 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevelopment, Evaluation, and Deployment of a Multi-Agent System for Thoracic Tumor Board
Apr 14, 2026Tumor boards are multidisciplinary conferences dedicated to producing actionable patient care recommendations with live review of primary radiology and pathology data. Succinct patient case summaries are needed to drive efficient and accurate case discussions. We developed a manual AI-based workflow to generate patient summaries to display live at the Stanford Thoracic Tumor board. To improve on this manually intensive process, we developed several automated AI chart summarization methods and evaluated them against physician gold standard summaries and fact-based scoring rubrics. We report these comparative evaluations as well as our deployment of the final state automated AI chart summarization tool along with post-deployment monitoring. We also validate the use of an LLM as a judge evaluation strategy for fact-based scoring. This work is an example of integrating AI-based workflows into routine clinical practice.
CoRe-BT: A Multimodal Radiology-Pathology-Text Benchmark for Robust Brain Tumor Typing
Mar 04, 2026Accurate brain tumor typing requires integrating heterogeneous clinical evidence, including magnetic resonance imaging (MRI), histopathology, and pathology reports, which are often incomplete at the time of diagnosis. We introduce CoRe-BT, a cross-modal radiology-pathology-text benchmark for brain tumor typing, designed to study robust multimodal learning under missing modality conditions. The dataset comprises 310 patients with multi-sequence brain MRI (T1, T1c, T2, FLAIR), including 95 cases with paired H&E-stained whole-slide pathology images and pathology reports. All cases are annotated with tumor type and grade, and MRI volumes include expert-annotated tumor masks, enabling both region-aware modeling and auxiliary learning tasks. Tumors are categorized into six clinically relevant classes capturing the heterogeneity of common and rare glioma subtypes. We evaluate tumor typing under variable modality availability by comparing MRI-only models with multimodal approaches that incorporate pathology information when present. Baseline experiments demonstrate the feasibility of multimodal fusion and highlight complementary modality contributions across clinically relevant typing tasks. CoRe-BT provides a grounded testbed for advancing multimodal glioma typing and representation learning in realistic scenarios with incomplete clinical data.
Scaling medical imaging report generation with multimodal reinforcement learning
Jan 23, 2026Frontier models have demonstrated remarkable capabilities in understanding and reasoning with natural-language text, but they still exhibit major competency gaps in multimodal understanding and reasoning especially in high-value verticals such as biomedicine. Medical imaging report generation is a prominent example. Supervised fine-tuning can substantially improve performance, but they are prone to overfitting to superficial boilerplate patterns. In this paper, we introduce Universal Report Generation (UniRG) as a general framework for medical imaging report generation. By leveraging reinforcement learning as a unifying mechanism to directly optimize for evaluation metrics designed for end applications, UniRG can significantly improve upon supervised fine-tuning and attain durable generalization across diverse institutions and clinical practices. We trained UniRG-CXR on publicly available chest X-ray (CXR) data and conducted a thorough evaluation in CXR report generation with rigorous evaluation scenarios. On the authoritative ReXrank benchmark, UniRG-CXR sets new overall SOTA, outperforming prior state of the art by a wide margin.
DermaVQA-DAS: Dermatology Assessment Schema (DAS) & Datasets for Closed-Ended Question Answering & Segmentation in Patient-Generated Dermatology Images
Dec 30, 2025Recent advances in dermatological image analysis have been driven by large-scale annotated datasets; however, most existing benchmarks focus on dermatoscopic images and lack patient-authored queries and clinical context, limiting their applicability to patient-centered care. To address this gap, we introduce DermaVQA-DAS, an extension of the DermaVQA dataset that supports two complementary tasks: closed-ended question answering (QA) and dermatological lesion segmentation. Central to this work is the Dermatology Assessment Schema (DAS), a novel expert-developed framework that systematically captures clinically meaningful dermatological features in a structured and standardized form. DAS comprises 36 high-level and 27 fine-grained assessment questions, with multiple-choice options in English and Chinese. Leveraging DAS, we provide expert-annotated datasets for both closed QA and segmentation and benchmark state-of-the-art multimodal models. For segmentation, we evaluate multiple prompting strategies and show that prompt design impacts performance: the default prompt achieves the best results under Mean-of-Max and Mean-of-Mean evaluation aggregation schemes, while an augmented prompt incorporating both patient query title and content yields the highest performance under majority-vote-based microscore evaluation, achieving a Jaccard index of 0.395 and a Dice score of 0.566 with BiomedParse. For closed-ended QA, overall performance is strong across models, with average accuracies ranging from 0.729 to 0.798; o3 achieves the best overall accuracy (0.798), closely followed by GPT-4.1 (0.796), while Gemini-1.5-Pro shows competitive performance within the Gemini family (0.783). We publicly release DermaVQA-DAS, the DAS schema, and evaluation protocols to support and accelerate future research in patient-centered dermatological vision-language modeling (https://osf.io/72rp3).
MORQA: Benchmarking Evaluation Metrics for Medical Open-Ended Question Answering
Sep 15, 2025



Evaluating natural language generation (NLG) systems in the medical domain presents unique challenges due to the critical demands for accuracy, relevance, and domain-specific expertise. Traditional automatic evaluation metrics, such as BLEU, ROUGE, and BERTScore, often fall short in distinguishing between high-quality outputs, especially given the open-ended nature of medical question answering (QA) tasks where multiple valid responses may exist. In this work, we introduce MORQA (Medical Open-Response QA), a new multilingual benchmark designed to assess the effectiveness of NLG evaluation metrics across three medical visual and text-based QA datasets in English and Chinese. Unlike prior resources, our datasets feature 2-4+ gold-standard answers authored by medical professionals, along with expert human ratings for three English and Chinese subsets. We benchmark both traditional metrics and large language model (LLM)-based evaluators, such as GPT-4 and Gemini, finding that LLM-based approaches significantly outperform traditional metrics in correlating with expert judgments. We further analyze factors driving this improvement, including LLMs' sensitivity to semantic nuances and robustness to variability among reference answers. Our results provide the first comprehensive, multilingual qualitative study of NLG evaluation in the medical domain, highlighting the need for human-aligned evaluation methods. All datasets and annotations will be publicly released to support future research.
CancerGUIDE: Cancer Guideline Understanding via Internal Disagreement Estimation
Sep 09, 2025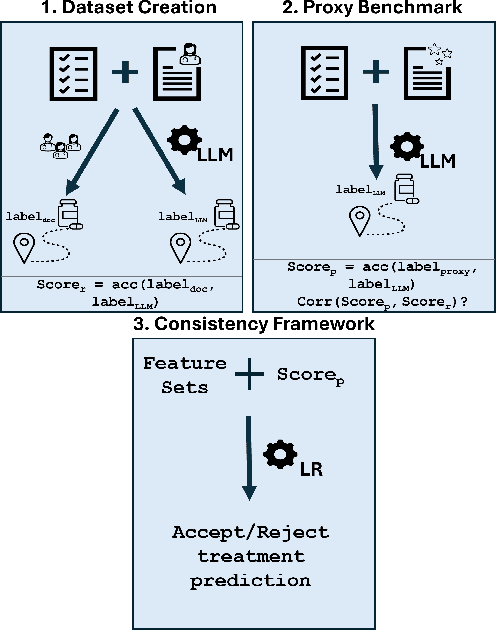
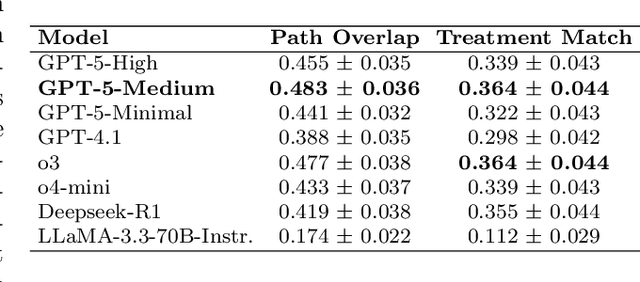
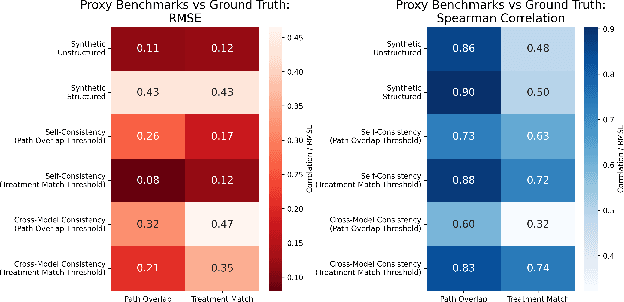

The National Comprehensive Cancer Network (NCCN) provides evidence-based guidelines for cancer treatment. Translating complex patient presentations into guideline-compliant treatment recommendations is time-intensive, requires specialized expertise, and is prone to error. Advances in large language model (LLM) capabilities promise to reduce the time required to generate treatment recommendations and improve accuracy. We present an LLM agent-based approach to automatically generate guideline-concordant treatment trajectories for patients with non-small cell lung cancer (NSCLC). Our contributions are threefold. First, we construct a novel longitudinal dataset of 121 cases of NSCLC patients that includes clinical encounters, diagnostic results, and medical histories, each expertly annotated with the corresponding NCCN guideline trajectories by board-certified oncologists. Second, we demonstrate that existing LLMs possess domain-specific knowledge that enables high-quality proxy benchmark generation for both model development and evaluation, achieving strong correlation (Spearman coefficient r=0.88, RMSE = 0.08) with expert-annotated benchmarks. Third, we develop a hybrid approach combining expensive human annotations with model consistency information to create both the agent framework that predicts the relevant guidelines for a patient, as well as a meta-classifier that verifies prediction accuracy with calibrated confidence scores for treatment recommendations (AUROC=0.800), a critical capability for communicating the accuracy of outputs, custom-tailoring tradeoffs in performance, and supporting regulatory compliance. This work establishes a framework for clinically viable LLM-based guideline adherence systems that balance accuracy, interpretability, and regulatory requirements while reducing annotation costs, providing a scalable pathway toward automated clinical decision support.
MedHELM: Holistic Evaluation of Large Language Models for Medical Tasks
May 26, 2025



While large language models (LLMs) achieve near-perfect scores on medical licensing exams, these evaluations inadequately reflect the complexity and diversity of real-world clinical practice. We introduce MedHELM, an extensible evaluation framework for assessing LLM performance for medical tasks with three key contributions. First, a clinician-validated taxonomy spanning 5 categories, 22 subcategories, and 121 tasks developed with 29 clinicians. Second, a comprehensive benchmark suite comprising 35 benchmarks (17 existing, 18 newly formulated) providing complete coverage of all categories and subcategories in the taxonomy. Third, a systematic comparison of LLMs with improved evaluation methods (using an LLM-jury) and a cost-performance analysis. Evaluation of 9 frontier LLMs, using the 35 benchmarks, revealed significant performance variation. Advanced reasoning models (DeepSeek R1: 66% win-rate; o3-mini: 64% win-rate) demonstrated superior performance, though Claude 3.5 Sonnet achieved comparable results at 40% lower estimated computational cost. On a normalized accuracy scale (0-1), most models performed strongly in Clinical Note Generation (0.73-0.85) and Patient Communication & Education (0.78-0.83), moderately in Medical Research Assistance (0.65-0.75), and generally lower in Clinical Decision Support (0.56-0.72) and Administration & Workflow (0.53-0.63). Our LLM-jury evaluation method achieved good agreement with clinician ratings (ICC = 0.47), surpassing both average clinician-clinician agreement (ICC = 0.43) and automated baselines including ROUGE-L (0.36) and BERTScore-F1 (0.44). Claude 3.5 Sonnet achieved comparable performance to top models at lower estimated cost. These findings highlight the importance of real-world, task-specific evaluation for medical use of LLMs and provides an open source framework to enable this.
MEDEC: A Benchmark for Medical Error Detection and Correction in Clinical Notes
Dec 26, 2024Several studies showed that Large Language Models (LLMs) can answer medical questions correctly, even outperforming the average human score in some medical exams. However, to our knowledge, no study has been conducted to assess the ability of language models to validate existing or generated medical text for correctness and consistency. In this paper, we introduce MEDEC (https://github.com/abachaa/MEDEC), the first publicly available benchmark for medical error detection and correction in clinical notes, covering five types of errors (Diagnosis, Management, Treatment, Pharmacotherapy, and Causal Organism). MEDEC consists of 3,848 clinical texts, including 488 clinical notes from three US hospital systems that were not previously seen by any LLM. The dataset has been used for the MEDIQA-CORR shared task to evaluate seventeen participating systems [Ben Abacha et al., 2024]. In this paper, we describe the data creation methods and we evaluate recent LLMs (e.g., o1-preview, GPT-4, Claude 3.5 Sonnet, and Gemini 2.0 Flash) for the tasks of detecting and correcting medical errors requiring both medical knowledge and reasoning capabilities. We also conducted a comparative study where two medical doctors performed the same task on the MEDEC test set. The results showed that MEDEC is a sufficiently challenging benchmark to assess the ability of models to validate existing or generated notes and to correct medical errors. We also found that although recent LLMs have a good performance in error detection and correction, they are still outperformed by medical doctors in these tasks. We discuss the potential factors behind this gap, the insights from our experiments, the limitations of current evaluation metrics, and share potential pointers for future research.
ACI-BENCH: a Novel Ambient Clinical Intelligence Dataset for Benchmarking Automatic Visit Note Generation
Jun 03, 2023Recent immense breakthroughs in generative models such as in GPT4 have precipitated re-imagined ubiquitous usage of these models in all applications. One area that can benefit by improvements in artificial intelligence (AI) is healthcare. The note generation task from doctor-patient encounters, and its associated electronic medical record documentation, is one of the most arduous time-consuming tasks for physicians. It is also a natural prime potential beneficiary to advances in generative models. However with such advances, benchmarking is more critical than ever. Whether studying model weaknesses or developing new evaluation metrics, shared open datasets are an imperative part of understanding the current state-of-the-art. Unfortunately as clinic encounter conversations are not routinely recorded and are difficult to ethically share due to patient confidentiality, there are no sufficiently large clinic dialogue-note datasets to benchmark this task. Here we present the Ambient Clinical Intelligence Benchmark (ACI-BENCH) corpus, the largest dataset to date tackling the problem of AI-assisted note generation from visit dialogue. We also present the benchmark performances of several common state-of-the-art approaches.
An Investigation of Evaluation Metrics for Automated Medical Note Generation
May 27, 2023



Recent studies on automatic note generation have shown that doctors can save significant amounts of time when using automatic clinical note generation (Knoll et al., 2022). Summarization models have been used for this task to generate clinical notes as summaries of doctor-patient conversations (Krishna et al., 2021; Cai et al., 2022). However, assessing which model would best serve clinicians in their daily practice is still a challenging task due to the large set of possible correct summaries, and the potential limitations of automatic evaluation metrics. In this paper, we study evaluation methods and metrics for the automatic generation of clinical notes from medical conversations. In particular, we propose new task-specific metrics and we compare them to SOTA evaluation metrics in text summarization and generation, including: (i) knowledge-graph embedding-based metrics, (ii) customized model-based metrics, (iii) domain-adapted/fine-tuned metrics, and (iv) ensemble metrics. To study the correlation between the automatic metrics and manual judgments, we evaluate automatic notes/summaries by comparing the system and reference facts and computing the factual correctness, and the hallucination and omission rates for critical medical facts. This study relied on seven datasets manually annotated by domain experts. Our experiments show that automatic evaluation metrics can have substantially different behaviors on different types of clinical notes datasets. However, the results highlight one stable subset of metrics as the most correlated with human judgments with a relevant aggregation of different evaluation criteria.