 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative World Renderer
Apr 02, 2026Scaling generative inverse and forward rendering to real-world scenarios is bottlenecked by the limited realism and temporal coherence of existing synthetic datasets. To bridge this persistent domain gap, we introduce a large-scale, dynamic dataset curated from visually complex AAA games. Using a novel dual-screen stitched capture method, we extracted 4M continuous frames (720p/30 FPS) of synchronized RGB and five G-buffer channels across diverse scenes, visual effects, and environments, including adverse weather and motion-blur variants. This dataset uniquely advances bidirectional rendering: enabling robust in-the-wild geometry and material decomposition, and facilitating high-fidelity G-buffer-guided video generation. Furthermore, to evaluate the real-world performance of inverse rendering without ground truth, we propose a novel VLM-based assessment protocol measuring semantic, spatial, and temporal consistency. Experiments demonstrate that inverse renderers fine-tuned on our data achieve superior cross-dataset generalization and controllable generation, while our VLM evaluation strongly correlates with human judgment. Combined with our toolkit, our forward renderer enables users to edit styles of AAA games from G-buffers using text prompts.
Cheers: Decoupling Patch Details from Semantic Representations Enables Unified Multimodal Comprehension and Generation
Mar 13, 2026A recent cutting-edge topic in multimodal modeling is to unify visual comprehension and generation within a single model. However, the two tasks demand mismatched decoding regimes and visual representations, making it non-trivial to jointly optimize within a shared feature space. In this work, we present Cheers, a unified multimodal model that decouples patch-level details from semantic representations, thereby stabilizing semantics for multimodal understanding and improving fidelity for image generation via gated detail residuals. Cheers includes three key components: (i) a unified vision tokenizer that encodes and compresses image latent states into semantic tokens for efficient LLM conditioning, (ii) an LLM-based Transformer that unifies autoregressive decoding for text generation and diffusion decoding for image generation, and (iii) a cascaded flow matching head that decodes visual semantics first and then injects semantically gated detail residuals from the vision tokenizer to refine high-frequency content. Experiments on popular benchmarks demonstrate that Cheers matches or surpasses advanced UMMs in both visual understanding and generation. Cheers also achieves 4x token compression, enabling more efficient high-resolution image encoding and generation. Notably, Cheers outperforms the Tar-1.5B on the popular benchmarks GenEval and MMBench, while requiring only 20% of the training cost, indicating effective and efficient (i.e., 4x token compression) unified multimodal modeling. We will release all code and data for future research.
RAPTOR: Real-Time High-Resolution UAV Video Prediction with Efficient Video Attention
Dec 25, 2025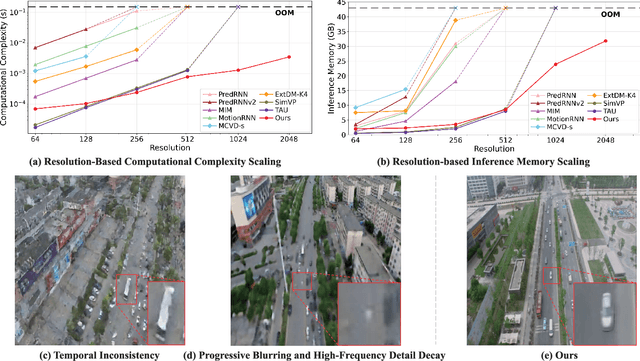



Video prediction is plagued by a fundamental trilemma: achieving high-resolution and perceptual quality typically comes at the cost of real-time speed, hindering its use in latency-critical applications. This challenge is most acute for autonomous UAVs in dense urban environments, where foreseeing events from high-resolution imagery is non-negotiable for safety. Existing methods, reliant on iterative generation (diffusion, autoregressive models) or quadratic-complexity attention, fail to meet these stringent demands on edge hardware. To break this long-standing trade-off, we introduce RAPTOR, a video prediction architecture that achieves real-time, high-resolution performance. RAPTOR's single-pass design avoids the error accumulation and latency of iterative approaches. Its core innovation is Efficient Video Attention (EVA), a novel translator module that factorizes spatiotemporal modeling. Instead of processing flattened spacetime tokens with $O((ST)^2)$ or $O(ST)$ complexity, EVA alternates operations along the spatial (S) and temporal (T) axes. This factorization reduces the time complexity to $O(S + T)$ and memory complexity to $O(max(S, T))$, enabling global context modeling at $512^2$ resolution and beyond, operating directly on dense feature maps with a patch-free design. Complementing this architecture is a 3-stage training curriculum that progressively refines predictions from coarse structure to sharp, temporally coherent details. Experiments show RAPTOR is the first predictor to exceed 30 FPS on a Jetson AGX Orin for $512^2$ video, setting a new state-of-the-art on UAVid, KTH, and a custom high-resolution dataset in PSNR, SSIM, and LPIPS. Critically, RAPTOR boosts the mission success rate in a real-world UAV navigation task by 18/%, paving the way for safer and more anticipatory embodied agents.
ReSeDis: A Dataset for Referring-based Object Search across Large-Scale Image Collections
Jun 18, 2025Large-scale visual search engines are expected to solve a dual problem at once: (i) locate every image that truly contains the object described by a sentence and (ii) identify the object's bounding box or exact pixels within each hit. Existing techniques address only one side of this challenge. Visual grounding yields tight boxes and masks but rests on the unrealistic assumption that the object is present in every test image, producing a flood of false alarms when applied to web-scale collections. Text-to-image retrieval excels at sifting through massive databases to rank relevant images, yet it stops at whole-image matches and offers no fine-grained localization. We introduce Referring Search and Discovery (ReSeDis), the first task that unifies corpus-level retrieval with pixel-level grounding. Given a free-form description, a ReSeDis model must decide whether the queried object appears in each image and, if so, where it is, returning bounding boxes or segmentation masks. To enable rigorous study, we curate a benchmark in which every description maps uniquely to object instances scattered across a large, diverse corpus, eliminating unintended matches. We further design a task-specific metric that jointly scores retrieval recall and localization precision. Finally, we provide a straightforward zero-shot baseline using a frozen vision-language model, revealing significant headroom for future study. ReSeDis offers a realistic, end-to-end testbed for building the next generation of robust and scalable multimodal search systems.
Unveiling Language-Specific Features in Large Language Models via Sparse Autoencoders
May 08, 2025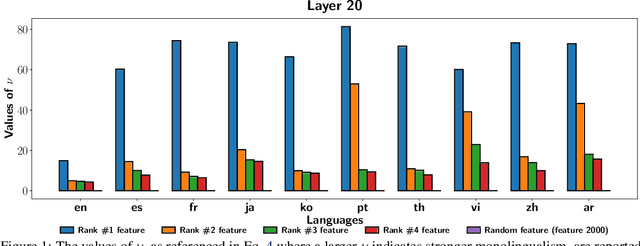
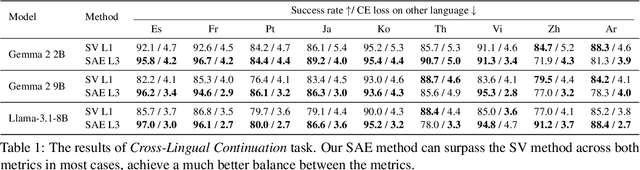
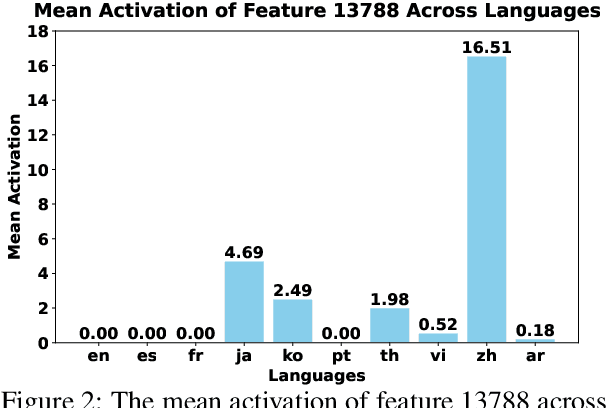
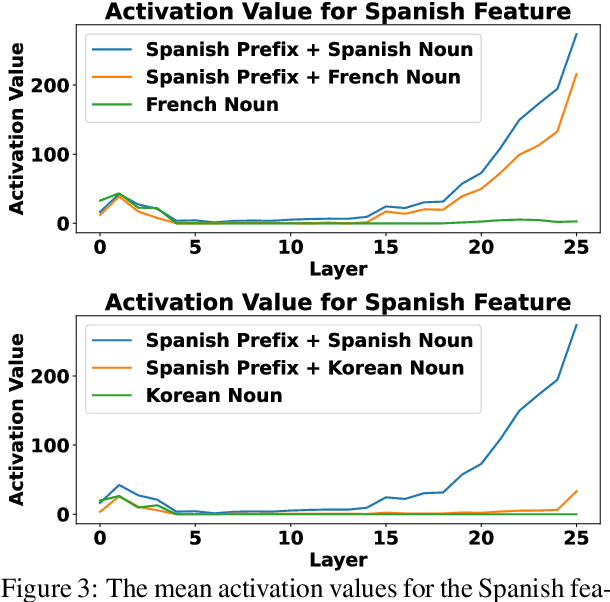
The mechanisms behind multilingual capabilities in Large Language Models (LLMs) have been examined using neuron-based or internal-activation-based methods. However, these methods often face challenges such as superposition and layer-wise activation variance, which limit their reliability. Sparse Autoencoders (SAEs) offer a more nuanced analysis by decomposing the activations of LLMs into sparse linear combination of SAE features. We introduce a novel metric to assess the monolinguality of features obtained from SAEs, discovering that some features are strongly related to specific languages. Additionally, we show that ablating these SAE features only significantly reduces abilities in one language of LLMs, leaving others almost unaffected. Interestingly, we find some languages have multiple synergistic SAE features, and ablating them together yields greater improvement than ablating individually. Moreover, we leverage these SAE-derived language-specific features to enhance steering vectors, achieving control over the language generated by LLMs.
LLaVA-UHD v2: an MLLM Integrating High-Resolution Feature Pyramid via Hierarchical Window Transformer
Dec 18, 2024In multimodal large language models (MLLMs), vision transformers (ViTs) are widely employed for visual encoding. However, their performance in solving universal MLLM tasks is not satisfactory. We attribute it to a lack of information from diverse visual levels, impeding alignment with the various semantic granularity required for language generation. To address this issue, we present LLaVA-UHD v2, an advanced MLLM centered around a Hierarchical window transformer that enables capturing diverse visual granularity by constructing and integrating a high-resolution feature pyramid. As a vision-language projector, Hiwin transformer comprises two primary modules: (i) an inverse feature pyramid, constructed by a ViT-derived feature up-sampling process utilizing high-frequency details from an image pyramid, and (ii) hierarchical window attention, focusing on a set of key sampling features within cross-scale windows to condense multi-level feature maps. Extensive experiments demonstrate that LLaVA-UHD v2 achieves superior performance over existing MLLMs on popular benchmarks. Notably, our design brings an average boost of 3.7% across 14 benchmarks compared with the baseline method, 9.3% on DocVQA for instance. We make all the data, model checkpoint, and code publicly available to facilitate future research.
P-MMEval: A Parallel Multilingual Multitask Benchmark for Consistent Evaluation of LLMs
Nov 14, 2024
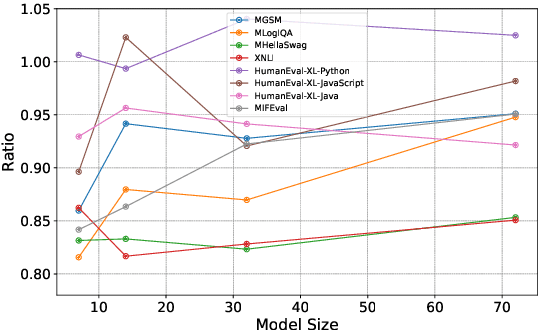


Recent advancements in large language models (LLMs) showcase varied multilingual capabilities across tasks like translation, code generation, and reasoning. Previous assessments often limited their scope to fundamental natural language processing (NLP) or isolated capability-specific tasks. To alleviate this drawback, we aim to present a comprehensive multilingual multitask benchmark. First, we present a pipeline for selecting available and reasonable benchmarks from massive ones, addressing the oversight in previous work regarding the utility of these benchmarks, i.e., their ability to differentiate between models being evaluated. Leveraging this pipeline, we introduce P-MMEval, a large-scale benchmark covering effective fundamental and capability-specialized datasets. Furthermore, P-MMEval delivers consistent language coverage across various datasets and provides parallel samples. Finally, we conduct extensive experiments on representative multilingual model series to compare performances across models, analyze dataset effectiveness, examine prompt impacts on model performances, and explore the relationship between multilingual performances and factors such as tasks, model sizes, and languages. These insights offer valuable guidance for future research. The dataset is available at https://huggingface.co/datasets/Qwen/P-MMEval.
Self-guided Few-shot Semantic Segmentation for Remote Sensing Imagery Based on Large Vision Models
Nov 22, 2023

The Segment Anything Model (SAM) exhibits remarkable versatility and zero-shot learning abilities, owing largely to its extensive training data (SA-1B). Recognizing SAM's dependency on manual guidance given its category-agnostic nature, we identified unexplored potential within few-shot semantic segmentation tasks for remote sensing imagery. This research introduces a structured framework designed for the automation of few-shot semantic segmentation. It utilizes the SAM model and facilitates a more efficient generation of semantically discernible segmentation outcomes. Central to our methodology is a novel automatic prompt learning approach, leveraging prior guided masks to produce coarse pixel-wise prompts for SAM. Extensive experiments on the DLRSD datasets underline the superiority of our approach, outperforming other available few-shot methodologies.
HeightFormer: A Multilevel Interaction and Image-adaptive Classification-regression Network for Monocular Height Estimation with Aerial Images
Oct 12, 2023



Height estimation has long been a pivotal topic within measurement and remote sensing disciplines, proving critical for endeavours such as 3D urban modelling, MR and autonomous driving. Traditional methods utilise stereo matching or multisensor fusion, both well-established techniques that typically necessitate multiple images from varying perspectives and adjunct sensors like SAR, leading to substantial deployment costs. Single image height estimation has emerged as an attractive alternative, boasting a larger data source variety and simpler deployment. However, current methods suffer from limitations such as fixed receptive fields, a lack of global information interaction, leading to noticeable instance-level height deviations. The inherent complexity of height prediction can result in a blurry estimation of object edge depth when using mainstream regression methods based on fixed height division. This paper presents a comprehensive solution for monocular height estimation in remote sensing, termed HeightFormer, combining multilevel interactions and image-adaptive classification-regression. It features the Multilevel Interaction Backbone (MIB) and Image-adaptive Classification-regression Height Generator (ICG). MIB supplements the fixed sample grid in CNN of the conventional backbone network with tokens of different interaction ranges. It is complemented by a pixel-, patch-, and feature map-level hierarchical interaction mechanism, designed to relay spatial geometry information across different scales and introducing a global receptive field to enhance the quality of instance-level height estimation. The ICG dynamically generates height partition for each image and reframes the traditional regression task, using a refinement from coarse to fine classification-regression that significantly mitigates the innate ill-posedness issue and drastically improves edge sharpness.
IRGen: Generative Modeling for Image Retrieval
Mar 27, 2023While generative modeling has been ubiquitous in natural language processing and computer vision, its application to image retrieval remains unexplored. In this paper, we recast image retrieval as a form of generative modeling by employing a sequence-to-sequence model, contributing to the current unified theme. Our framework, IRGen, is a unified model that enables end-to-end differentiable search, thus achieving superior performance thanks to direct optimization. While developing IRGen we tackle the key technical challenge of converting an image into quite a short sequence of semantic units in order to enable efficient and effective retrieval. Empirical experiments demonstrate that our model yields significant improvement over three commonly used benchmarks, for example, 22.9\% higher than the best baseline method in precision@10 on In-shop dataset with comparable recall@10 score.