 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Contrastive Learning with Generative Adversarial Network
Aug 01, 2023



Graph Neural Networks (GNNs) have demonstrated promising results on exploiting node representations for many downstream tasks through supervised end-to-end training. To deal with the widespread label scarcity issue in real-world applications, Graph Contrastive Learning (GCL) is leveraged to train GNNs with limited or even no labels by maximizing the mutual information between nodes in its augmented views generated from the original graph. However, the distribution of graphs remains unconsidered in view generation, resulting in the ignorance of unseen edges in most existing literature, which is empirically shown to be able to improve GCL's performance in our experiments. To this end, we propose to incorporate graph generative adversarial networks (GANs) to learn the distribution of views for GCL, in order to i) automatically capture the characteristic of graphs for augmentations, and ii) jointly train the graph GAN model and the GCL model. Specifically, we present GACN, a novel Generative Adversarial Contrastive learning Network for graph representation learning. GACN develops a view generator and a view discriminator to generate augmented views automatically in an adversarial style. Then, GACN leverages these views to train a GNN encoder with two carefully designed self-supervised learning losses, including the graph contrastive loss and the Bayesian personalized ranking Loss. Furthermore, we design an optimization framework to train all GACN modules jointly. Extensive experiments on seven real-world datasets show that GACN is able to generate high-quality augmented views for GCL and is superior to twelve state-of-the-art baseline methods. Noticeably, our proposed GACN surprisingly discovers that the generated views in data augmentation finally conform to the well-known preferential attachment rule in online networks.
PANE-GNN: Unifying Positive and Negative Edges in Graph Neural Networks for Recommendation
Jun 08, 2023



Recommender systems play a crucial role in addressing the issue of information overload by delivering personalized recommendations to users. In recent years, there has been a growing interest in leveraging graph neural networks (GNNs) for recommender systems, capitalizing on advancements in graph representation learning. These GNN-based models primarily focus on analyzing users' positive feedback while overlooking the valuable insights provided by their negative feedback. In this paper, we propose PANE-GNN, an innovative recommendation model that unifies Positive And Negative Edges in Graph Neural Networks for recommendation. By incorporating user preferences and dispreferences, our approach enhances the capability of recommender systems to offer personalized suggestions. PANE-GNN first partitions the raw rating graph into two distinct bipartite graphs based on positive and negative feedback. Subsequently, we employ two separate embeddings, the interest embedding and the disinterest embedding, to capture users' likes and dislikes, respectively. To facilitate effective information propagation, we design distinct message-passing mechanisms for positive and negative feedback. Furthermore, we introduce a distortion to the negative graph, which exclusively consists of negative feedback edges, for contrastive training. This distortion plays a crucial role in effectively denoising the negative feedback. The experimental results provide compelling evidence that PANE-GNN surpasses the existing state-of-the-art benchmark methods across four real-world datasets. These datasets include three commonly used recommender system datasets and one open-source short video recommendation dataset.
Explicit and Implicit Semantic Ranking Framework
Apr 11, 2023


The core challenge in numerous real-world applications is to match an inquiry to the best document from a mutable and finite set of candidates. Existing industry solutions, especially latency-constrained services, often rely on similarity algorithms that sacrifice quality for speed. In this paper we introduce a generic semantic learning-to-rank framework, Self-training Semantic Cross-attention Ranking (sRank). This transformer-based framework uses linear pairwise loss with mutable training batch sizes and achieves quality gains and high efficiency, and has been applied effectively to show gains on two industry tasks at Microsoft over real-world large-scale data sets: Smart Reply (SR) and Ambient Clinical Intelligence (ACI). In Smart Reply, $sRank$ assists live customers with technical support by selecting the best reply from predefined solutions based on consumer and support agent messages. It achieves 11.7% gain in offline top-one accuracy on the SR task over the previous system, and has enabled 38.7% time reduction in composing messages in telemetry recorded since its general release in January 2021. In the ACI task, sRank selects relevant historical physician templates that serve as guidance for a text summarization model to generate higher quality medical notes. It achieves 35.5% top-one accuracy gain, along with 46% relative ROUGE-L gain in generated medical notes.
HybridGNN: Learning Hybrid Representation in Multiplex Heterogeneous Networks
Aug 03, 2022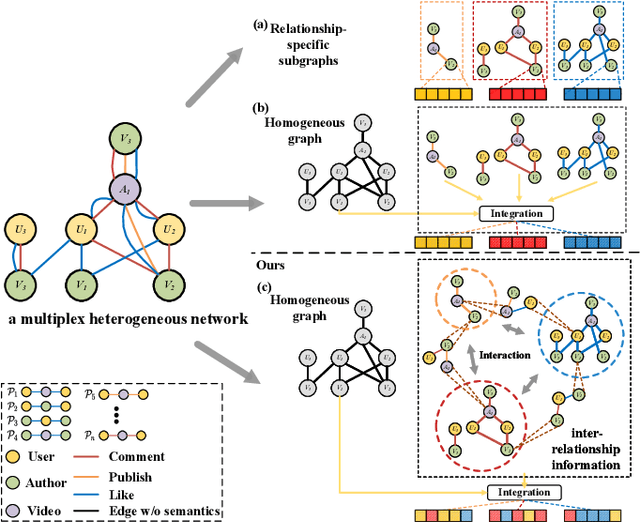
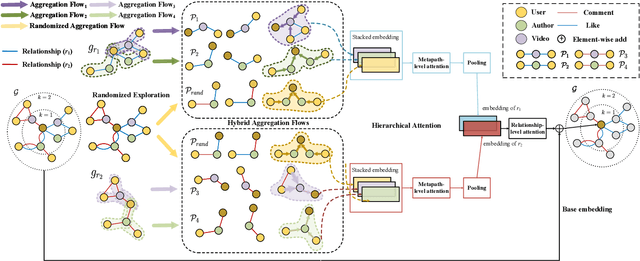
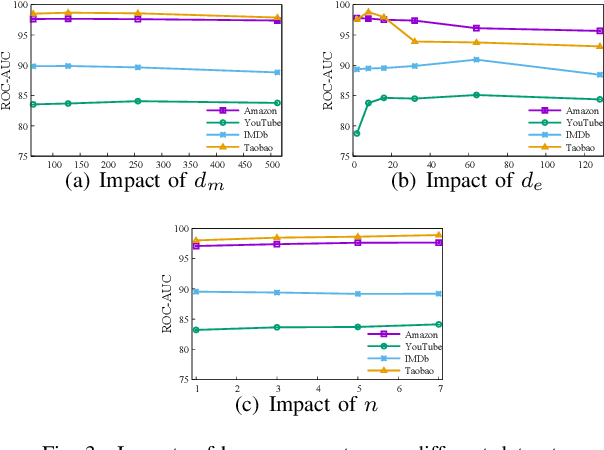
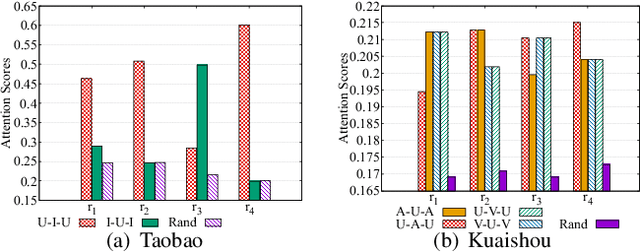
Recently, graph neural networks have shown the superiority of modeling the complex topological structures in heterogeneous network-based recommender systems. Due to the diverse interactions among nodes and abundant semantics emerging from diverse types of nodes and edges, there is a bursting research interest in learning expressive node representations in multiplex heterogeneous networks. One of the most important tasks in recommender systems is to predict the potential connection between two nodes under a specific edge type (i.e., relationship). Although existing studies utilize explicit metapaths to aggregate neighbors, practically they only consider intra-relationship metapaths and thus fail to leverage the potential uplift by inter-relationship information. Moreover, it is not always straightforward to exploit inter-relationship metapaths comprehensively under diverse relationships, especially with the increasing number of node and edge types. In addition, contributions of different relationships between two nodes are difficult to measure. To address the challenges, we propose HybridGNN, an end-to-end GNN model with hybrid aggregation flows and hierarchical attentions to fully utilize the heterogeneity in the multiplex scenarios. Specifically, HybridGNN applies a randomized inter-relationship exploration module to exploit the multiplexity property among different relationships. Then, our model leverages hybrid aggregation flows under intra-relationship metapaths and randomized exploration to learn the rich semantics. To explore the importance of different aggregation flow and take advantage of the multiplexity property, we bring forward a novel hierarchical attention module which leverages both metapath-level attention and relationship-level attention. Extensive experimental results suggest that HybridGNN achieves the best performance compared to several state-of-the-art baselines.
Temporal-Spatial Causal Interpretations for Vision-Based Reinforcement Learning
Dec 06, 2021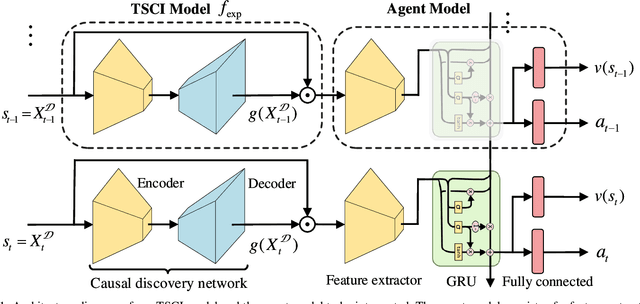

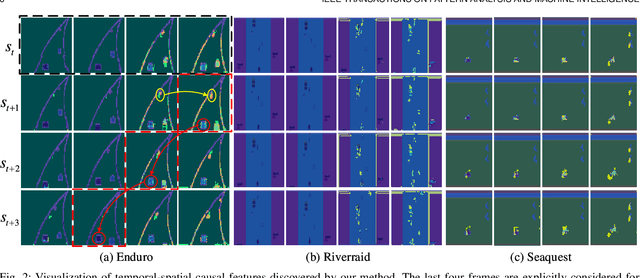
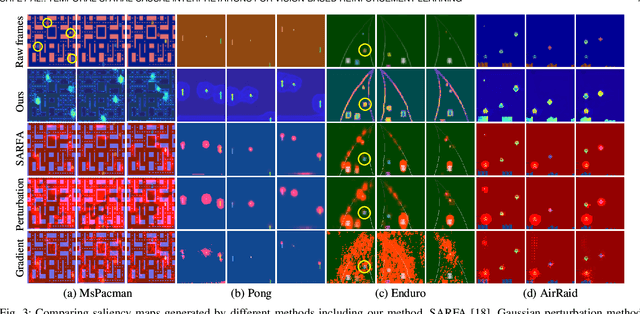
Deep reinforcement learning (RL) agents are becoming increasingly proficient in a range of complex control tasks. However, the agent's behavior is usually difficult to interpret due to the introduction of black-box function, making it difficult to acquire the trust of users. Although there have been some interesting interpretation methods for vision-based RL, most of them cannot uncover temporal causal information, raising questions about their reliability. To address this problem, we present a temporal-spatial causal interpretation (TSCI) model to understand the agent's long-term behavior, which is essential for sequential decision-making. TSCI model builds on the formulation of temporal causality, which reflects the temporal causal relations between sequential observations and decisions of RL agent. Then a separate causal discovery network is employed to identify temporal-spatial causal features, which are constrained to satisfy the temporal causality. TSCI model is applicable to recurrent agents and can be used to discover causal features with high efficiency once trained. The empirical results show that TSCI model can produce high-resolution and sharp attention masks to highlight task-relevant temporal-spatial information that constitutes most evidence about how vision-based RL agents make sequential decisions. In addition, we further demonstrate that our method is able to provide valuable causal interpretations for vision-based RL agents from the temporal perspective.
Regularizing Deep Networks with Semantic Data Augmentation
Jul 22, 2020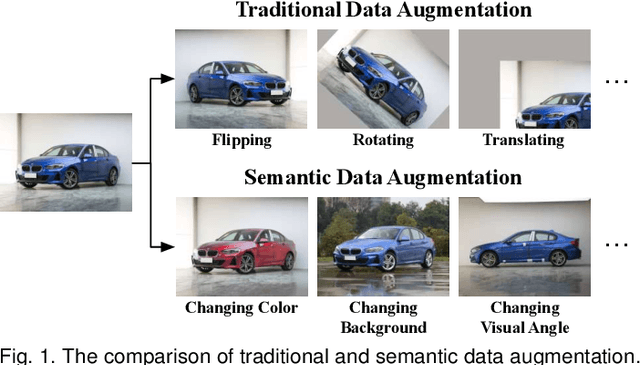
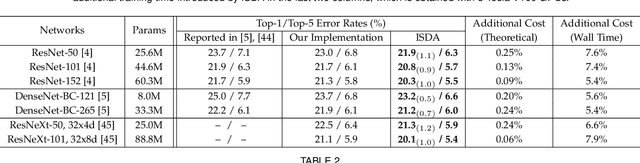
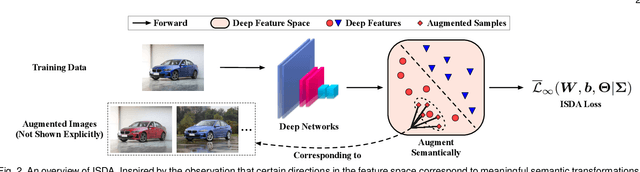
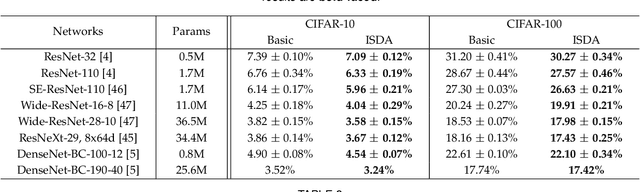
Data augmentation is widely known as a simple yet surprisingly effective technique for regularizing deep networks. Conventional data augmentation schemes, e.g., flipping, translation or rotation, are low-level, data-independent and class-agnostic operations, leading to limited diversity for augmented samples. To this end, we propose a novel semantic data augmentation algorithm to complement traditional approaches. The proposed method is inspired by the intriguing property that deep networks are effective in learning linearized features, i.e., certain directions in the deep feature space correspond to meaningful semantic transformations, e.g., changing the background or view angle of an object. Based on this observation, translating training samples along many such directions in the feature space can effectively augment the dataset for more diversity. To implement this idea, we first introduce a sampling based method to obtain semantically meaningful directions efficiently. Then, an upper bound of the expected cross-entropy (CE) loss on the augmented training set is derived by assuming the number of augmented samples goes to infinity, yielding a highly efficient algorithm. In fact, we show that the proposed implicit semantic data augmentation (ISDA) algorithm amounts to minimizing a novel robust CE loss, which adds minimal extra computational cost to a normal training procedure. In addition to supervised learning, ISDA can be applied to semi-supervised learning tasks under the consistency regularization framework, where ISDA amounts to minimizing the upper bound of the expected KL-divergence between the augmented features and the original features. Although being simple, ISDA consistently improves the generalization performance of popular deep models (e.g., ResNets and DenseNets) on a variety of datasets, i.e., CIFAR-10, CIFAR-100, SVHN, ImageNet, Cityscapes and MS COCO.
Implicit Semantic Data Augmentation for Deep Networks
Sep 27, 2019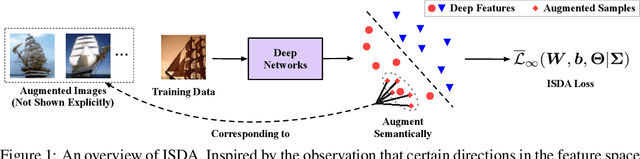
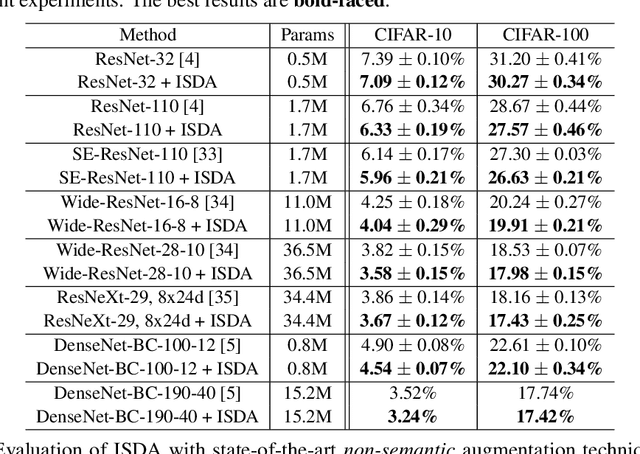
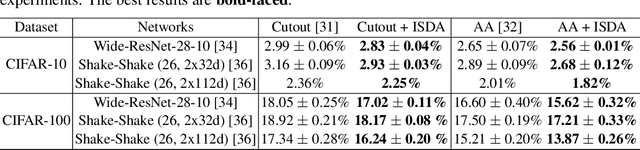
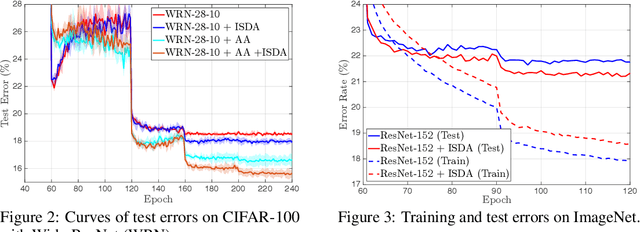
In this paper, we propose a novel implicit semantic data augmentation (ISDA) approach to complement traditional augmentation techniques like flipping, translation or rotation. Our work is motivated by the intriguing property that deep networks are surprisingly good at linearizing features, such that certain directions in the deep feature space correspond to meaningful semantic transformations, e.g., adding sunglasses or changing backgrounds. As a consequence, translating training samples along many semantic directions in the feature space can effectively augment the dataset to improve generalization. To implement this idea effectively and efficiently, we first perform an online estimate of the covariance matrix of deep features for each class, which captures the intra-class semantic variations. Then random vectors are drawn from a zero-mean normal distribution with the estimated covariance to augment the training data in that class. Importantly, instead of augmenting the samples explicitly, we can directly minimize an upper bound of the expected cross-entropy (CE) loss on the augmented training set, leading to a highly efficient algorithm. In fact, we show that the proposed ISDA amounts to minimizing a novel robust CE loss, which adds negligible extra computational cost to a normal training procedure. Although being simple, ISDA consistently improves the generalization performance of popular deep models (ResNets and DenseNets) on a variety of datasets, e.g., CIFAR-10, CIFAR-100 and ImageNet. Code for reproducing our results are available at https://github.com/blackfeather-wang/ISDA-for-Deep-Networks.
Regularized Anderson Acceleration for Off-Policy Deep Reinforcement Learning
Sep 07, 2019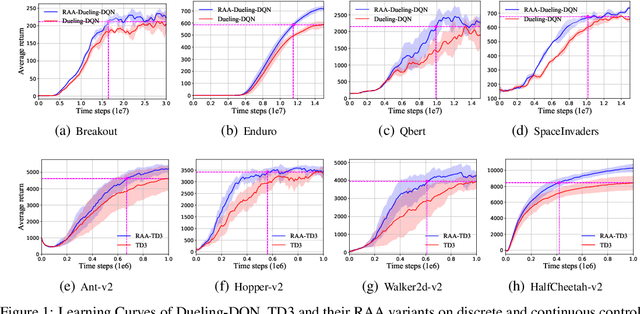
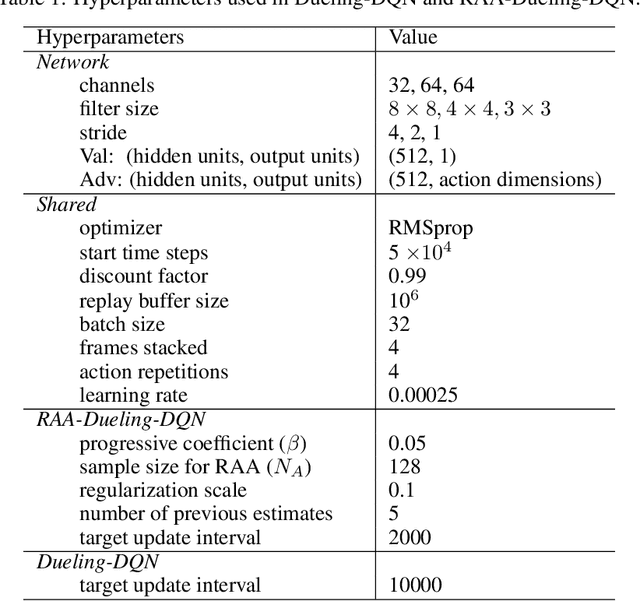
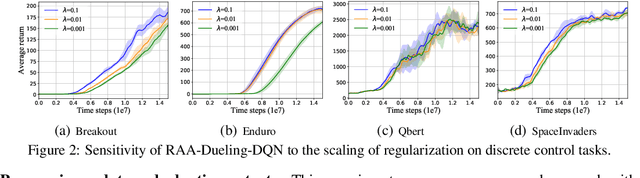
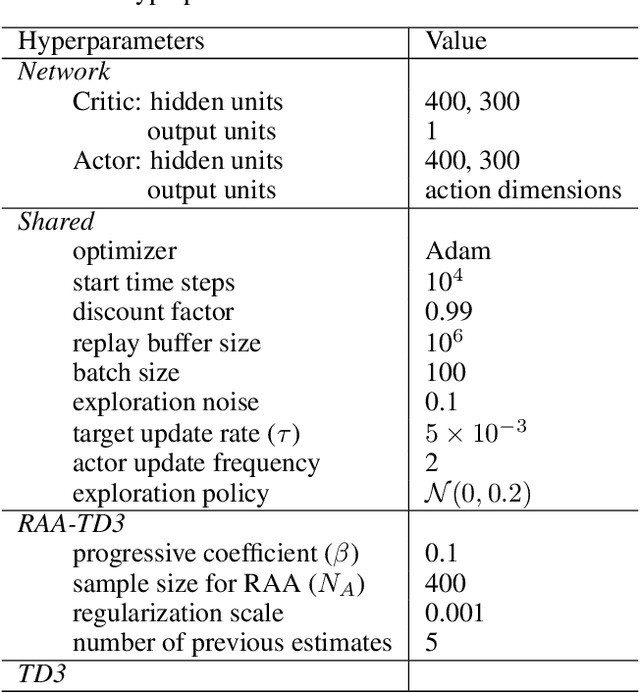
Model-free deep reinforcement learning (RL) algorithms have been widely used for a range of complex control tasks. However, slow convergence and sample inefficiency remain challenging problems in RL, especially when handling continuous and high-dimensional state spaces. To tackle this problem, we propose a general acceleration method for model-free, off-policy deep RL algorithms by drawing the idea underlying regularized Anderson acceleration (RAA), which is an effective approach to accelerating the solving of fixed point problems with perturbations. Specifically, we first explain how policy iteration can be applied directly with Anderson acceleration. Then we extend RAA to the case of deep RL by introducing a regularization term to control the impact of perturbation induced by function approximation errors. We further propose two strategies, i.e., progressive update and adaptive restart, to enhance the performance. The effectiveness of our method is evaluated on a variety of benchmark tasks, including Atari 2600 and MuJoCo. Experimental results show that our approach substantially improves both the learning speed and final performance of state-of-the-art deep RL algorithms.
Multi Pseudo Q-learning Based Deterministic Policy Gradient for Tracking Control of Autonomous Underwater Vehicles
Sep 07, 2019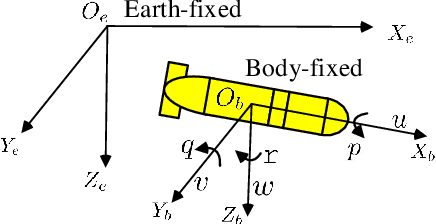
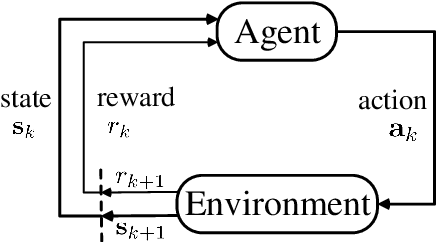
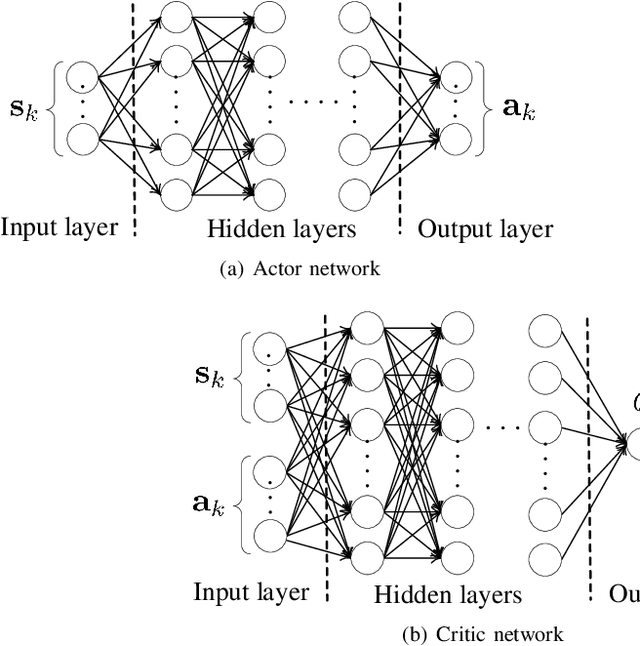
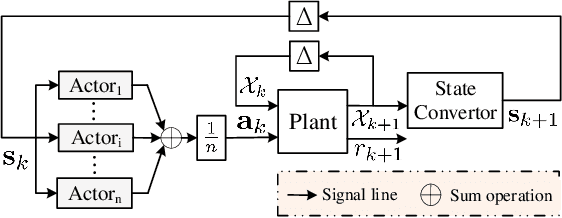
This paper investigates trajectory tracking problem for a class of underactuated autonomous underwater vehicles (AUVs) with unknown dynamics and constrained inputs. Different from existing policy gradient methods which employ single actor-critic but cannot realize satisfactory tracking control accuracy and stable learning, our proposed algorithm can achieve high-level tracking control accuracy of AUVs and stable learning by applying a hybrid actors-critics architecture, where multiple actors and critics are trained to learn a deterministic policy and action-value function, respectively. Specifically, for the critics, the expected absolute Bellman error based updating rule is used to choose the worst critic to be updated in each time step. Subsequently, to calculate the loss function with more accurate target value for the chosen critic, Pseudo Q-learning, which uses sub-greedy policy to replace the greedy policy in Q-learning, is developed for continuous action spaces, and Multi Pseudo Q-learning (MPQ) is proposed to reduce the overestimation of action-value function and to stabilize the learning. As for the actors, deterministic policy gradient is applied to update the weights, and the final learned policy is defined as the average of all actors to avoid large but bad updates. Moreover, the stability analysis of the learning is given qualitatively. The effectiveness and generality of the proposed MPQ-based Deterministic Policy Gradient (MPQ-DPG) algorithm are verified by the application on AUV with two different reference trajectories. And the results demonstrate high-level tracking control accuracy and stable learning of MPQ-DPG. Besides, the results also validate that increasing the number of the actors and critics will further improve the performance.
Soft Policy Gradient Method for Maximum Entropy Deep Reinforcement Learning
Sep 07, 2019
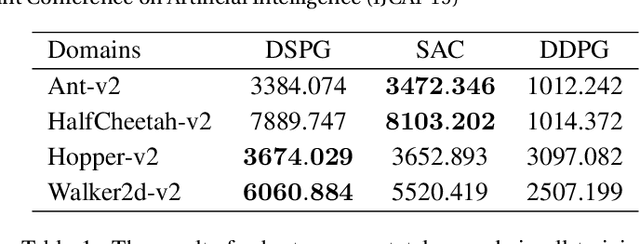
Maximum entropy deep reinforcement learning (RL) methods have been demonstrated on a range of challenging continuous tasks. However, existing methods either suffer from severe instability when training on large off-policy data or cannot scale to tasks with very high state and action dimensionality such as 3D humanoid locomotion. Besides, the optimality of desired Boltzmann policy set for non-optimal soft value function is not persuasive enough. In this paper, we first derive soft policy gradient based on entropy regularized expected reward objective for RL with continuous actions. Then, we present an off-policy actor-critic, model-free maximum entropy deep RL algorithm called deep soft policy gradient (DSPG) by combining soft policy gradient with soft Bellman equation. To ensure stable learning while eliminating the need of two separate critics for soft value functions, we leverage double sampling approach to making the soft Bellman equation tractable. The experimental results demonstrate that our method outperforms in performance over off-policy prior methods.