 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of the CXR-LT 2026 Challenge: Multi-Center Long-Tailed and Zero Shot Chest X-ray Classification
Feb 25, 2026Chest X-ray (CXR) interpretation is hindered by the long-tailed distribution of pathologies and the open-world nature of clinical environments. Existing benchmarks often rely on closed-set classes from single institutions, failing to capture the prevalence of rare diseases or the appearance of novel findings. To address this, we present the CXR-LT 2026 challenge. This third iteration of the benchmark introduces a multi-center dataset comprising over 145,000 images from PadChest and NIH Chest X-ray datasets. The challenge defines two core tasks: (1) Robust Multi-Label Classification on 30 known classes and (2) Open-World Generalization to 6 unseen (out-of-distribution) rare disease classes. We report the results of the top-performing teams, evaluating them via mean Average Precision (mAP), AUROC, and F1-score. The winning solutions achieved an mAP of 0.5854 on Task 1 and 0.4315 on Task 2, demonstrating that large-scale vision-language pre-training significantly mitigates the performance drop typically associated with zero-shot diagnosis.
RSNA Large Language Model Benchmark Dataset for Chest Radiographs of Cardiothoracic Disease: Radiologist Evaluation and Validation Enhanced by AI Labels (REVEAL-CXR)
Jan 21, 2026Multimodal large language models have demonstrated comparable performance to that of radiology trainees on multiple-choice board-style exams. However, to develop clinically useful multimodal LLM tools, high-quality benchmarks curated by domain experts are essential. To curate released and holdout datasets of 100 chest radiographic studies each and propose an artificial intelligence (AI)-assisted expert labeling procedure to allow radiologists to label studies more efficiently. A total of 13,735 deidentified chest radiographs and their corresponding reports from the MIDRC were used. GPT-4o extracted abnormal findings from the reports, which were then mapped to 12 benchmark labels with a locally hosted LLM (Phi-4-Reasoning). From these studies, 1,000 were sampled on the basis of the AI-suggested benchmark labels for expert review; the sampling algorithm ensured that the selected studies were clinically relevant and captured a range of difficulty levels. Seventeen chest radiologists participated, and they marked "Agree all", "Agree mostly" or "Disagree" to indicate their assessment of the correctness of the LLM suggested labels. Each chest radiograph was evaluated by three experts. Of these, at least two radiologists selected "Agree All" for 381 radiographs. From this set, 200 were selected, prioritizing those with less common or multiple finding labels, and divided into 100 released radiographs and 100 reserved as the holdout dataset. The holdout dataset is used exclusively by RSNA to independently evaluate different models. A benchmark of 200 chest radiographic studies with 12 benchmark labels was created and made publicly available https://imaging.rsna.org, with each chest radiograph verified by three radiologists. In addition, an AI-assisted labeling procedure was developed to help radiologists label at scale, minimize unnecessary omissions, and support a semicollaborative environment.
A Multi-agent Large Language Model Framework to Automatically Assess Performance of a Clinical AI Triage Tool
Oct 30, 2025Purpose: The purpose of this study was to determine if an ensemble of multiple LLM agents could be used collectively to provide a more reliable assessment of a pixel-based AI triage tool than a single LLM. Methods: 29,766 non-contrast CT head exams from fourteen hospitals were processed by a commercial intracranial hemorrhage (ICH) AI detection tool. Radiology reports were analyzed by an ensemble of eight open-source LLM models and a HIPAA compliant internal version of GPT-4o using a single multi-shot prompt that assessed for presence of ICH. 1,726 examples were manually reviewed. Performance characteristics of the eight open-source models and consensus were compared to GPT-4o. Three ideal consensus LLM ensembles were tested for rating the performance of the triage tool. Results: The cohort consisted of 29,766 head CTs exam-report pairs. The highest AUC performance was achieved with llama3.3:70b and GPT-4o (AUC= 0.78). The average precision was highest for Llama3.3:70b and GPT-4o (AP=0.75 & 0.76). Llama3.3:70b had the highest F1 score (0.81) and recall (0.85), greater precision (0.78), specificity (0.72), and MCC (0.57). Using MCC (95% CI) the ideal combination of LLMs were: Full-9 Ensemble 0.571 (0.552-0.591), Top-3 Ensemble 0.558 (0.537-0.579), Consensus 0.556 (0.539-0.574), and GPT4o 0.522 (0.500-0.543). No statistically significant differences were observed between Top-3, Full-9, and Consensus (p > 0.05). Conclusion: An ensemble of medium to large sized open-source LLMs provides a more consistent and reliable method to derive a ground truth retrospective evaluation of a clinical AI triage tool over a single LLM alone.
CXR-LT 2024: A MICCAI challenge on long-tailed, multi-label, and zero-shot disease classification from chest X-ray
Jun 09, 2025The CXR-LT series is a community-driven initiative designed to enhance lung disease classification using chest X-rays (CXR). It tackles challenges in open long-tailed lung disease classification and enhances the measurability of state-of-the-art techniques. The first event, CXR-LT 2023, aimed to achieve these goals by providing high-quality benchmark CXR data for model development and conducting comprehensive evaluations to identify ongoing issues impacting lung disease classification performance. Building on the success of CXR-LT 2023, the CXR-LT 2024 expands the dataset to 377,110 chest X-rays (CXRs) and 45 disease labels, including 19 new rare disease findings. It also introduces a new focus on zero-shot learning to address limitations identified in the previous event. Specifically, CXR-LT 2024 features three tasks: (i) long-tailed classification on a large, noisy test set, (ii) long-tailed classification on a manually annotated "gold standard" subset, and (iii) zero-shot generalization to five previously unseen disease findings. This paper provides an overview of CXR-LT 2024, detailing the data curation process and consolidating state-of-the-art solutions, including the use of multimodal models for rare disease detection, advanced generative approaches to handle noisy labels, and zero-shot learning strategies for unseen diseases. Additionally, the expanded dataset enhances disease coverage to better represent real-world clinical settings, offering a valuable resource for future research. By synthesizing the insights and innovations of participating teams, we aim to advance the development of clinically realistic and generalizable diagnostic models for chest radiography.
Generative Large Language Models Trained for Detecting Errors in Radiology Reports
Apr 06, 2025In this retrospective study, a dataset was constructed with two parts. The first part included 1,656 synthetic chest radiology reports generated by GPT-4 using specified prompts, with 828 being error-free synthetic reports and 828 containing errors. The second part included 614 reports: 307 error-free reports between 2011 and 2016 from the MIMIC-CXR database and 307 corresponding synthetic reports with errors generated by GPT-4 on the basis of these MIMIC-CXR reports and specified prompts. All errors were categorized into four types: negation, left/right, interval change, and transcription errors. Then, several models, including Llama-3, GPT-4, and BiomedBERT, were refined using zero-shot prompting, few-shot prompting, or fine-tuning strategies. Finally, the performance of these models was evaluated using the F1 score, 95\% confidence interval (CI) and paired-sample t-tests on our constructed dataset, with the prediction results further assessed by radiologists. Using zero-shot prompting, the fine-tuned Llama-3-70B-Instruct model achieved the best performance with the following F1 scores: 0.769 for negation errors, 0.772 for left/right errors, 0.750 for interval change errors, 0.828 for transcription errors, and 0.780 overall. In the real-world evaluation phase, two radiologists reviewed 200 randomly selected reports output by the model. Of these, 99 were confirmed to contain errors detected by the models by both radiologists, and 163 were confirmed to contain model-detected errors by at least one radiologist. Generative LLMs, fine-tuned on synthetic and MIMIC-CXR radiology reports, greatly enhanced error detection in radiology reports.
Enhancing disease detection in radiology reports through fine-tuning lightweight LLM on weak labels
Sep 25, 2024Despite significant progress in applying large language models (LLMs) to the medical domain, several limitations still prevent them from practical applications. Among these are the constraints on model size and the lack of cohort-specific labeled datasets. In this work, we investigated the potential of improving a lightweight LLM, such as Llama 3.1-8B, through fine-tuning with datasets using synthetic labels. Two tasks are jointly trained by combining their respective instruction datasets. When the quality of the task-specific synthetic labels is relatively high (e.g., generated by GPT4- o), Llama 3.1-8B achieves satisfactory performance on the open-ended disease detection task, with a micro F1 score of 0.91. Conversely, when the quality of the task-relevant synthetic labels is relatively low (e.g., from the MIMIC-CXR dataset), fine-tuned Llama 3.1-8B is able to surpass its noisy teacher labels (micro F1 score of 0.67 v.s. 0.63) when calibrated against curated labels, indicating the strong inherent underlying capability of the model. These findings demonstrate the potential of fine-tuning LLMs with synthetic labels, offering a promising direction for future research on LLM specialization in the medical domain.
The RSNA Abdominal Traumatic Injury CT (RATIC) Dataset
May 30, 2024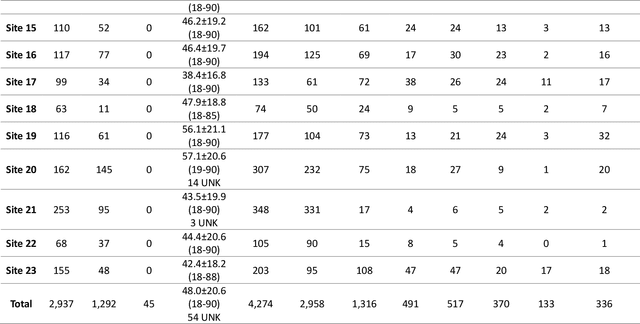
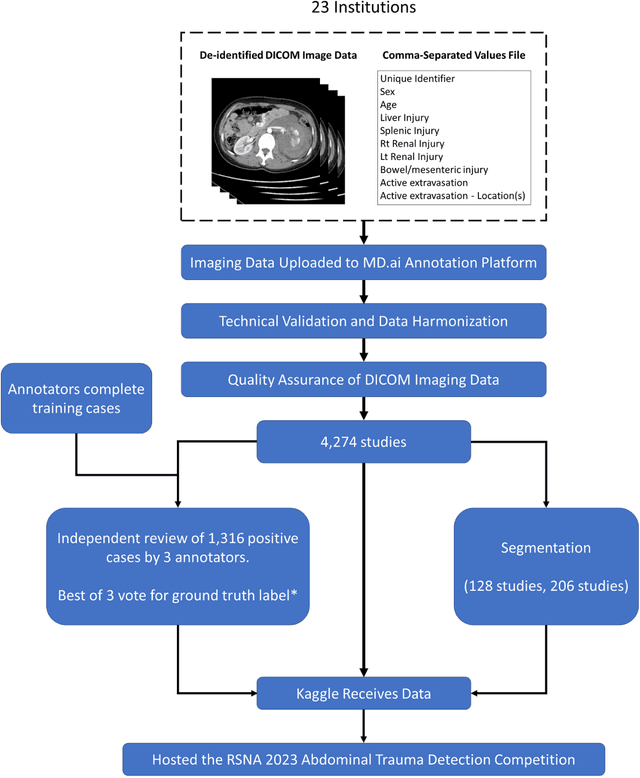
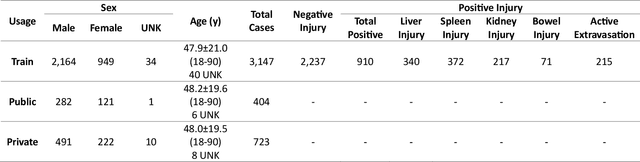
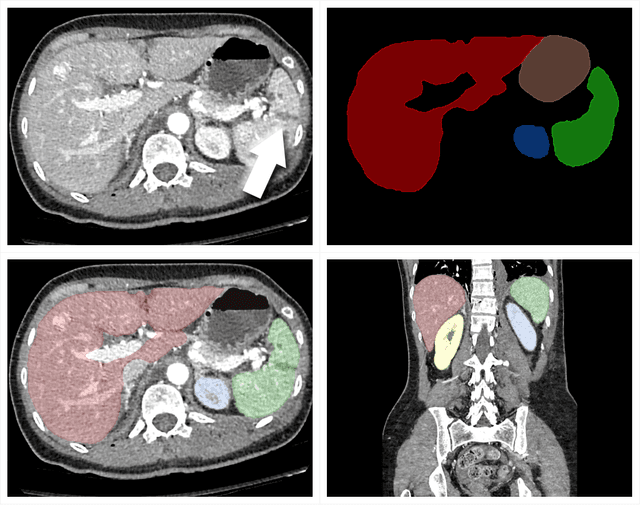
The RSNA Abdominal Traumatic Injury CT (RATIC) dataset is the largest publicly available collection of adult abdominal CT studies annotated for traumatic injuries. This dataset includes 4,274 studies from 23 institutions across 14 countries. The dataset is freely available for non-commercial use via Kaggle at https://www.kaggle.com/competitions/rsna-2023-abdominal-trauma-detection. Created for the RSNA 2023 Abdominal Trauma Detection competition, the dataset encourages the development of advanced machine learning models for detecting abdominal injuries on CT scans. The dataset encompasses detection and classification of traumatic injuries across multiple organs, including the liver, spleen, kidneys, bowel, and mesentery. Annotations were created by expert radiologists from the American Society of Emergency Radiology (ASER) and Society of Abdominal Radiology (SAR). The dataset is annotated at multiple levels, including the presence of injuries in three solid organs with injury grading, image-level annotations for active extravasations and bowel injury, and voxelwise segmentations of each of the potentially injured organs. With the release of this dataset, we hope to facilitate research and development in machine learning and abdominal trauma that can lead to improved patient care and outcomes.
Evaluating GPT-4 with Vision on Detection of Radiological Findings on Chest Radiographs
Apr 03, 2024The study examines the application of GPT-4V, a multi-modal large language model equipped with visual recognition, in detecting radiological findings from a set of 100 chest radiographs and suggests that GPT-4V is currently not ready for real-world diagnostic usage in interpreting chest radiographs.
Improving Fairness of Automated Chest X-ray Diagnosis by Contrastive Learning
Jan 25, 2024Purpose: Limited studies exploring concrete methods or approaches to tackle and enhance model fairness in the radiology domain. Our proposed AI model utilizes supervised contrastive learning to minimize bias in CXR diagnosis. Materials and Methods: In this retrospective study, we evaluated our proposed method on two datasets: the Medical Imaging and Data Resource Center (MIDRC) dataset with 77,887 CXR images from 27,796 patients collected as of April 20, 2023 for COVID-19 diagnosis, and the NIH Chest X-ray (NIH-CXR) dataset with 112,120 CXR images from 30,805 patients collected between 1992 and 2015. In the NIH-CXR dataset, thoracic abnormalities include atelectasis, cardiomegaly, effusion, infiltration, mass, nodule, pneumonia, pneumothorax, consolidation, edema, emphysema, fibrosis, pleural thickening, or hernia. Our proposed method utilizes supervised contrastive learning with carefully selected positive and negative samples to generate fair image embeddings, which are fine-tuned for subsequent tasks to reduce bias in chest X-ray (CXR) diagnosis. We evaluated the methods using the marginal AUC difference ($\delta$ mAUC). Results: The proposed model showed a significant decrease in bias across all subgroups when compared to the baseline models, as evidenced by a paired T-test (p<0.0001). The $\delta$ mAUC obtained by our method were 0.0116 (95\% CI, 0.0110-0.0123), 0.2102 (95% CI, 0.2087-0.2118), and 0.1000 (95\% CI, 0.0988-0.1011) for sex, race, and age on MIDRC, and 0.0090 (95\% CI, 0.0082-0.0097) for sex and 0.0512 (95% CI, 0.0512-0.0532) for age on NIH-CXR, respectively. Conclusion: Employing supervised contrastive learning can mitigate bias in CXR diagnosis, addressing concerns of fairness and reliability in deep learning-based diagnostic methods.
Towards long-tailed, multi-label disease classification from chest X-ray: Overview of the CXR-LT challenge
Oct 24, 2023



Many real-world image recognition problems, such as diagnostic medical imaging exams, are "long-tailed" $\unicode{x2013}$ there are a few common findings followed by many more relatively rare conditions. In chest radiography, diagnosis is both a long-tailed and multi-label problem, as patients often present with multiple findings simultaneously. While researchers have begun to study the problem of long-tailed learning in medical image recognition, few have studied the interaction of label imbalance and label co-occurrence posed by long-tailed, multi-label disease classification. To engage with the research community on this emerging topic, we conducted an open challenge, CXR-LT, on long-tailed, multi-label thorax disease classification from chest X-rays (CXRs). We publicly release a large-scale benchmark dataset of over 350,000 CXRs, each labeled with at least one of 26 clinical findings following a long-tailed distribution. We synthesize common themes of top-performing solutions, providing practical recommendations for long-tailed, multi-label medical image classification. Finally, we use these insights to propose a path forward involving vision-language foundation models for few- and zero-shot disease classification.