 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextBoost: Boosting Scene Text Fidelity in Ultra-low Bitrate Image Compression
Mar 04, 2026Ultra-low bitrate image compression faces a critical challenge: preserving small-font scene text while maintaining overall visual quality. Region-of-interest (ROI) bit allocation can prioritize text but often degrades global fidelity, leading to a trade-off between local accuracy and overall image quality. Instead of relying on ROI coding, we incorporate auxiliary textual information extracted by OCR and transmitted with negligible overhead, enabling the decoder to leverage this semantic guidance. Our method, TextBoost, operationalizes this idea through three strategic designs: (i) adaptively filtering OCR outputs and rendering them into a guidance map; (ii) integrating this guidance with decoder features in a calibrated manner via an attention-guided fusion block; and (iii) enforcing guidance-consistent reconstruction in text regions with a regularizing loss that promotes natural blending with the scene. Extensive experiments on TextOCR and ICDAR 2015 demonstrate that TextBoost yields up to 60.6% higher text-recognition F1 at comparable Peak Signal-to-Noise Ratio (PSNR) and bits per pixel (bpp), producing sharper small-font text while preserving global image quality and effectively decoupling text enhancement from global rate-distortion optimization.
A Scoping Review of Natural Language Processing in Addressing Medically Inaccurate Information: Errors, Misinformation, and Hallucination
Apr 16, 2025Objective: This review aims to explore the potential and challenges of using Natural Language Processing (NLP) to detect, correct, and mitigate medically inaccurate information, including errors, misinformation, and hallucination. By unifying these concepts, the review emphasizes their shared methodological foundations and their distinct implications for healthcare. Our goal is to advance patient safety, improve public health communication, and support the development of more reliable and transparent NLP applications in healthcare. Methods: A scoping review was conducted following PRISMA guidelines, analyzing studies from 2020 to 2024 across five databases. Studies were selected based on their use of NLP to address medically inaccurate information and were categorized by topic, tasks, document types, datasets, models, and evaluation metrics. Results: NLP has shown potential in addressing medically inaccurate information on the following tasks: (1) error detection (2) error correction (3) misinformation detection (4) misinformation correction (5) hallucination detection (6) hallucination mitigation. However, challenges remain with data privacy, context dependency, and evaluation standards. Conclusion: This review highlights the advancements in applying NLP to tackle medically inaccurate information while underscoring the need to address persistent challenges. Future efforts should focus on developing real-world datasets, refining contextual methods, and improving hallucination management to ensure reliable and transparent healthcare applications.
MEDEC: A Benchmark for Medical Error Detection and Correction in Clinical Notes
Dec 26, 2024Several studies showed that Large Language Models (LLMs) can answer medical questions correctly, even outperforming the average human score in some medical exams. However, to our knowledge, no study has been conducted to assess the ability of language models to validate existing or generated medical text for correctness and consistency. In this paper, we introduce MEDEC (https://github.com/abachaa/MEDEC), the first publicly available benchmark for medical error detection and correction in clinical notes, covering five types of errors (Diagnosis, Management, Treatment, Pharmacotherapy, and Causal Organism). MEDEC consists of 3,848 clinical texts, including 488 clinical notes from three US hospital systems that were not previously seen by any LLM. The dataset has been used for the MEDIQA-CORR shared task to evaluate seventeen participating systems [Ben Abacha et al., 2024]. In this paper, we describe the data creation methods and we evaluate recent LLMs (e.g., o1-preview, GPT-4, Claude 3.5 Sonnet, and Gemini 2.0 Flash) for the tasks of detecting and correcting medical errors requiring both medical knowledge and reasoning capabilities. We also conducted a comparative study where two medical doctors performed the same task on the MEDEC test set. The results showed that MEDEC is a sufficiently challenging benchmark to assess the ability of models to validate existing or generated notes and to correct medical errors. We also found that although recent LLMs have a good performance in error detection and correction, they are still outperformed by medical doctors in these tasks. We discuss the potential factors behind this gap, the insights from our experiments, the limitations of current evaluation metrics, and share potential pointers for future research.
Improving Fairness of Automated Chest X-ray Diagnosis by Contrastive Learning
Jan 25, 2024Purpose: Limited studies exploring concrete methods or approaches to tackle and enhance model fairness in the radiology domain. Our proposed AI model utilizes supervised contrastive learning to minimize bias in CXR diagnosis. Materials and Methods: In this retrospective study, we evaluated our proposed method on two datasets: the Medical Imaging and Data Resource Center (MIDRC) dataset with 77,887 CXR images from 27,796 patients collected as of April 20, 2023 for COVID-19 diagnosis, and the NIH Chest X-ray (NIH-CXR) dataset with 112,120 CXR images from 30,805 patients collected between 1992 and 2015. In the NIH-CXR dataset, thoracic abnormalities include atelectasis, cardiomegaly, effusion, infiltration, mass, nodule, pneumonia, pneumothorax, consolidation, edema, emphysema, fibrosis, pleural thickening, or hernia. Our proposed method utilizes supervised contrastive learning with carefully selected positive and negative samples to generate fair image embeddings, which are fine-tuned for subsequent tasks to reduce bias in chest X-ray (CXR) diagnosis. We evaluated the methods using the marginal AUC difference ($\delta$ mAUC). Results: The proposed model showed a significant decrease in bias across all subgroups when compared to the baseline models, as evidenced by a paired T-test (p<0.0001). The $\delta$ mAUC obtained by our method were 0.0116 (95\% CI, 0.0110-0.0123), 0.2102 (95% CI, 0.2087-0.2118), and 0.1000 (95\% CI, 0.0988-0.1011) for sex, race, and age on MIDRC, and 0.0090 (95\% CI, 0.0082-0.0097) for sex and 0.0512 (95% CI, 0.0512-0.0532) for age on NIH-CXR, respectively. Conclusion: Employing supervised contrastive learning can mitigate bias in CXR diagnosis, addressing concerns of fairness and reliability in deep learning-based diagnostic methods.
A scoping review on multimodal deep learning in biomedical images and texts
Jul 14, 2023



Computer-assisted diagnostic and prognostic systems of the future should be capable of simultaneously processing multimodal data. Multimodal deep learning (MDL), which involves the integration of multiple sources of data, such as images and text, has the potential to revolutionize the analysis and interpretation of biomedical data. However, it only caught researchers' attention recently. To this end, there is a critical need to conduct a systematic review on this topic, identify the limitations of current work, and explore future directions. In this scoping review, we aim to provide a comprehensive overview of the current state of the field and identify key concepts, types of studies, and research gaps with a focus on biomedical images and texts joint learning, mainly because these two were the most commonly available data types in MDL research. This study reviewed the current uses of multimodal deep learning on five tasks: (1) Report generation, (2) Visual question answering, (3) Cross-modal retrieval, (4) Computer-aided diagnosis, and (5) Semantic segmentation. Our results highlight the diverse applications and potential of MDL and suggest directions for future research in the field. We hope our review will facilitate the collaboration of natural language processing (NLP) and medical imaging communities and support the next generation of decision-making and computer-assisted diagnostic system development.
T-ADAF: Adaptive Data Augmentation Framework for Image Classification Network based on Tensor T-product Operator
Jun 07, 2023Image classification is one of the most fundamental tasks in Computer Vision. In practical applications, the datasets are usually not as abundant as those in the laboratory and simulation, which is always called as Data Hungry. How to extract the information of data more completely and effectively is very important. Therefore, an Adaptive Data Augmentation Framework based on the tensor T-product Operator is proposed in this paper, to triple one image data to be trained and gain the result from all these three images together with only less than 0.1% increase in the number of parameters. At the same time, this framework serves the functions of column image embedding and global feature intersection, enabling the model to obtain information in not only spatial but frequency domain, and thus improving the prediction accuracy of the model. Numerical experiments have been designed for several models, and the results demonstrate the effectiveness of this adaptive framework. Numerical experiments show that our data augmentation framework can improve the performance of original neural network model by 2%, which provides competitive results to state-of-the-art methods.
GOLLIC: Learning Global Context beyond Patches for Lossless High-Resolution Image Compression
Oct 07, 2022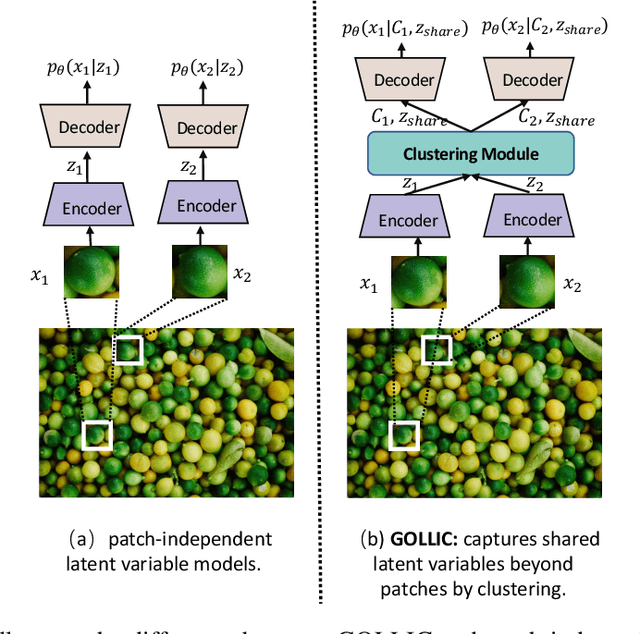



Neural-network-based approaches recently emerged in the field of data compression and have already led to significant progress in image compression, especially in achieving a higher compression ratio. In the lossless image compression scenario, however, existing methods often struggle to learn a probability model of full-size high-resolution images due to the limitation of the computation source. The current strategy is to crop high-resolution images into multiple non-overlapping patches and process them independently. This strategy ignores long-term dependencies beyond patches, thus limiting modeling performance. To address this problem, we propose a hierarchical latent variable model with a global context to capture the long-term dependencies of high-resolution images. Besides the latent variable unique to each patch, we introduce shared latent variables between patches to construct the global context. The shared latent variables are extracted by a self-supervised clustering module inside the model's encoder. This clustering module assigns each patch the confidence that it belongs to any cluster. Later, shared latent variables are learned according to latent variables of patches and their confidence, which reflects the similarity of patches in the same cluster and benefits the global context modeling. Experimental results show that our global context model improves compression ratio compared to the engineered codecs and deep learning models on three benchmark high-resolution image datasets, DIV2K, CLIC.pro, and CLIC.mobile.