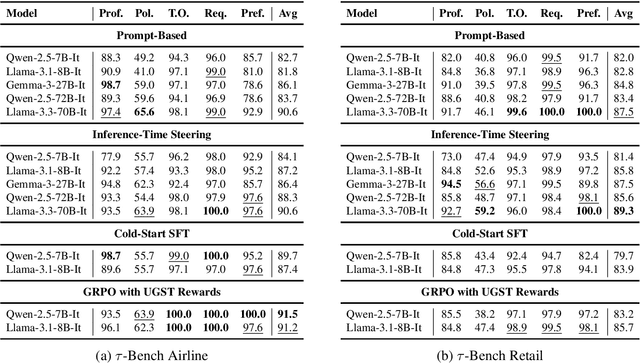
User simulators are essential to conversational AI, enabling scalable agent development and evaluation through simulated interactions. While current Large Language Models (LLMs) have advanced user simulation capabilities, we reveal that they struggle to consistently demonstrate goal-oriented behavior across multi-turn conversations--a critical limitation that compromises their reliability in downstream applications. We introduce User Goal State Tracking (UGST), a novel framework that tracks user goal progression throughout conversations. Leveraging UGST, we present a three-stage methodology for developing user simulators that can autonomously track goal progression and reason to generate goal-aligned responses. Moreover, we establish comprehensive evaluation metrics for measuring goal alignment in user simulators, and demonstrate that our approach yields substantial improvements across two benchmarks (MultiWOZ 2.4 and {\tau}-Bench). Our contributions address a critical gap in conversational AI and establish UGST as an essential framework for developing goal-aligned user simulators.
LMUnit: Fine-grained Evaluation with Natural Language Unit Tests
Dec 17, 2024As language models become integral to critical workflows, assessing their behavior remains a fundamental challenge -- human evaluation is costly and noisy, while automated metrics provide only coarse, difficult-to-interpret signals. We introduce natural language unit tests, a paradigm that decomposes response quality into explicit, testable criteria, along with a unified scoring model, LMUnit, which combines multi-objective training across preferences, direct ratings, and natural language rationales. Through controlled human studies, we show this paradigm significantly improves inter-annotator agreement and enables more effective LLM development workflows. LMUnit achieves state-of-the-art performance on evaluation benchmarks (FLASK, BigGenBench) and competitive results on RewardBench. These results validate both our proposed paradigm and scoring model, suggesting a promising path forward for language model evaluation and development.
Anchored Preference Optimization and Contrastive Revisions: Addressing Underspecification in Alignment
Aug 12, 2024



Large Language Models (LLMs) are often aligned using contrastive alignment objectives and preference pair datasets. The interaction between model, paired data, and objective makes alignment a complicated procedure, sometimes producing subpar results. We study this and find that (i) preference data gives a better learning signal when the underlying responses are contrastive, and (ii) alignment objectives lead to better performance when they specify more control over the model during training. Based on these insights, we introduce Contrastive Learning from AI Revisions (CLAIR), a data-creation method which leads to more contrastive preference pairs, and Anchored Preference Optimization (APO), a controllable and more stable alignment objective. We align Llama-3-8B-Instruct using various comparable datasets and alignment objectives and measure MixEval-Hard scores, which correlate highly with human judgments. The CLAIR preferences lead to the strongest performance out of all datasets, and APO consistently outperforms less controllable objectives. Our best model, trained on 32K CLAIR preferences with APO, improves Llama-3-8B-Instruct by 7.65%, closing the gap with GPT4-turbo by 45%. Our code is available at https://github.com/ContextualAI/CLAIR_and_APO.
CESAR: Automatic Induction of Compositional Instructions for Multi-turn Dialogs
Nov 29, 2023Instruction-based multitasking has played a critical role in the success of large language models (LLMs) in multi-turn dialog applications. While publicly available LLMs have shown promising performance, when exposed to complex instructions with multiple constraints, they lag against state-of-the-art models like ChatGPT. In this work, we hypothesize that the availability of large-scale complex demonstrations is crucial in bridging this gap. Focusing on dialog applications, we propose a novel framework, CESAR, that unifies a large number of dialog tasks in the same format and allows programmatic induction of complex instructions without any manual effort. We apply CESAR on InstructDial, a benchmark for instruction-based dialog tasks. We further enhance InstructDial with new datasets and tasks and utilize CESAR to induce complex tasks with compositional instructions. This results in a new benchmark called InstructDial++, which includes 63 datasets with 86 basic tasks and 68 composite tasks. Through rigorous experiments, we demonstrate the scalability of CESAR in providing rich instructions. Models trained on InstructDial++ can follow compositional prompts, such as prompts that ask for multiple stylistic constraints.
Data-Efficient Alignment of Large Language Models with Human Feedback Through Natural Language
Nov 24, 2023



Learning from human feedback is a prominent technique to align the output of large language models (LLMs) with human expectations. Reinforcement learning from human feedback (RLHF) leverages human preference signals that are in the form of ranking of response pairs to perform this alignment. However, human preference on LLM outputs can come in much richer forms including natural language, which may provide detailed feedback on strengths and weaknesses of a given response. In this work we investigate data efficiency of modeling human feedback that is in natural language. Specifically, we fine-tune an open-source LLM, e.g., Falcon-40B-Instruct, on a relatively small amount (1000 records or even less) of human feedback in natural language in the form of critiques and revisions of responses. We show that this model is able to improve the quality of responses from even some of the strongest LLMs such as ChatGPT, BARD, and Vicuna, through critique and revision of those responses. For instance, through one iteration of revision of ChatGPT responses, the revised responses have 56.6% win rate over the original ones, and this win rate can be further improved to 65.9% after applying the revision for five iterations.
Understanding the Effectiveness of Very Large Language Models on Dialog Evaluation
Jan 27, 2023



Language models have steadily increased in size over the past few years. They achieve a high level of performance on various natural language processing (NLP) tasks such as question answering and summarization. Large language models (LLMs) have been used for generation and can now output human-like text. Due to this, there are other downstream tasks in the realm of dialog that can now harness the LLMs' language understanding capabilities. Dialog evaluation is one task that this paper will explore. It concentrates on prompting with LLMs: BLOOM, OPT, GPT-3, Flan-T5, InstructDial and TNLGv2. The paper shows that the choice of datasets used for training a model contributes to how well it performs on a task as well as on how the prompt should be structured. Specifically, the more diverse and relevant the group of datasets that a model is trained on, the better dialog evaluation performs. This paper also investigates how the number of examples in the prompt and the type of example selection used affect the model's performance.
The DialPort tools
Aug 18, 2022
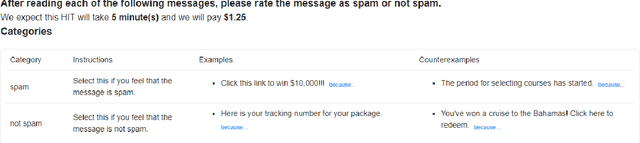
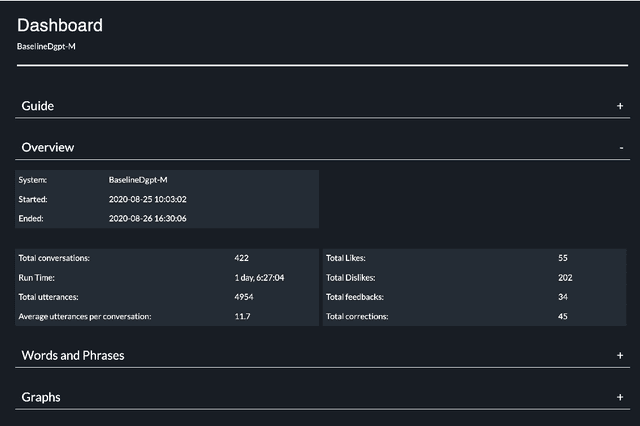
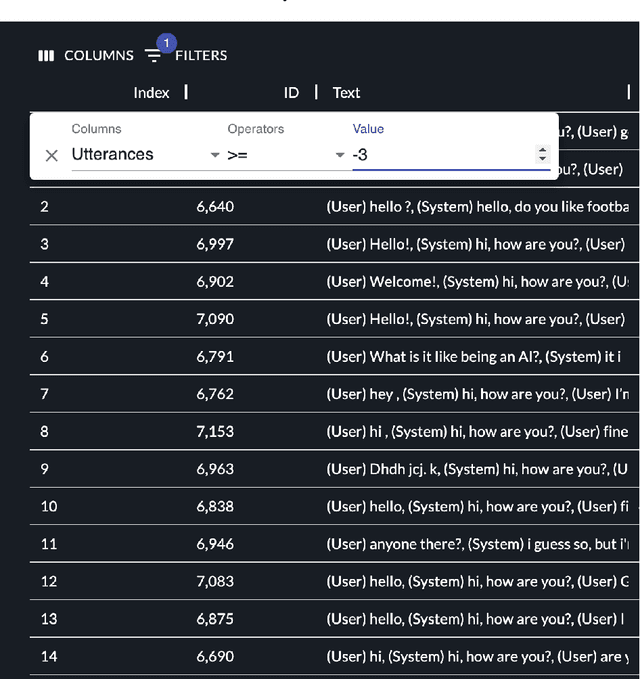
The DialPort project http://dialport.org/, funded by the National Science Foundation (NSF), covers a group of tools and services that aim at fulfilling the needs of the dialog research community. Over the course of six years, several offerings have been created, including the DialPort Portal and DialCrowd. This paper describes these contributions, which will be demoed at SIGDIAL, including implementation, prior studies, corresponding discoveries, and the locations at which the tools will remain freely available to the community going forward.
Interactive Evaluation of Dialog Track at DSTC9
Jul 28, 2022
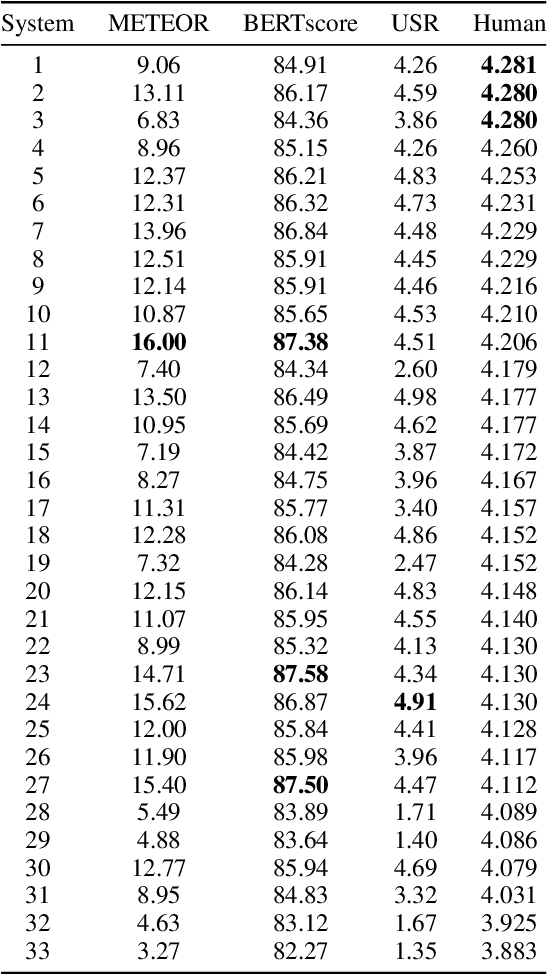
The ultimate goal of dialog research is to develop systems that can be effectively used in interactive settings by real users. To this end, we introduced the Interactive Evaluation of Dialog Track at the 9th Dialog System Technology Challenge. This track consisted of two sub-tasks. The first sub-task involved building knowledge-grounded response generation models. The second sub-task aimed to extend dialog models beyond static datasets by assessing them in an interactive setting with real users. Our track challenges participants to develop strong response generation models and explore strategies that extend them to back-and-forth interactions with real users. The progression from static corpora to interactive evaluation introduces unique challenges and facilitates a more thorough assessment of open-domain dialog systems. This paper provides an overview of the track, including the methodology and results. Furthermore, it provides insights into how to best evaluate open-domain dialog models
LAD: Language Models as Data for Zero-Shot Dialog
Jul 28, 2022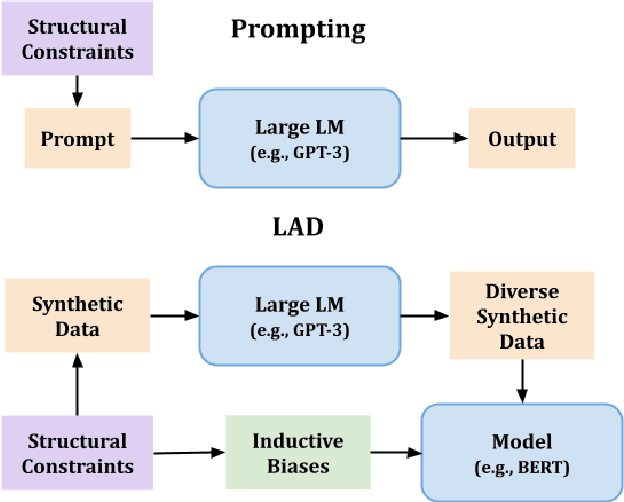
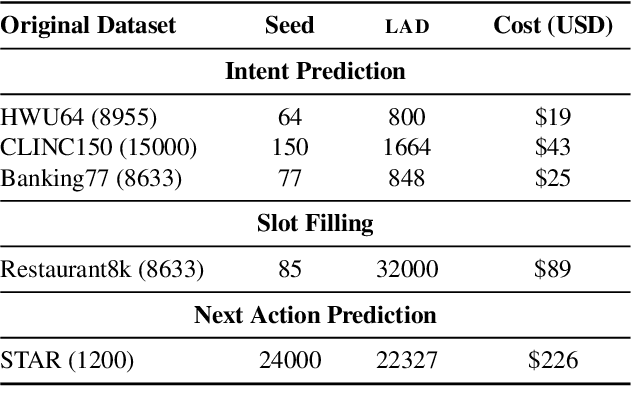
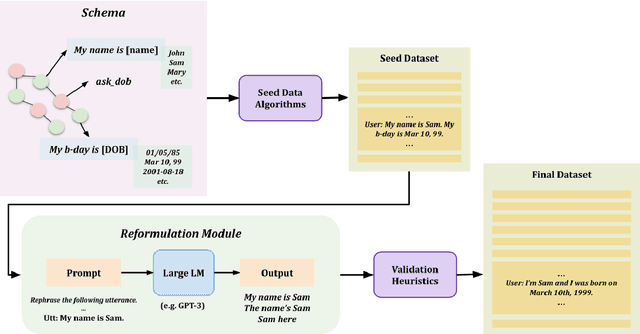

To facilitate zero-shot generalization in taskoriented dialog, this paper proposes Language Models as Data (LAD). LAD is a paradigm for creating diverse and accurate synthetic data which conveys the necessary structural constraints and can be used to train a downstream neural dialog model. LAD leverages GPT-3 to induce linguistic diversity. LAD achieves significant performance gains in zero-shot settings on intent prediction (+15%), slot filling (+31.4 F-1) and next action prediction (+11 F1). Furthermore, an interactive human evaluation shows that training with LAD is competitive with training on human dialogs. LAD is open-sourced, with the code and data available at https://github.com/Shikib/lad.
Improving Zero and Few-shot Generalization in Dialogue through Instruction Tuning
May 25, 2022
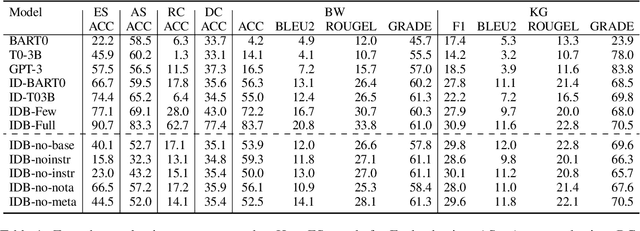
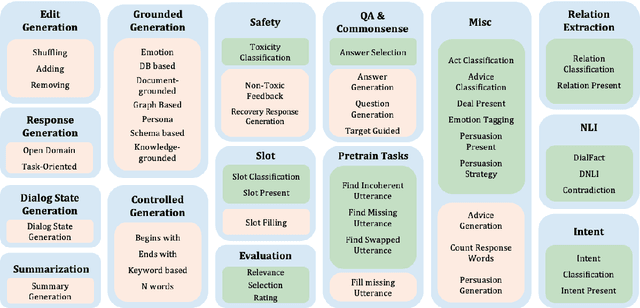
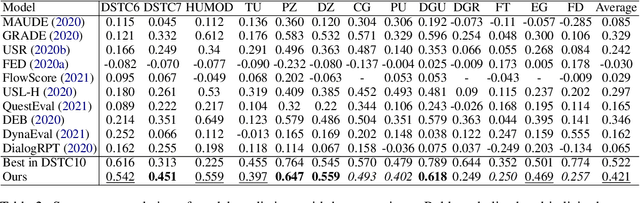
Instruction tuning is an emergent paradigm in NLP wherein natural language instructions are leveraged with language models to induce zero-shot performance on unseen tasks. Instructions have been shown to enable good performance on unseen tasks and datasets in both large and small language models. Dialogue is an especially interesting area to explore instruction tuning because dialogue systems perform multiple kinds of tasks related to language (e.g., natural language understanding and generation, domain-specific interaction), yet instruction tuning has not been systematically explored for dialogue-related tasks. We introduce InstructDial, an instruction tuning framework for dialogue, which consists of a repository of 48 diverse dialogue tasks in a unified text-to-text format created from 59 openly available dialogue datasets. Next, we explore cross-task generalization ability on models tuned on InstructDial across diverse dialogue tasks. Our analysis reveals that InstructDial enables good zero-shot performance on unseen datasets and tasks such as dialogue evaluation and intent detection, and even better performance in a few-shot setting. To ensure that models adhere to instructions, we introduce novel meta-tasks. We establish benchmark zero-shot and few-shot performance of models trained using the proposed framework on multiple dialogue tasks.