 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Boundary Probing and Demand-Guided Intervention for LLM-Based Power System Code Generation
May 29, 2026Large language models (LLMs) are increasingly used to automate power-system analysis, but many utilities and energy-research labs require on-premise serving for confidentiality, regulatory, reproducibility, and cost reasons. This makes the reliability of open-weight models a deployment issue. We show that first-pass failures in power-system code generation are dominated not by reasoning alone, but by structured API-knowledge boundary errors: hallucinated function names, misused parameters, and mishandled result tables in versioned simulation libraries. We introduce PowerCodeBench, an execution-validated benchmark generator that pairs natural-language operator queries with pandapower code and numerical ground truth; an L0-L3 documentation-driven probing procedure that measures per-model API knowledge profiles; and a boundary-aware intervention that combines query-side API demand estimation with targeted proactive documentation injection and routed reactive correction. On a 2,000-task frozen release, we evaluate ten open-weight LLMs (1.5B-480B parameters) and four commercial mid-tier APIs. The intervention improves every evaluated open-weight model of at least 7B parameters and every commercial API by 32 to 56 accuracy points. Open-weight models in the 70B-120B range match the commercial mid-tier accuracy range, while Llama-3.1-405B and Qwen3-Coder-480B lead the panel. The targeted prompts preserve the full-context accuracy ceiling while using 41% of the prompt-token cost. The result is an accuracy-side, deployment-time path toward reliable on-premise LLM assistance for grid-analysis workflows without fine-tuning or cloud inference.
From Intent to Evidence: A Categorical Approach for Structural Evaluation of Deep Research Agents
Mar 26, 2026Although deep research agents (DRAs) have emerged as a promising paradigm for complex information synthesis, their evaluation remains constrained by ad hoc empirical benchmarks. These heuristic approaches do not rigorously model agent behavior or adequately stress-test long-horizon synthesis and ambiguity resolution. To bridge this gap, we formalize DRA behavior through the lens of category theory, modeling deep research workflow as a composition of structure-preserving maps (functors). Grounded in this theoretical framework, we introduce a novel mechanism-aware benchmark with 296 questions designed to stress-test agents along four interpretable axes: traversing sequential connectivity chains, verifying intersections within V-structure pullbacks, imposing topological ordering on retrieved substructures, and performing ontological falsification via the Yoneda Probe. Our rigorous evaluation of 11 leading models establishes a persistently low baseline, with the state-of-the-art achieving only a 19.9\% average accuracy, exposing the difficulty of formal structural stress-testing. Furthermore, our findings reveal a stark dichotomy in the current AI capabilities. While advanced deep research pipelines successfully redefine dynamic topological re-ordering and exhibit robust ontological verification -- matching pure reasoning models in falsifying hallucinated premises -- they almost universally collapse on multi-hop structural synthesis. Crucially, massive performance variance across tasks exposes a lingering reliance on brittle heuristics rather than a systemic understanding. Ultimately, this work demonstrates that while top-tier autonomous agents can now organically unify search and reasoning, achieving a generalized mastery over complex structural information remains a formidable open challenge.\footnote{Our implementation will be available at https://github.com/tzq1999/CDR.
GRAFITE: Generative Regression Analysis Framework for Issue Tracking and Evaluation
Mar 18, 2026Large language models (LLMs) are largely motivated by their performance on popular topics and benchmarks at the time of their release. However, over time, contamination occurs due to significant exposure of benchmark data during training. This poses a risk of model performance inflation if testing is not carefully executed. To address this challenge, we present GRAFITE, a continuous LLM evaluation platform through a comprehensive system for maintaining and evaluating model issues. Our approach enables building a repository of model problems based on user feedback over time and offers a pipeline for assessing LLMs against these issues through quality assurance (QA) tests using LLM-as-a-judge. The platform enables side-by-side comparison of multiple models, facilitating regression detection across different releases. The platform is available at https://github.com/IBM/grafite. The demo video is available at www.youtube.com/watch?v=XFZyoleN56k.
Not All Preferences Are Created Equal: Stability-Aware and Gradient-Efficient Alignment for Reasoning Models
Feb 01, 2026Preference-based alignment is pivotal for training large reasoning models; however, standard methods like Direct Preference Optimization (DPO) typically treat all preference pairs uniformly, overlooking the evolving utility of training instances. This static approach often leads to inefficient or unstable optimization, as it wastes computation on trivial pairs with negligible gradients and suffers from noise induced by samples near uncertain decision boundaries. Facing these challenges, we propose SAGE (Stability-Aware Gradient Efficiency), a dynamic framework designed to enhance alignment reliability by maximizing the Signal-to-Noise Ratio of policy updates. Concretely, SAGE integrates a coarse-grained curriculum mechanism that refreshes candidate pools based on model competence with a fine-grained, stability-aware scoring function that prioritizes informative, confident errors while filtering out unstable samples. Experiments on multiple mathematical reasoning benchmarks demonstrate that SAGE significantly accelerates convergence and outperforms static baselines, highlighting the critical role of policy-aware, stability-conscious data selection in reasoning alignment.
ATLAS: A High-Difficulty, Multidisciplinary Benchmark for Frontier Scientific Reasoning
Nov 18, 2025The rapid advancement of Large Language Models (LLMs) has led to performance saturation on many established benchmarks, questioning their ability to distinguish frontier models. Concurrently, existing high-difficulty benchmarks often suffer from narrow disciplinary focus, oversimplified answer formats, and vulnerability to data contamination, creating a fidelity gap with real-world scientific inquiry. To address these challenges, we introduce ATLAS (AGI-Oriented Testbed for Logical Application in Science), a large-scale, high-difficulty, and cross-disciplinary evaluation suite composed of approximately 800 original problems. Developed by domain experts (PhD-level and above), ATLAS spans seven core scientific fields: mathematics, physics, chemistry, biology, computer science, earth science, and materials science. Its key features include: (1) High Originality and Contamination Resistance, with all questions newly created or substantially adapted to prevent test data leakage; (2) Cross-Disciplinary Focus, designed to assess models' ability to integrate knowledge and reason across scientific domains; (3) High-Fidelity Answers, prioritizing complex, open-ended answers involving multi-step reasoning and LaTeX-formatted expressions over simple multiple-choice questions; and (4) Rigorous Quality Control, employing a multi-stage process of expert peer review and adversarial testing to ensure question difficulty, scientific value, and correctness. We also propose a robust evaluation paradigm using a panel of LLM judges for automated, nuanced assessment of complex answers. Preliminary results on leading models demonstrate ATLAS's effectiveness in differentiating their advanced scientific reasoning capabilities. We plan to develop ATLAS into a long-term, open, community-driven platform to provide a reliable "ruler" for progress toward Artificial General Intelligence.
InfinityStar: Unified Spacetime AutoRegressive Modeling for Visual Generation
Nov 06, 2025We introduce InfinityStar, a unified spacetime autoregressive framework for high-resolution image and dynamic video synthesis. Building on the recent success of autoregressive modeling in both vision and language, our purely discrete approach jointly captures spatial and temporal dependencies within a single architecture. This unified design naturally supports a variety of generation tasks such as text-to-image, text-to-video, image-to-video, and long interactive video synthesis via straightforward temporal autoregression. Extensive experiments demonstrate that InfinityStar scores 83.74 on VBench, outperforming all autoregressive models by large margins, even surpassing some diffusion competitors like HunyuanVideo. Without extra optimizations, our model generates a 5s, 720p video approximately 10x faster than leading diffusion-based methods. To our knowledge, InfinityStar is the first discrete autoregressive video generator capable of producing industrial level 720p videos. We release all code and models to foster further research in efficient, high-quality video generation.
Staying in the Sweet Spot: Responsive Reasoning Evolution via Capability-Adaptive Hint Scaffolding
Sep 08, 2025Reinforcement learning with verifiable rewards (RLVR) has achieved remarkable success in enhancing the reasoning capabilities of large language models (LLMs). However, existing RLVR methods often suffer from exploration inefficiency due to mismatches between the training data's difficulty and the model's capability. LLMs fail to discover viable reasoning paths when problems are overly difficult, while learning little new capability when problems are too simple. In this work, we formalize the impact of problem difficulty by quantifying the relationship between loss descent speed and rollout accuracy. Building on this analysis, we propose SEELE, a novel supervision-aided RLVR framework that dynamically adjusts problem difficulty to stay within the high-efficiency region. SEELE augments each training sample by appending a hint (part of a full solution) after the original problem. Unlike previous hint-based approaches, SEELE deliberately and adaptively adjusts the hint length for each problem to achieve an optimal difficulty. To determine the optimal hint length, SEELE employs a multi-round rollout sampling strategy. In each round, it fits an item response theory model to the accuracy-hint pairs collected in preceding rounds to predict the required hint length for the next round. This instance-level, real-time difficulty adjustment aligns problem difficulty with the evolving model capability, thereby improving exploration efficiency. Experimental results show that SEELE outperforms Group Relative Policy Optimization (GRPO) and Supervised Fine-tuning (SFT) by +11.8 and +10.5 points, respectively, and surpasses the best previous supervision-aided approach by +3.6 points on average across six math reasoning benchmarks.
Retrieval Augmented Learning: A Retrial-based Large Language Model Self-Supervised Learning and Autonomous Knowledge Generation
May 02, 2025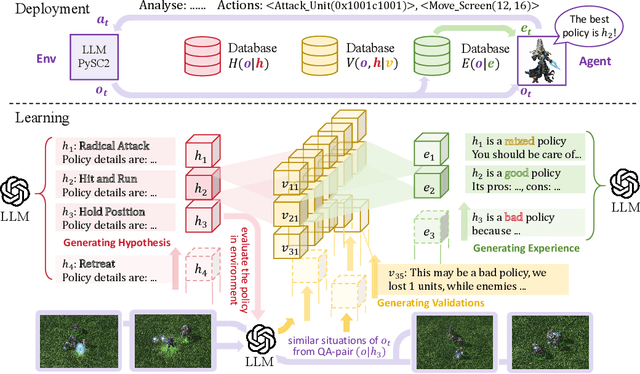


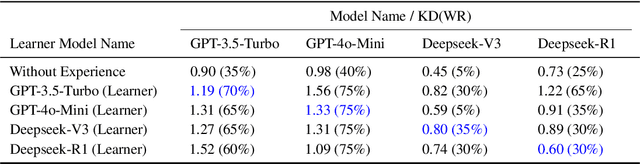
The lack of domain-specific data in the pre-training of Large Language Models (LLMs) severely limits LLM-based decision systems in specialized applications, while post-training a model in the scenarios requires significant computational resources. In this paper, we present Retrial-Augmented Learning (RAL), a reward-free self-supervised learning framework for LLMs that operates without model training. By developing Retrieval-Augmented Generation (RAG) into a module for organizing intermediate data, we realized a three-stage autonomous knowledge generation of proposing a hypothesis, validating the hypothesis, and generating the knowledge. The method is evaluated in the LLM-PySC2 environment, a representative decision-making platform that combines sufficient complexity with domain-specific knowledge requirements. Experiments demonstrate that the proposed method effectively reduces hallucination by generating and utilizing validated knowledge, and increases decision-making performance at an extremely low cost. Meanwhile, the approach exhibits potential in out-of-distribution(OOD) tasks, robustness, and transferability, making it a cost-friendly but effective solution for decision-making problems and autonomous knowledge generation.
BioChemInsight: An Open-Source Toolkit for Automated Identification and Recognition of Optical Chemical Structures and Activity Data in Scientific Publications
Apr 12, 2025Automated extraction of chemical structures and their bioactivity data is crucial for accelerating drug discovery and enabling data-driven pharmaceutical research. Existing optical chemical structure recognition (OCSR) tools fail to autonomously associate molecular structures with their bioactivity profiles, creating a critical bottleneck in structure-activity relationship (SAR) analysis. Here, we present BioChemInsight, an open-source pipeline that integrates: (1) DECIMER Segmentation and MolVec for chemical structure recognition, (2) Qwen2.5-VL-32B for compound identifier association, and (3) PaddleOCR with Gemini-2.0-flash for bioactivity extraction and unit normalization. We evaluated the performance of BioChemInsight on 25 patents and 17 articles. BioChemInsight achieved 95% accuracy for tabular patent data (structure/identifier recognition), with lower accuracy in non-tabular patents (~80% structures, ~75% identifiers), plus 92.2 % bioactivity extraction accuracy. For articles, it attained >99% identifiers and 78-80% structure accuracy in non-tabular formats, plus 97.4% bioactivity extraction accuracy. The system generates ready-to-use SAR datasets, reducing data preprocessing time from weeks to hours while enabling applications in high-throughput screening and ML-driven drug design (https://github.com/dahuilangda/BioChemInsight).
Goku: Flow Based Video Generative Foundation Models
Feb 10, 2025



This paper introduces Goku, a state-of-the-art family of joint image-and-video generation models leveraging rectified flow Transformers to achieve industry-leading performance. We detail the foundational elements enabling high-quality visual generation, including the data curation pipeline, model architecture design, flow formulation, and advanced infrastructure for efficient and robust large-scale training. The Goku models demonstrate superior performance in both qualitative and quantitative evaluations, setting new benchmarks across major tasks. Specifically, Goku achieves 0.76 on GenEval and 83.65 on DPG-Bench for text-to-image generation, and 84.85 on VBench for text-to-video tasks. We believe that this work provides valuable insights and practical advancements for the research community in developing joint image-and-video generation models.