 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRACE: Capability-Targeted Agentic Training
Apr 07, 2026Large Language Models (LLMs) deployed in agentic environments must exercise multiple capabilities across different task instances, where a capability is performing one or more actions in a trajectory that are necessary for successfully solving a subset of tasks in the environment. Many existing approaches either rely on synthetic training data that is not targeted to the model's actual capability deficits in the target environment or train directly on the target environment, where the model needs to implicitly learn the capabilities across tasks. We introduce TRACE (Turning Recurrent Agent failures into Capability-targeted training Environments), an end-to-end system for environment-specific agent self-improvement. TRACE contrasts successful and failed trajectories to automatically identify lacking capabilities, synthesizes a targeted training environment for each that rewards whether the capability was exercised, and trains a LoRA adapter via RL on each synthetic environment, routing to the relevant adapter at inference. Empirically, TRACE generalizes across different environments, improving over the base agent by +14.1 points on $τ^2$-bench (customer service) and +7 perfect scores on ToolSandbox (tool use), outperforming the strongest baseline by +7.4 points and +4 perfect scores, respectively. Given the same number of rollouts, TRACE scales more efficiently than baselines, outperforming GRPO and GEPA by +9.2 and +7.4 points on $τ^2$-bench.
Intelligence per Watt: Measuring Intelligence Efficiency of Local AI
Nov 14, 2025Large language model (LLM) queries are predominantly processed by frontier models in centralized cloud infrastructure. Rapidly growing demand strains this paradigm, and cloud providers struggle to scale infrastructure at pace. Two advances enable us to rethink this paradigm: small LMs (<=20B active parameters) now achieve competitive performance to frontier models on many tasks, and local accelerators (e.g., Apple M4 Max) run these models at interactive latencies. This raises the question: can local inference viably redistribute demand from centralized infrastructure? Answering this requires measuring whether local LMs can accurately answer real-world queries and whether they can do so efficiently enough to be practical on power-constrained devices (i.e., laptops). We propose intelligence per watt (IPW), task accuracy divided by unit of power, as a metric for assessing capability and efficiency of local inference across model-accelerator pairs. We conduct a large-scale empirical study across 20+ state-of-the-art local LMs, 8 accelerators, and a representative subset of LLM traffic: 1M real-world single-turn chat and reasoning queries. For each query, we measure accuracy, energy, latency, and power. Our analysis reveals $3$ findings. First, local LMs can accurately answer 88.7% of single-turn chat and reasoning queries with accuracy varying by domain. Second, from 2023-2025, IPW improved 5.3x and local query coverage rose from 23.2% to 71.3%. Third, local accelerators achieve at least 1.4x lower IPW than cloud accelerators running identical models, revealing significant headroom for optimization. These findings demonstrate that local inference can meaningfully redistribute demand from centralized infrastructure, with IPW serving as the critical metric for tracking this transition. We release our IPW profiling harness for systematic intelligence-per-watt benchmarking.
OpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
Think Deep, Think Fast: Investigating Efficiency of Verifier-free Inference-time-scaling Methods
Apr 18, 2025There is intense interest in investigating how inference time compute (ITC) (e.g. repeated sampling, refinements, etc) can improve large language model (LLM) capabilities. At the same time, recent breakthroughs in reasoning models, such as Deepseek-R1, unlock the opportunity for reinforcement learning to improve LLM reasoning skills. An in-depth understanding of how ITC interacts with reasoning across different models could provide important guidance on how to further advance the LLM frontier. This work conducts a comprehensive analysis of inference-time scaling methods for both reasoning and non-reasoning models on challenging reasoning tasks. Specifically, we focus our research on verifier-free inference time-scaling methods due to its generalizability without needing a reward model. We construct the Pareto frontier of quality and efficiency. We find that non-reasoning models, even with an extremely high inference budget, still fall substantially behind reasoning models. For reasoning models, majority voting proves to be a robust inference strategy, generally competitive or outperforming other more sophisticated ITC methods like best-of-N and sequential revisions, while the additional inference compute offers minimal improvements. We further perform in-depth analyses of the association of key response features (length and linguistic markers) with response quality, with which we can improve the existing ITC methods. We find that correct responses from reasoning models are typically shorter and have fewer hedging and thinking markers (but more discourse markers) than the incorrect responses.
LMUnit: Fine-grained Evaluation with Natural Language Unit Tests
Dec 17, 2024As language models become integral to critical workflows, assessing their behavior remains a fundamental challenge -- human evaluation is costly and noisy, while automated metrics provide only coarse, difficult-to-interpret signals. We introduce natural language unit tests, a paradigm that decomposes response quality into explicit, testable criteria, along with a unified scoring model, LMUnit, which combines multi-objective training across preferences, direct ratings, and natural language rationales. Through controlled human studies, we show this paradigm significantly improves inter-annotator agreement and enables more effective LLM development workflows. LMUnit achieves state-of-the-art performance on evaluation benchmarks (FLASK, BigGenBench) and competitive results on RewardBench. These results validate both our proposed paradigm and scoring model, suggesting a promising path forward for language model evaluation and development.
Benchmarking and Building Long-Context Retrieval Models with LoCo and M2-BERT
Feb 14, 2024Retrieval pipelines-an integral component of many machine learning systems-perform poorly in domains where documents are long (e.g., 10K tokens or more) and where identifying the relevant document requires synthesizing information across the entire text. Developing long-context retrieval encoders suitable for these domains raises three challenges: (1) how to evaluate long-context retrieval performance, (2) how to pretrain a base language model to represent both short contexts (corresponding to queries) and long contexts (corresponding to documents), and (3) how to fine-tune this model for retrieval under the batch size limitations imposed by GPU memory constraints. To address these challenges, we first introduce LoCoV1, a novel 12 task benchmark constructed to measure long-context retrieval where chunking is not possible or not effective. We next present the M2-BERT retrieval encoder, an 80M parameter state-space encoder model built from the Monarch Mixer architecture, capable of scaling to documents up to 32K tokens long. We describe a pretraining data mixture which allows this encoder to process both short and long context sequences, and a finetuning approach that adapts this base model to retrieval with only single-sample batches. Finally, we validate the M2-BERT retrieval encoder on LoCoV1, finding that it outperforms competitive Transformer-based models by at least 23.3 points, despite containing upwards of 90x fewer parameters.
ARES: An Automated Evaluation Framework for Retrieval-Augmented Generation Systems
Nov 16, 2023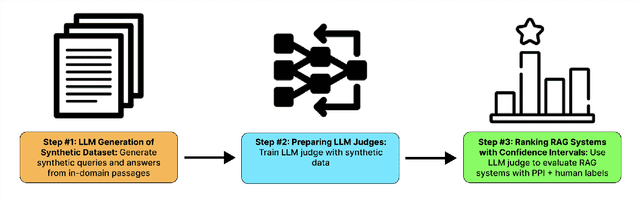
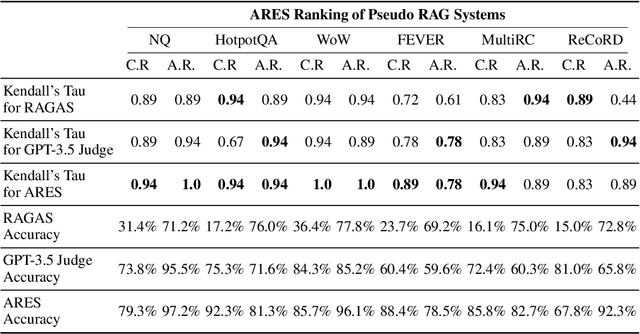
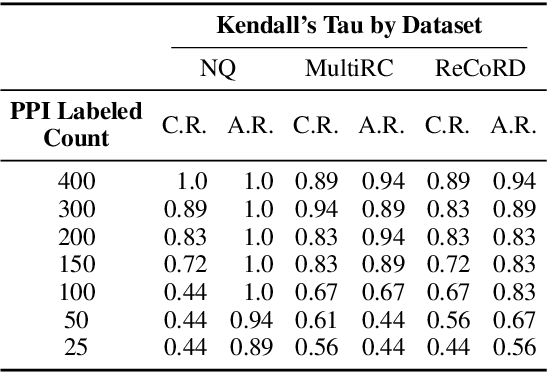
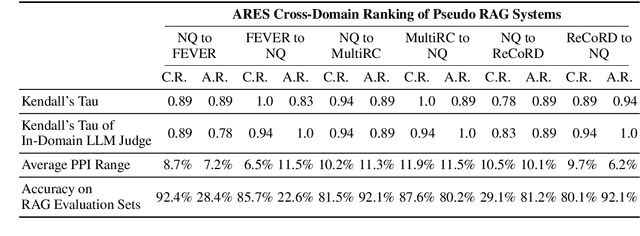
Evaluating retrieval-augmented generation (RAG) systems traditionally relies on hand annotations for input queries, passages to retrieve, and responses to generate. We introduce ARES, an Automated RAG Evaluation System, for evaluating RAG systems along the dimensions of context relevance, answer faithfulness, and answer relevance. Using synthetic training data, ARES finetunes lightweight LM judges to assess the quality of individual RAG components. To mitigate potential prediction errors, ARES utilizes a small set of human-annotated datapoints for prediction-powered inference (PPI). Across six different knowledge-intensive tasks in KILT and SuperGLUE, ARES accurately evaluates RAG systems while using a few hundred human annotations during evaluation. Furthermore, ARES judges remain effective across domain shifts, proving accurate even after changing the type of queries and/or documents used in the evaluated RAG systems. We make our datasets and code for replication and deployment available at https://github.com/stanford-futuredata/ARES.
PDFTriage: Question Answering over Long, Structured Documents
Sep 16, 2023



Large Language Models (LLMs) have issues with document question answering (QA) in situations where the document is unable to fit in the small context length of an LLM. To overcome this issue, most existing works focus on retrieving the relevant context from the document, representing them as plain text. However, documents such as PDFs, web pages, and presentations are naturally structured with different pages, tables, sections, and so on. Representing such structured documents as plain text is incongruous with the user's mental model of these documents with rich structure. When a system has to query the document for context, this incongruity is brought to the fore, and seemingly trivial questions can trip up the QA system. To bridge this fundamental gap in handling structured documents, we propose an approach called PDFTriage that enables models to retrieve the context based on either structure or content. Our experiments demonstrate the effectiveness of the proposed PDFTriage-augmented models across several classes of questions where existing retrieval-augmented LLMs fail. To facilitate further research on this fundamental problem, we release our benchmark dataset consisting of 900+ human-generated questions over 80 structured documents from 10 different categories of question types for document QA.
UDAPDR: Unsupervised Domain Adaptation via LLM Prompting and Distillation of Rerankers
Mar 01, 2023



Many information retrieval tasks require large labeled datasets for fine-tuning. However, such datasets are often unavailable, and their utility for real-world applications can diminish quickly due to domain shifts. To address this challenge, we develop and motivate a method for using large language models (LLMs) to generate large numbers of synthetic queries cheaply. The method begins by generating a small number of synthetic queries using an expensive LLM. After that, a much less expensive one is used to create large numbers of synthetic queries, which are used to fine-tune a family of reranker models. These rerankers are then distilled into a single efficient retriever for use in the target domain. We show that this technique boosts zero-shot accuracy in long-tail domains, even where only 2K synthetic queries are used for fine-tuning, and that it achieves substantially lower latency than standard reranking methods. We make our end-to-end approach, including our synthetic datasets and replication code, publicly available on Github.
Moving Beyond Downstream Task Accuracy for Information Retrieval Benchmarking
Dec 02, 2022



Neural information retrieval (IR) systems have progressed rapidly in recent years, in large part due to the release of publicly available benchmarking tasks. Unfortunately, some dimensions of this progress are illusory: the majority of the popular IR benchmarks today focus exclusively on downstream task accuracy and thus conceal the costs incurred by systems that trade away efficiency for quality. Latency, hardware cost, and other efficiency considerations are paramount to the deployment of IR systems in user-facing settings. We propose that IR benchmarks structure their evaluation methodology to include not only metrics of accuracy, but also efficiency considerations such as a query latency and the corresponding cost budget for a reproducible hardware setting. For the popular IR benchmarks MS MARCO and XOR-TyDi, we show how the best choice of IR system varies according to how these efficiency considerations are chosen and weighed. We hope that future benchmarks will adopt these guidelines toward more holistic IR evaluation.