 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartMuseum: Testing Visual Reasoning Capabilities of Large Vision-Language Models
May 19, 2025Chart understanding presents a unique challenge for large vision-language models (LVLMs), as it requires the integration of sophisticated textual and visual reasoning capabilities. However, current LVLMs exhibit a notable imbalance between these skills, falling short on visual reasoning that is difficult to perform in text. We conduct a case study using a synthetic dataset solvable only through visual reasoning and show that model performance degrades significantly with increasing visual complexity, while human performance remains robust. We then introduce ChartMuseum, a new Chart Question Answering (QA) benchmark containing 1,162 expert-annotated questions spanning multiple reasoning types, curated from real-world charts across 184 sources, specifically built to evaluate complex visual and textual reasoning. Unlike prior chart understanding benchmarks -- where frontier models perform similarly and near saturation -- our benchmark exposes a substantial gap between model and human performance, while effectively differentiating model capabilities: although humans achieve 93% accuracy, the best-performing model Gemini-2.5-Pro attains only 63.0%, and the leading open-source LVLM Qwen2.5-VL-72B-Instruct achieves only 38.5%. Moreover, on questions requiring primarily visual reasoning, all models experience a 35%-55% performance drop from text-reasoning-heavy question performance. Lastly, our qualitative error analysis reveals specific categories of visual reasoning that are challenging for current LVLMs.
Is the Top Still Spinning? Evaluating Subjectivity in Narrative Understanding
Apr 01, 2025

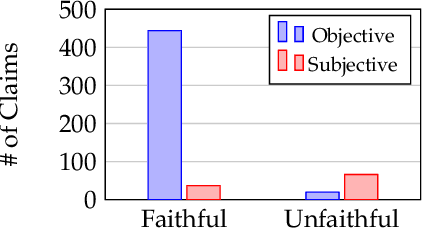
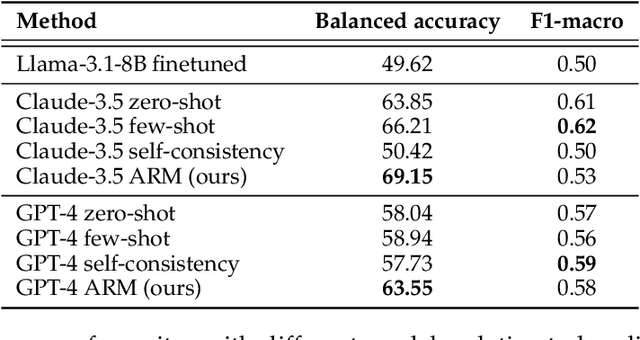
Determining faithfulness of a claim to a source document is an important problem across many domains. This task is generally treated as a binary judgment of whether the claim is supported or unsupported in relation to the source. In many cases, though, whether a claim is supported can be ambiguous. For instance, it may depend on making inferences from given evidence, and different people can reasonably interpret the claim as either supported or unsupported based on their agreement with those inferences. Forcing binary labels upon such claims lowers the reliability of evaluation. In this work, we reframe the task to manage the subjectivity involved with factuality judgments of ambiguous claims. We introduce LLM-generated edits of summaries as a method of providing a nuanced evaluation of claims: how much does a summary need to be edited to be unambiguous? Whether a claim gets rewritten and how much it changes can be used as an automatic evaluation metric, the Ambiguity Rewrite Metric (ARM), with a much richer feedback signal than a binary judgment of faithfulness. We focus on the area of narrative summarization as it is particularly rife with ambiguity and subjective interpretation. We show that ARM produces a 21% absolute improvement in annotator agreement on claim faithfulness, indicating that subjectivity is reduced.
MiniCheck: Efficient Fact-Checking of LLMs on Grounding Documents
Apr 16, 2024



Recognizing if LLM output can be grounded in evidence is central to many tasks in NLP: retrieval-augmented generation, summarization, document-grounded dialogue, and more. Current approaches to this kind of "fact-checking" are based on verifying each piece of a model generation against potential evidence using an LLM. However, this process can be very computationally expensive, requiring many calls to LLMs to check a single response. In this work, we show how to build small models that have GPT-4-level performance but for 400x lower cost. We do this by constructing synthetic training data with GPT-4, which involves creating realistic yet challenging instances of factual errors via a structured generation procedure. Training on this data teaches models to check each fact in the claim and recognize synthesis of information across sentences. For evaluation, we unify pre-existing datasets into a benchmark LLM-AggreFact, collected from recent work on fact-checking and grounding LLM generations. Our best system MiniCheck-FT5 (770M parameters) outperforms all systems of comparable size and reaches GPT-4 accuracy. We release LLM-AggreFact, code for data synthesis, and models.
TofuEval: Evaluating Hallucinations of LLMs on Topic-Focused Dialogue Summarization
Feb 20, 2024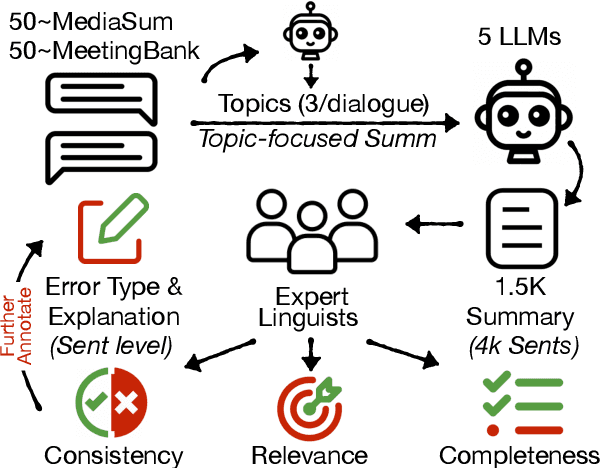


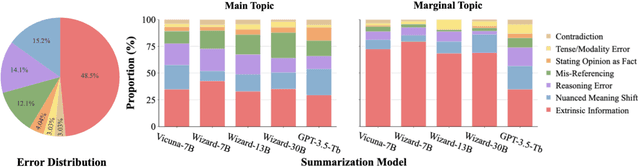
Single document news summarization has seen substantial progress on faithfulness in recent years, driven by research on the evaluation of factual consistency, or hallucinations. We ask whether these advances carry over to other text summarization domains. We propose a new evaluation benchmark on topic-focused dialogue summarization, generated by LLMs of varying sizes. We provide binary sentence-level human annotations of the factual consistency of these summaries along with detailed explanations of factually inconsistent sentences. Our analysis shows that existing LLMs hallucinate significant amounts of factual errors in the dialogue domain, regardless of the model's size. On the other hand, when LLMs, including GPT-4, serve as binary factual evaluators, they perform poorly and can be outperformed by prevailing state-of-the-art specialized factuality evaluation metrics. Finally, we conducted an analysis of hallucination types with a curated error taxonomy. We find that there are diverse errors and error distributions in model-generated summaries and that non-LLM based metrics can capture all error types better than LLM-based evaluators.
Less Likely Brainstorming: Using Language Models to Generate Alternative Hypotheses
May 30, 2023A human decision-maker benefits the most from an AI assistant that corrects for their biases. For problems such as generating interpretation of a radiology report given findings, a system predicting only highly likely outcomes may be less useful, where such outcomes are already obvious to the user. To alleviate biases in human decision-making, it is worth considering a broad differential diagnosis, going beyond the most likely options. We introduce a new task, "less likely brainstorming," that asks a model to generate outputs that humans think are relevant but less likely to happen. We explore the task in two settings: a brain MRI interpretation generation setting and an everyday commonsense reasoning setting. We found that a baseline approach of training with less likely hypotheses as targets generates outputs that humans evaluate as either likely or irrelevant nearly half of the time; standard MLE training is not effective. To tackle this problem, we propose a controlled text generation method that uses a novel contrastive learning strategy to encourage models to differentiate between generating likely and less likely outputs according to humans. We compare our method with several state-of-the-art controlled text generation models via automatic and human evaluations and show that our models' capability of generating less likely outputs is improved.
Understanding Factual Errors in Summarization: Errors, Summarizers, Datasets, Error Detectors
May 25, 2022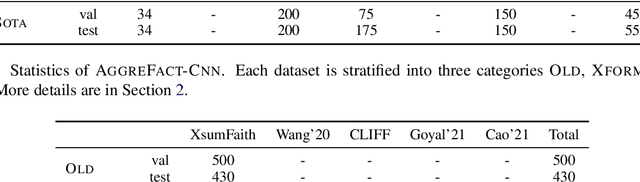
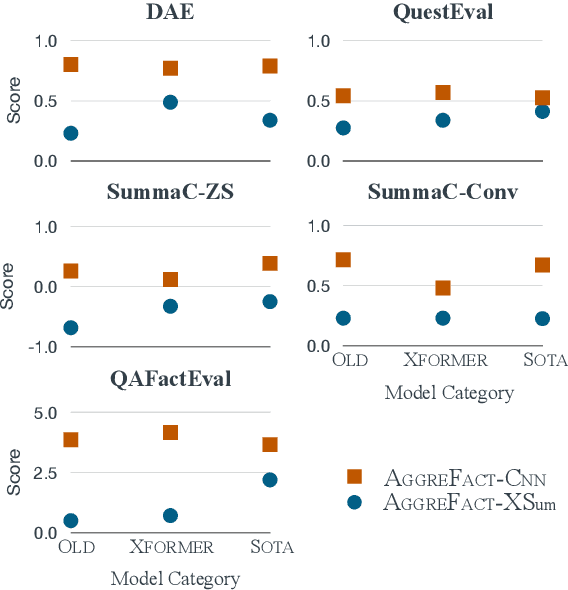
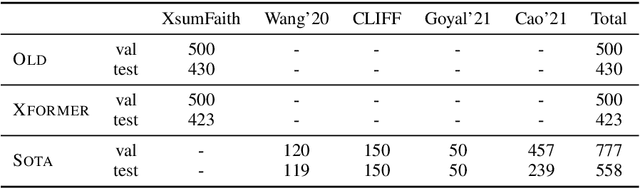
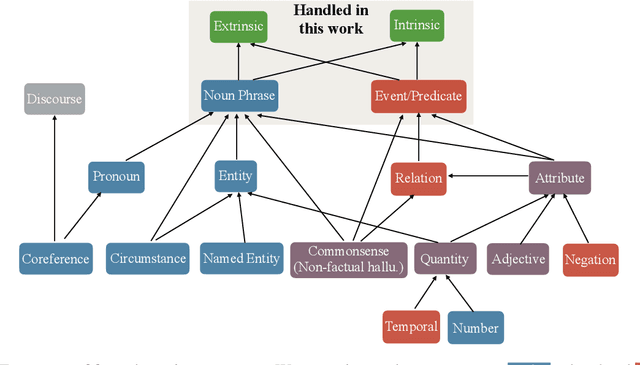
The propensity of abstractive summarization systems to make factual errors has been the subject of significant study, including work on models to detect factual errors and annotation of errors in current systems' outputs. However, the ever-evolving nature of summarization systems, error detectors, and annotated benchmarks make factuality evaluation a moving target; it is hard to get a clear picture of how techniques compare. In this work, we collect labeled factuality errors from across nine datasets of annotated summary outputs and stratify them in a new way, focusing on what kind of base summarization model was used. To support finer-grained analysis, we unify the labeled error types into a single taxonomy and project each of the datasets' errors into this shared labeled space. We then contrast five state-of-the-art error detection methods on this benchmark. Our findings show that benchmarks built on modern summary outputs (those from pre-trained models) show significantly different results than benchmarks using pre-Transformer models. Furthermore, no one factuality technique is superior in all settings or for all error types, suggesting that system developers should take care to choose the right system for their task at hand.
Prior Knowledge Enhances Radiology Report Generation
Jan 11, 2022

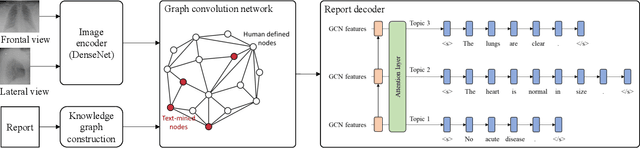

Radiology report generation aims to produce computer-aided diagnoses to alleviate the workload of radiologists and has drawn increasing attention recently. However, previous deep learning methods tend to neglect the mutual influences between medical findings, which can be the bottleneck that limits the quality of generated reports. In this work, we propose to mine and represent the associations among medical findings in an informative knowledge graph and incorporate this prior knowledge with radiology report generation to help improve the quality of generated reports. Experiment results demonstrate the superior performance of our proposed method on the IU X-ray dataset with a ROUGE-L of 0.384$\pm$0.007 and CIDEr of 0.340$\pm$0.011. Compared with previous works, our model achieves an average of 1.6% improvement (2.0% and 1.5% improvements in CIDEr and ROUGE-L, respectively). The experiments suggest that prior knowledge can bring performance gains to accurate radiology report generation. We will make the code publicly available at https://github.com/bionlplab/report_generation_amia2022.
RadBERT-CL: Factually-Aware Contrastive Learning For Radiology Report Classification
Nov 19, 2021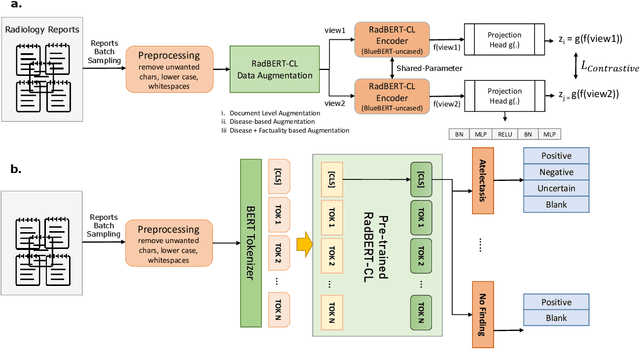
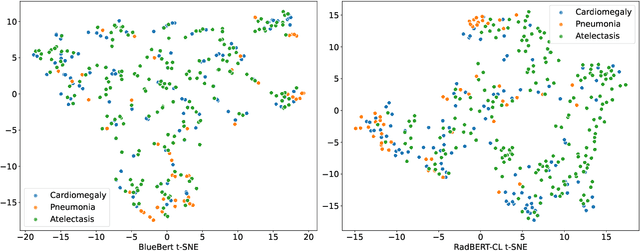

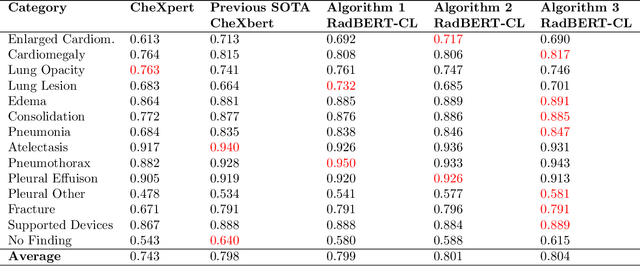
Radiology reports are unstructured and contain the imaging findings and corresponding diagnoses transcribed by radiologists which include clinical facts and negated and/or uncertain statements. Extracting pathologic findings and diagnoses from radiology reports is important for quality control, population health, and monitoring of disease progress. Existing works, primarily rely either on rule-based systems or transformer-based pre-trained model fine-tuning, but could not take the factual and uncertain information into consideration, and therefore generate false-positive outputs. In this work, we introduce three sedulous augmentation techniques which retain factual and critical information while generating augmentations for contrastive learning. We introduce RadBERT-CL, which fuses these information into BlueBert via a self-supervised contrastive loss. Our experiments on MIMIC-CXR show superior performance of RadBERT-CL on fine-tuning for multi-class, multi-label report classification. We illustrate that when few labeled data are available, RadBERT-CL outperforms conventional SOTA transformers (BERT/BlueBert) by significantly larger margins (6-11%). We also show that the representations learned by RadBERT-CL can capture critical medical information in the latent space.
Making Document-Level Information Extraction Right for the Right Reasons
Oct 14, 2021

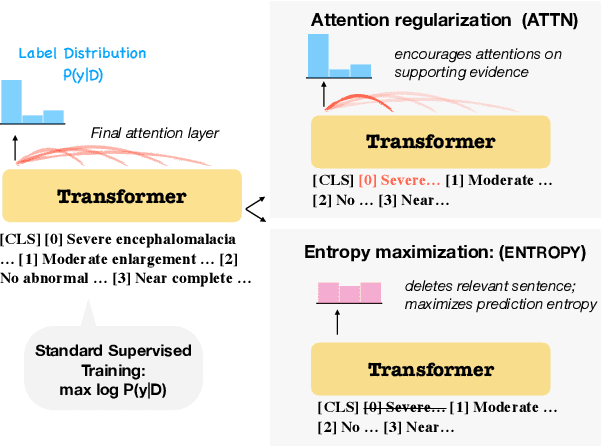
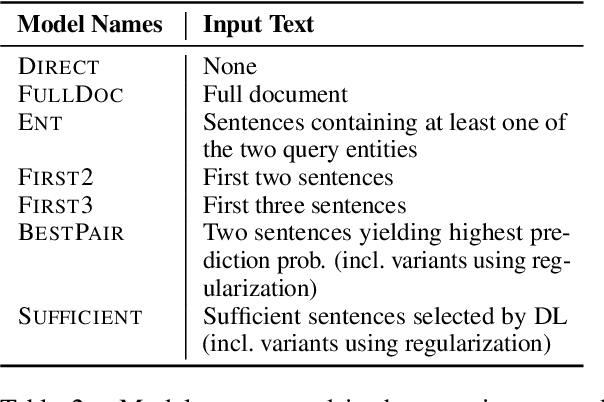
Document-level information extraction is a flexible framework compatible with applications where information is not necessarily localized in a single sentence. For example, key features of a diagnosis in radiology a report may not be explicitly stated, but nevertheless can be inferred from the report's text. However, document-level neural models can easily learn spurious correlations from irrelevant information. This work studies how to ensure that these models make correct inferences from complex text and make those inferences in an auditable way: beyond just being right, are these models "right for the right reasons?" We experiment with post-hoc evidence extraction in a predict-select-verify framework using feature attribution techniques. While this basic approach can extract reasonable evidence, it can be regularized with small amounts of evidence supervision during training, which substantially improves the quality of extracted evidence. We evaluate on two domains: a small-scale labeled dataset of brain MRI reports and a large-scale modified version of DocRED (Yao et al., 2019) and show that models' plausibility can be improved with no loss in accuracy.
Using Radiomics as Prior Knowledge for Abnormality Classification and Localization in Chest X-rays
Nov 25, 2020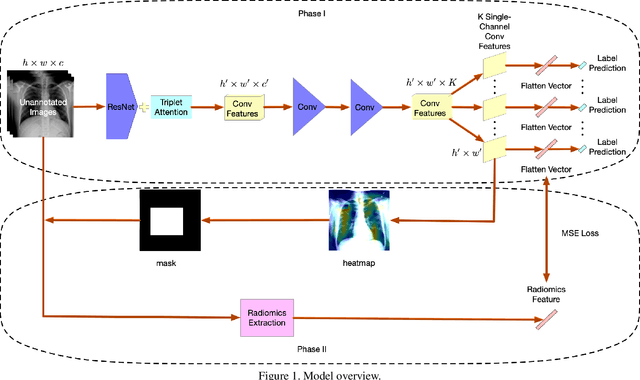


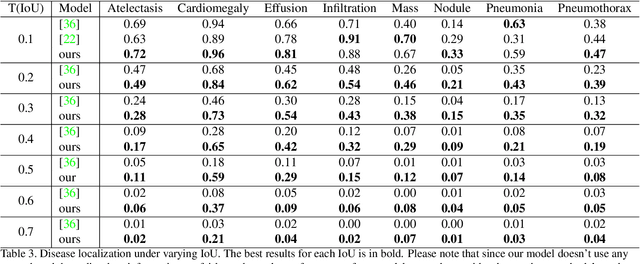
Chest X-rays become one of the most common medical diagnoses due to its noninvasiveness. The number of chest X-ray images has skyrocketed, but reading chest X-rays still have been manually performed by radiologists, which creates huge burnouts and delays. Traditionally, radiomics, as a subfield of radiology that can extract a large number of quantitative features from medical images, demonstrates its potential to facilitate medical imaging diagnosis before the deep learning era. In this paper, we develop an algorithm that can utilize the radiomics features to improve the abnormality classification performance. Our algorithm, ChexRadiNet, applies a light-weight but efficient triplet-attention mechanism for highlighting the meaningful image regions to improve localization accuracy. We first apply ChexRadiNet to classify the chest X-rays by using only image features. Then we use the generated heatmaps of chest X-rays to extract radiomics features. Finally, the extracted radiomics features could be used to guide our model to learn more robust accurate image features. After a number of iterations, our model could focus on more accurate image regions and extract more robust features. The empirical evaluation of our method supports our intuition and outperforms other state-of-the-art methods.