 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
ChartMuseum: Testing Visual Reasoning Capabilities of Large Vision-Language Models
May 19, 2025Chart understanding presents a unique challenge for large vision-language models (LVLMs), as it requires the integration of sophisticated textual and visual reasoning capabilities. However, current LVLMs exhibit a notable imbalance between these skills, falling short on visual reasoning that is difficult to perform in text. We conduct a case study using a synthetic dataset solvable only through visual reasoning and show that model performance degrades significantly with increasing visual complexity, while human performance remains robust. We then introduce ChartMuseum, a new Chart Question Answering (QA) benchmark containing 1,162 expert-annotated questions spanning multiple reasoning types, curated from real-world charts across 184 sources, specifically built to evaluate complex visual and textual reasoning. Unlike prior chart understanding benchmarks -- where frontier models perform similarly and near saturation -- our benchmark exposes a substantial gap between model and human performance, while effectively differentiating model capabilities: although humans achieve 93% accuracy, the best-performing model Gemini-2.5-Pro attains only 63.0%, and the leading open-source LVLM Qwen2.5-VL-72B-Instruct achieves only 38.5%. Moreover, on questions requiring primarily visual reasoning, all models experience a 35%-55% performance drop from text-reasoning-heavy question performance. Lastly, our qualitative error analysis reveals specific categories of visual reasoning that are challenging for current LVLMs.
EvalAgent: Discovering Implicit Evaluation Criteria from the Web
Apr 21, 2025Evaluation of language model outputs on structured writing tasks is typically conducted with a number of desirable criteria presented to human evaluators or large language models (LLMs). For instance, on a prompt like "Help me draft an academic talk on coffee intake vs research productivity", a model response may be evaluated for criteria like accuracy and coherence. However, high-quality responses should do more than just satisfy basic task requirements. An effective response to this query should include quintessential features of an academic talk, such as a compelling opening, clear research questions, and a takeaway. To help identify these implicit criteria, we introduce EvalAgent, a novel framework designed to automatically uncover nuanced and task-specific criteria. EvalAgent first mines expert-authored online guidance. It then uses this evidence to propose diverse, long-tail evaluation criteria that are grounded in reliable external sources. Our experiments demonstrate that the grounded criteria produced by EvalAgent are often implicit (not directly stated in the user's prompt), yet specific (high degree of lexical precision). Further, EvalAgent criteria are often not satisfied by initial responses but they are actionable, such that responses can be refined to satisfy them. Finally, we show that combining LLM-generated and EvalAgent criteria uncovers more human-valued criteria than using LLMs alone.
To CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning
Sep 18, 2024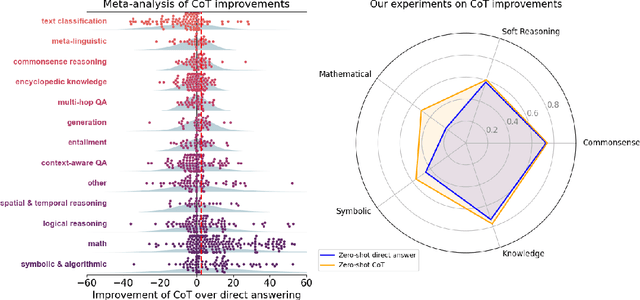


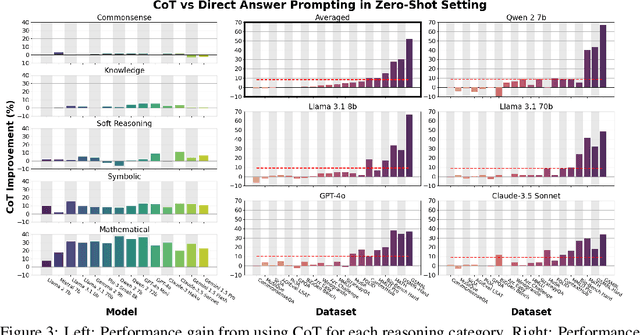
Chain-of-thought (CoT) via prompting is the de facto method for eliciting reasoning capabilities from large language models (LLMs). But for what kinds of tasks is this extra ``thinking'' really helpful? To analyze this, we conducted a quantitative meta-analysis covering over 100 papers using CoT and ran our own evaluations of 20 datasets across 14 models. Our results show that CoT gives strong performance benefits primarily on tasks involving math or logic, with much smaller gains on other types of tasks. On MMLU, directly generating the answer without CoT leads to almost identical accuracy as CoT unless the question or model's response contains an equals sign, indicating symbolic operations and reasoning. Following this finding, we analyze the behavior of CoT on these problems by separating planning and execution and comparing against tool-augmented LLMs. Much of CoT's gain comes from improving symbolic execution, but it underperforms relative to using a symbolic solver. Our results indicate that CoT can be applied selectively, maintaining performance while saving inference costs. Furthermore, they suggest a need to move beyond prompt-based CoT to new paradigms that better leverage intermediate computation across the whole range of LLM applications.
MuSR: Testing the Limits of Chain-of-thought with Multistep Soft Reasoning
Oct 24, 2023



While large language models (LLMs) equipped with techniques like chain-of-thought prompting have demonstrated impressive capabilities, they still fall short in their ability to reason robustly in complex settings. However, evaluating LLM reasoning is challenging because system capabilities continue to grow while benchmark datasets for tasks like logical deduction have remained static. We introduce MuSR, a dataset for evaluating language models on multistep soft reasoning tasks specified in a natural language narrative. This dataset has two crucial features. First, it is created through a novel neurosymbolic synthetic-to-natural generation algorithm, enabling the construction of complex reasoning instances that challenge GPT-4 (e.g., murder mysteries roughly 1000 words in length) and which can be scaled further as more capable LLMs are released. Second, our dataset instances are free text narratives corresponding to real-world domains of reasoning; this makes it simultaneously much more challenging than other synthetically-crafted benchmarks while remaining realistic and tractable for human annotators to solve with high accuracy. We evaluate a range of LLMs and prompting techniques on this dataset and characterize the gaps that remain for techniques like chain-of-thought to perform robust reasoning.
Deductive Additivity for Planning of Natural Language Proofs
Jul 06, 2023

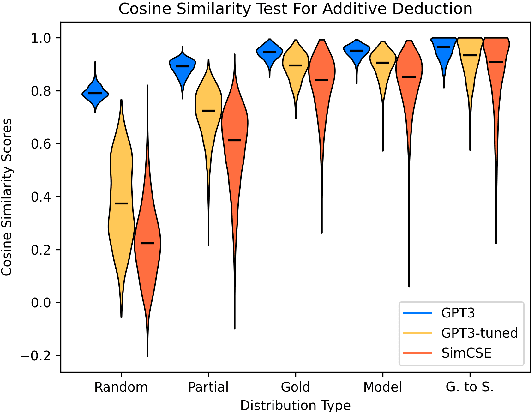
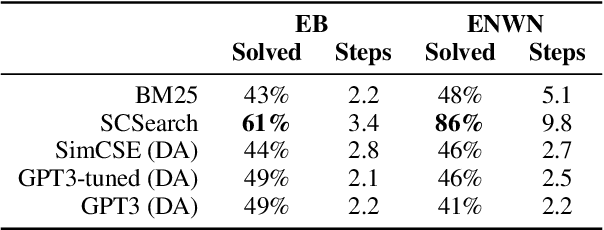
Current natural language systems designed for multi-step claim validation typically operate in two phases: retrieve a set of relevant premise statements using heuristics (planning), then generate novel conclusions from those statements using a large language model (deduction). The planning step often requires expensive Transformer operations and does not scale to arbitrary numbers of premise statements. In this paper, we investigate whether an efficient planning heuristic is possible via embedding spaces compatible with deductive reasoning. Specifically, we evaluate whether embedding spaces exhibit a property we call deductive additivity: the sum of premise statement embeddings should be close to embeddings of conclusions based on those premises. We explore multiple sources of off-the-shelf dense embeddings in addition to fine-tuned embeddings from GPT3 and sparse embeddings from BM25. We study embedding models both intrinsically, evaluating whether the property of deductive additivity holds, and extrinsically, using them to assist planning in natural language proof generation. Lastly, we create a dataset, Single-Step Reasoning Contrast (SSRC), to further probe performance on various reasoning types. Our findings suggest that while standard embedding methods frequently embed conclusions near the sums of their premises, they fall short of being effective heuristics and lack the ability to model certain categories of reasoning.
Decentralized Social Navigation with Non-Cooperative Robots via Bi-Level Optimization
Jun 15, 2023
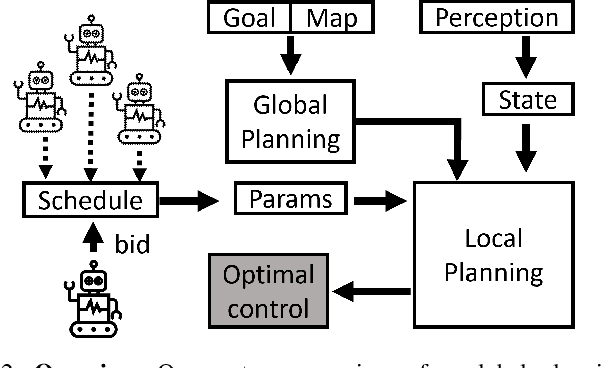
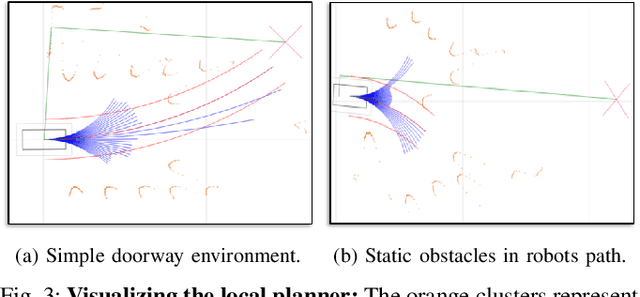
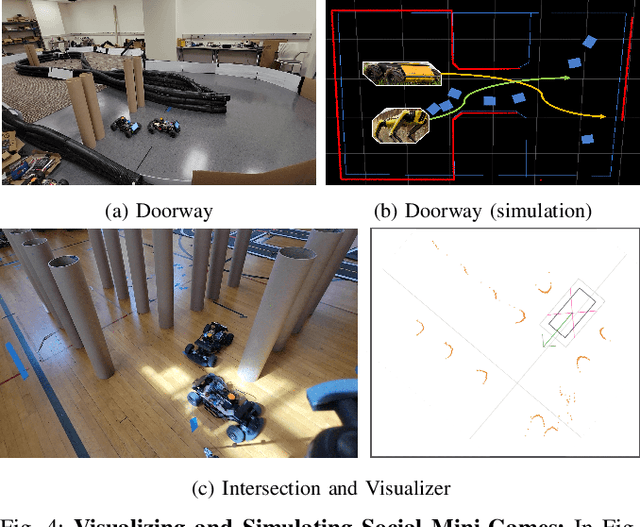
This paper presents a fully decentralized approach for realtime non-cooperative multi-robot navigation in social mini-games, such as navigating through a narrow doorway or negotiating right of way at a corridor intersection. Our contribution is a new realtime bi-level optimization algorithm, in which the top-level optimization consists of computing a fair and collision-free ordering followed by the bottom-level optimization which plans optimal trajectories conditioned on the ordering. We show that, given such a priority order, we can impose simple kinodynamic constraints on each robot that are sufficient for it to plan collision-free trajectories with minimal deviation from their preferred velocities, similar to how humans navigate in these scenarios. We successfully deploy the proposed algorithm in the real world using F$1/10$ robots, a Clearpath Jackal, and a Boston Dynamics Spot as well as in simulation using the SocialGym 2.0 multi-agent social navigation simulator, in the doorway and corridor intersection scenarios. We compare with state-of-the-art social navigation methods using multi-agent reinforcement learning, collision avoidance algorithms, and crowd simulation models. We show that $(i)$ classical navigation performs $44\%$ better than the state-of-the-art learning-based social navigation algorithms, $(ii)$ without a scheduling protocol, our approach results in collisions in social mini-games $(iii)$ our approach yields $2\times$ and $5\times$ fewer velocity changes than CADRL in doorways and intersections, and finally $(iv)$ bi-level navigation in doorways at a flow rate of $2.8 - 3.3$ (ms)$^{-1}$ is comparable to flow rate in human navigation at a flow rate of $4$ (ms)$^{-1}$.
SOCIALGYM 2.0: Simulator for Multi-Agent Social Robot Navigation in Shared Human Spaces
Mar 09, 2023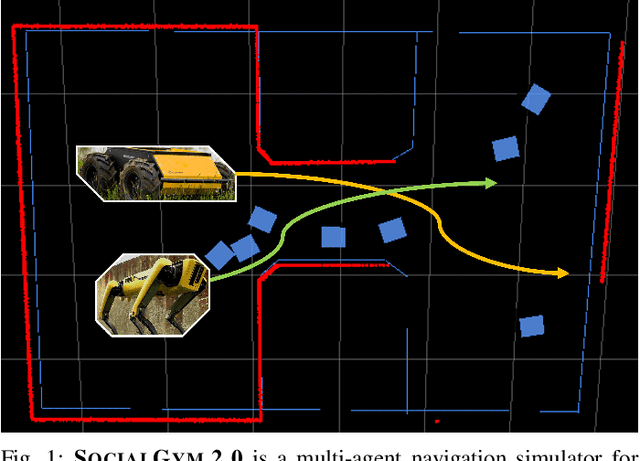
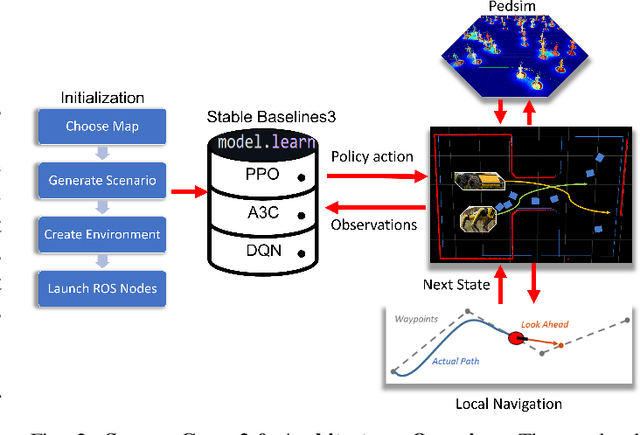
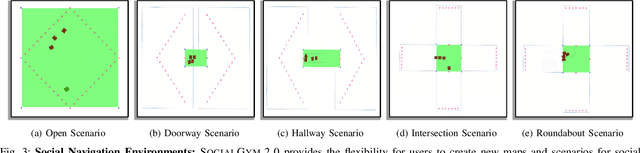
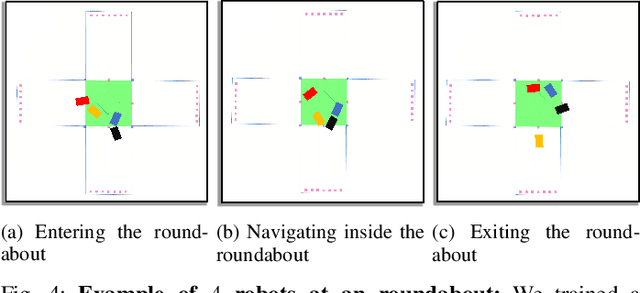
We present SocialGym 2, a multi-agent navigation simulator for social robot research. Our simulator models multiple autonomous agents, replicating real-world dynamics in complex environments, including doorways, hallways, intersections, and roundabouts. Unlike traditional simulators that concentrate on single robots with basic kinematic constraints in open spaces, SocialGym 2 employs multi-agent reinforcement learning (MARL) to develop optimal navigation policies for multiple robots with diverse, dynamic constraints in complex environments. Built on the PettingZoo MARL library and Stable Baselines3 API, SocialGym 2 offers an accessible python interface that integrates with a navigation stack through ROS messaging. SocialGym 2 can be easily installed and is packaged in a docker container, and it provides the capability to swap and evaluate different MARL algorithms, as well as customize observation and reward functions. We also provide scripts to allow users to create their own environments and have conducted benchmarks using various social navigation algorithms, reporting a broad range of social navigation metrics. Projected hosted at: https://amrl.cs.utexas.edu/social_gym/index.html
Natural Language Deduction with Incomplete Information
Nov 01, 2022



A growing body of work studies how to answer a question or verify a claim by generating a natural language "proof": a chain of deductive inferences yielding the answer based on a set of premises. However, these methods can only make sound deductions when they follow from evidence that is given. We propose a new system that can handle the underspecified setting where not all premises are stated at the outset; that is, additional assumptions need to be materialized to prove a claim. By using a natural language generation model to abductively infer a premise given another premise and a conclusion, we can impute missing pieces of evidence needed for the conclusion to be true. Our system searches over two fringes in a bidirectional fashion, interleaving deductive (forward-chaining) and abductive (backward-chaining) generation steps. We sample multiple possible outputs for each step to achieve coverage of the search space, at the same time ensuring correctness by filtering low-quality generations with a round-trip validation procedure. Results on a modified version of the EntailmentBank dataset and a new dataset called Everyday Norms: Why Not? show that abductive generation with validation can recover premises across in- and out-of-domain settings.
Natural Language Deduction through Search over Statement Compositions
Jan 16, 2022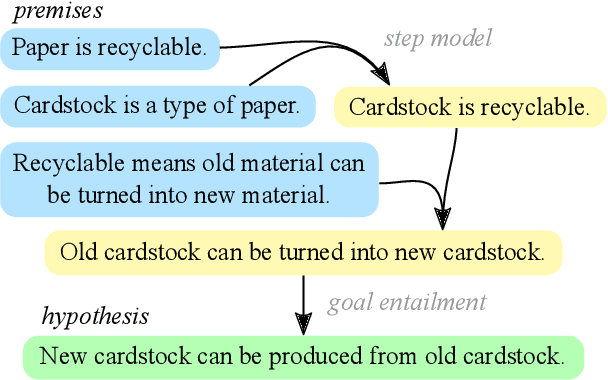

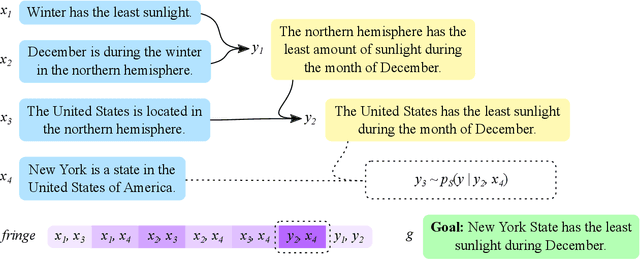
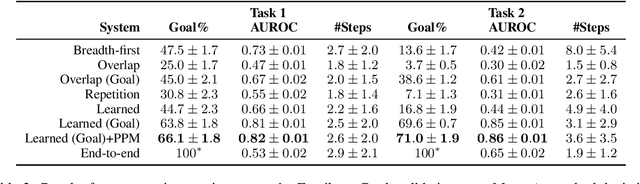
In settings from fact-checking to question answering, we frequently want to know whether a collection of evidence entails a hypothesis. Existing methods primarily focus on end-to-end discriminative versions of this task, but less work has treated the generative version in which a model searches over the space of entailed statements to derive the hypothesis. We propose a system for natural language deduction that decomposes the task into separate steps coordinated by best-first search, producing a tree of intermediate conclusions that faithfully reflects the system's reasoning process. Our experiments demonstrate that the proposed system can better distinguish verifiable hypotheses from unverifiable ones and produce natural language explanations that are more internally consistent than those produced by an end-to-end T5 model.