 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSNA Large Language Model Benchmark Dataset for Chest Radiographs of Cardiothoracic Disease: Radiologist Evaluation and Validation Enhanced by AI Labels (REVEAL-CXR)
Jan 21, 2026Multimodal large language models have demonstrated comparable performance to that of radiology trainees on multiple-choice board-style exams. However, to develop clinically useful multimodal LLM tools, high-quality benchmarks curated by domain experts are essential. To curate released and holdout datasets of 100 chest radiographic studies each and propose an artificial intelligence (AI)-assisted expert labeling procedure to allow radiologists to label studies more efficiently. A total of 13,735 deidentified chest radiographs and their corresponding reports from the MIDRC were used. GPT-4o extracted abnormal findings from the reports, which were then mapped to 12 benchmark labels with a locally hosted LLM (Phi-4-Reasoning). From these studies, 1,000 were sampled on the basis of the AI-suggested benchmark labels for expert review; the sampling algorithm ensured that the selected studies were clinically relevant and captured a range of difficulty levels. Seventeen chest radiologists participated, and they marked "Agree all", "Agree mostly" or "Disagree" to indicate their assessment of the correctness of the LLM suggested labels. Each chest radiograph was evaluated by three experts. Of these, at least two radiologists selected "Agree All" for 381 radiographs. From this set, 200 were selected, prioritizing those with less common or multiple finding labels, and divided into 100 released radiographs and 100 reserved as the holdout dataset. The holdout dataset is used exclusively by RSNA to independently evaluate different models. A benchmark of 200 chest radiographic studies with 12 benchmark labels was created and made publicly available https://imaging.rsna.org, with each chest radiograph verified by three radiologists. In addition, an AI-assisted labeling procedure was developed to help radiologists label at scale, minimize unnecessary omissions, and support a semicollaborative environment.
A Multi-Stage Large Language Model Framework for Extracting Suicide-Related Social Determinants of Health
Aug 07, 2025Background: Understanding social determinants of health (SDoH) factors contributing to suicide incidents is crucial for early intervention and prevention. However, data-driven approaches to this goal face challenges such as long-tailed factor distributions, analyzing pivotal stressors preceding suicide incidents, and limited model explainability. Methods: We present a multi-stage large language model framework to enhance SDoH factor extraction from unstructured text. Our approach was compared to other state-of-the-art language models (i.e., pre-trained BioBERT and GPT-3.5-turbo) and reasoning models (i.e., DeepSeek-R1). We also evaluated how the model's explanations help people annotate SDoH factors more quickly and accurately. The analysis included both automated comparisons and a pilot user study. Results: We show that our proposed framework demonstrated performance boosts in the overarching task of extracting SDoH factors and in the finer-grained tasks of retrieving relevant context. Additionally, we show that fine-tuning a smaller, task-specific model achieves comparable or better performance with reduced inference costs. The multi-stage design not only enhances extraction but also provides intermediate explanations, improving model explainability. Conclusions: Our approach improves both the accuracy and transparency of extracting suicide-related SDoH from unstructured texts. These advancements have the potential to support early identification of individuals at risk and inform more effective prevention strategies.
CXR-LT 2024: A MICCAI challenge on long-tailed, multi-label, and zero-shot disease classification from chest X-ray
Jun 09, 2025The CXR-LT series is a community-driven initiative designed to enhance lung disease classification using chest X-rays (CXR). It tackles challenges in open long-tailed lung disease classification and enhances the measurability of state-of-the-art techniques. The first event, CXR-LT 2023, aimed to achieve these goals by providing high-quality benchmark CXR data for model development and conducting comprehensive evaluations to identify ongoing issues impacting lung disease classification performance. Building on the success of CXR-LT 2023, the CXR-LT 2024 expands the dataset to 377,110 chest X-rays (CXRs) and 45 disease labels, including 19 new rare disease findings. It also introduces a new focus on zero-shot learning to address limitations identified in the previous event. Specifically, CXR-LT 2024 features three tasks: (i) long-tailed classification on a large, noisy test set, (ii) long-tailed classification on a manually annotated "gold standard" subset, and (iii) zero-shot generalization to five previously unseen disease findings. This paper provides an overview of CXR-LT 2024, detailing the data curation process and consolidating state-of-the-art solutions, including the use of multimodal models for rare disease detection, advanced generative approaches to handle noisy labels, and zero-shot learning strategies for unseen diseases. Additionally, the expanded dataset enhances disease coverage to better represent real-world clinical settings, offering a valuable resource for future research. By synthesizing the insights and innovations of participating teams, we aim to advance the development of clinically realistic and generalizable diagnostic models for chest radiography.
Machine Learning Applications Related to Suicide in Military and Veterans: A Scoping Literature Review
May 18, 2025Suicide remains one of the main preventable causes of death among active service members and veterans. Early detection and prediction are crucial in suicide prevention. Machine learning techniques have yielded promising results in this area recently. This study aims to assess and summarize current research and provides a comprehensive review regarding the application of machine learning techniques in assessing and predicting suicidal ideation, attempts, and mortality among members of military and veteran populations. A keyword search using PubMed, IEEE, ACM, and Google Scholar was conducted, and the PRISMA protocol was adopted for relevant study selection. Thirty-two articles met the inclusion criteria. These studies consistently identified risk factors relevant to mental health issues such as depression, post-traumatic stress disorder (PTSD), suicidal ideation, prior attempts, physical health problems, and demographic characteristics. Machine learning models applied in this area have demonstrated reasonable predictive accuracy. However, additional research gaps still exist. First, many studies have overlooked metrics that distinguish between false positives and negatives, such as positive predictive value and negative predictive value, which are crucial in the context of suicide prevention policies. Second, more dedicated approaches to handling survival and longitudinal data should be explored. Lastly, most studies focused on machine learning methods, with limited discussion of their connection to clinical rationales. In summary, machine learning analyses have identified a wide range of risk factors associated with suicide in military populations. The diversity and complexity of these factors also demonstrates that effective prevention strategies must be comprehensive and flexible.
Deciphering genomic codes using advanced NLP techniques: a scoping review
Nov 25, 2024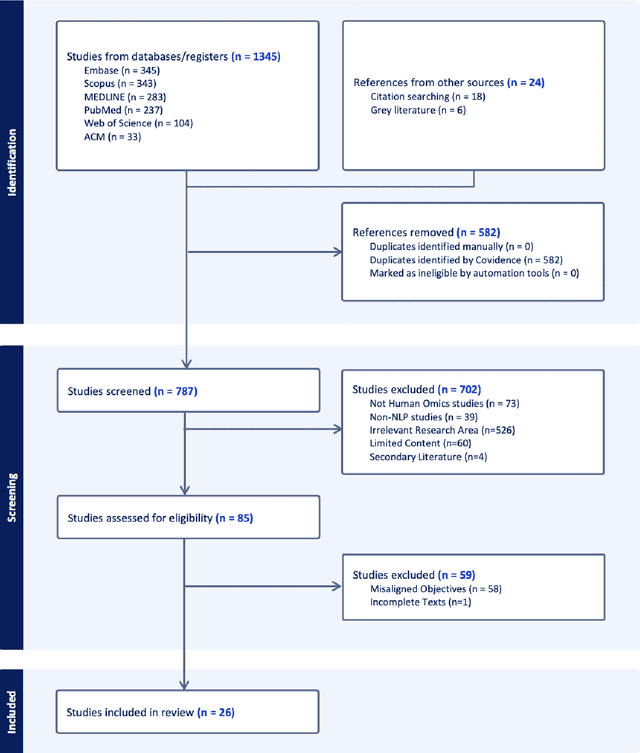
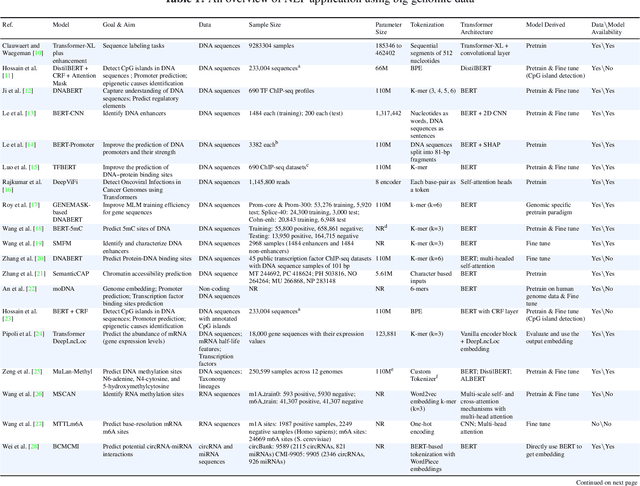
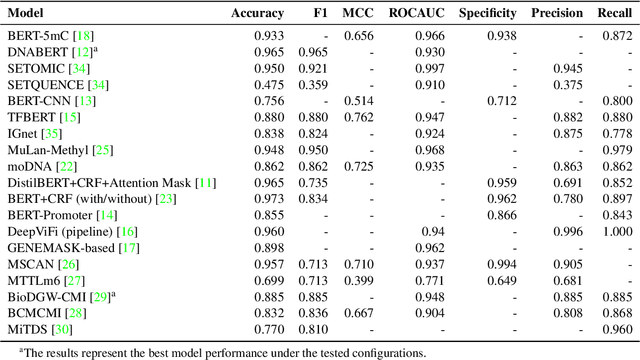
Objectives: The vast and complex nature of human genomic sequencing data presents challenges for effective analysis. This review aims to investigate the application of Natural Language Processing (NLP) techniques, particularly Large Language Models (LLMs) and transformer architectures, in deciphering genomic codes, focusing on tokenization, transformer models, and regulatory annotation prediction. The goal of this review is to assess data and model accessibility in the most recent literature, gaining a better understanding of the existing capabilities and constraints of these tools in processing genomic sequencing data. Methods: Following Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines, our scoping review was conducted across PubMed, Medline, Scopus, Web of Science, Embase, and ACM Digital Library. Studies were included if they focused on NLP methodologies applied to genomic sequencing data analysis, without restrictions on publication date or article type. Results: A total of 26 studies published between 2021 and April 2024 were selected for review. The review highlights that tokenization and transformer models enhance the processing and understanding of genomic data, with applications in predicting regulatory annotations like transcription-factor binding sites and chromatin accessibility. Discussion: The application of NLP and LLMs to genomic sequencing data interpretation is a promising field that can help streamline the processing of large-scale genomic data while also providing a better understanding of its complex structures. It has the potential to drive advancements in personalized medicine by offering more efficient and scalable solutions for genomic analysis. Further research is also needed to discuss and overcome current limitations, enhancing model transparency and applicability.
Enhancing disease detection in radiology reports through fine-tuning lightweight LLM on weak labels
Sep 25, 2024Despite significant progress in applying large language models (LLMs) to the medical domain, several limitations still prevent them from practical applications. Among these are the constraints on model size and the lack of cohort-specific labeled datasets. In this work, we investigated the potential of improving a lightweight LLM, such as Llama 3.1-8B, through fine-tuning with datasets using synthetic labels. Two tasks are jointly trained by combining their respective instruction datasets. When the quality of the task-specific synthetic labels is relatively high (e.g., generated by GPT4- o), Llama 3.1-8B achieves satisfactory performance on the open-ended disease detection task, with a micro F1 score of 0.91. Conversely, when the quality of the task-relevant synthetic labels is relatively low (e.g., from the MIMIC-CXR dataset), fine-tuned Llama 3.1-8B is able to surpass its noisy teacher labels (micro F1 score of 0.67 v.s. 0.63) when calibrated against curated labels, indicating the strong inherent underlying capability of the model. These findings demonstrate the potential of fine-tuning LLMs with synthetic labels, offering a promising direction for future research on LLM specialization in the medical domain.
Deep learning with noisy labels in medical prediction problems: a scoping review
Mar 19, 2024



Objectives: Medical research faces substantial challenges from noisy labels attributed to factors like inter-expert variability and machine-extracted labels. Despite this, the adoption of label noise management remains limited, and label noise is largely ignored. To this end, there is a critical need to conduct a scoping review focusing on the problem space. This scoping review aims to comprehensively review label noise management in deep learning-based medical prediction problems, which includes label noise detection, label noise handling, and evaluation. Research involving label uncertainty is also included. Methods: Our scoping review follows the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines. We searched 4 databases, including PubMed, IEEE Xplore, Google Scholar, and Semantic Scholar. Our search terms include "noisy label AND medical / healthcare / clinical", "un-certainty AND medical / healthcare / clinical", and "noise AND medical / healthcare / clinical". Results: A total of 60 papers met inclusion criteria between 2016 and 2023. A series of practical questions in medical research are investigated. These include the sources of label noise, the impact of label noise, the detection of label noise, label noise handling techniques, and their evaluation. Categorization of both label noise detection methods and handling techniques are provided. Discussion: From a methodological perspective, we observe that the medical community has been up to date with the broader deep-learning community, given that most techniques have been evaluated on medical data. We recommend considering label noise as a standard element in medical research, even if it is not dedicated to handling noisy labels. Initial experiments can start with easy-to-implement methods, such as noise-robust loss functions, weighting, and curriculum learning.