 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Knows Transparency: Repurposing Video Diffusion for Transparent Object Depth and Normal Estimation
Dec 29, 2025Transparent objects remain notoriously hard for perception systems: refraction, reflection and transmission break the assumptions behind stereo, ToF and purely discriminative monocular depth, causing holes and temporally unstable estimates. Our key observation is that modern video diffusion models already synthesize convincing transparent phenomena, suggesting they have internalized the optical rules. We build TransPhy3D, a synthetic video corpus of transparent/reflective scenes: 11k sequences rendered with Blender/Cycles. Scenes are assembled from a curated bank of category-rich static assets and shape-rich procedural assets paired with glass/plastic/metal materials. We render RGB + depth + normals with physically based ray tracing and OptiX denoising. Starting from a large video diffusion model, we learn a video-to-video translator for depth (and normals) via lightweight LoRA adapters. During training we concatenate RGB and (noisy) depth latents in the DiT backbone and co-train on TransPhy3D and existing frame-wise synthetic datasets, yielding temporally consistent predictions for arbitrary-length input videos. The resulting model, DKT, achieves zero-shot SOTA on real and synthetic video benchmarks involving transparency: ClearPose, DREDS (CatKnown/CatNovel), and TransPhy3D-Test. It improves accuracy and temporal consistency over strong image/video baselines, and a normal variant sets the best video normal estimation results on ClearPose. A compact 1.3B version runs at ~0.17 s/frame. Integrated into a grasping stack, DKT's depth boosts success rates across translucent, reflective and diffuse surfaces, outperforming prior estimators. Together, these results support a broader claim: "Diffusion knows transparency." Generative video priors can be repurposed, efficiently and label-free, into robust, temporally coherent perception for challenging real-world manipulation.
UniPart: Part-Level 3D Generation with Unified 3D Geom-Seg Latents
Dec 10, 2025Part-level 3D generation is essential for applications requiring decomposable and structured 3D synthesis. However, existing methods either rely on implicit part segmentation with limited granularity control or depend on strong external segmenters trained on large annotated datasets. In this work, we observe that part awareness emerges naturally during whole-object geometry learning and propose Geom-Seg VecSet, a unified geometry-segmentation latent representation that jointly encodes object geometry and part-level structure. Building on this representation, we introduce UniPart, a two-stage latent diffusion framework for image-guided part-level 3D generation. The first stage performs joint geometry generation and latent part segmentation, while the second stage conditions part-level diffusion on both whole-object and part-specific latents. A dual-space generation scheme further enhances geometric fidelity by predicting part latents in both global and canonical spaces. Extensive experiments demonstrate that UniPart achieves superior segmentation controllability and part-level geometric quality compared with existing approaches.
LoFA: Learning to Predict Personalized Priors for Fast Adaptation of Visual Generative Models
Dec 09, 2025Personalizing visual generative models to meet specific user needs has gained increasing attention, yet current methods like Low-Rank Adaptation (LoRA) remain impractical due to their demand for task-specific data and lengthy optimization. While a few hypernetwork-based approaches attempt to predict adaptation weights directly, they struggle to map fine-grained user prompts to complex LoRA distributions, limiting their practical applicability. To bridge this gap, we propose LoFA, a general framework that efficiently predicts personalized priors for fast model adaptation. We first identify a key property of LoRA: structured distribution patterns emerge in the relative changes between LoRA and base model parameters. Building on this, we design a two-stage hypernetwork: first predicting relative distribution patterns that capture key adaptation regions, then using these to guide final LoRA weight prediction. Extensive experiments demonstrate that our method consistently predicts high-quality personalized priors within seconds, across multiple tasks and user prompts, even outperforming conventional LoRA that requires hours of processing. Project page: https://jaeger416.github.io/lofa/.
One View, Many Worlds: Single-Image to 3D Object Meets Generative Domain Randomization for One-Shot 6D Pose Estimation
Sep 09, 2025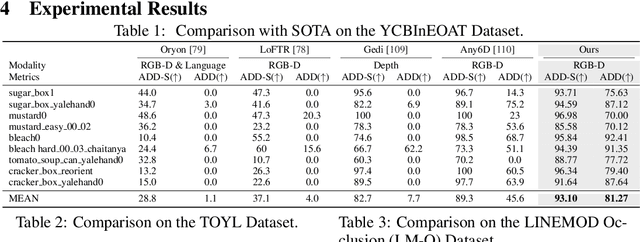
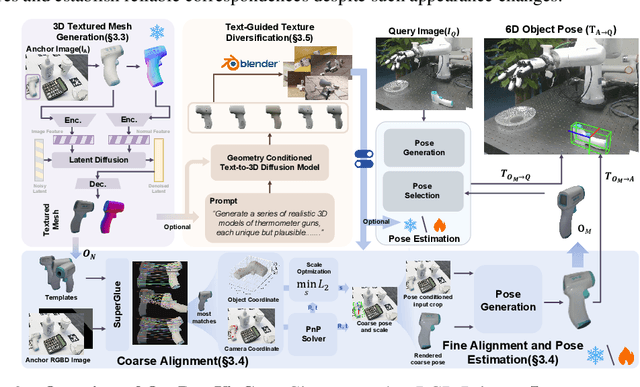
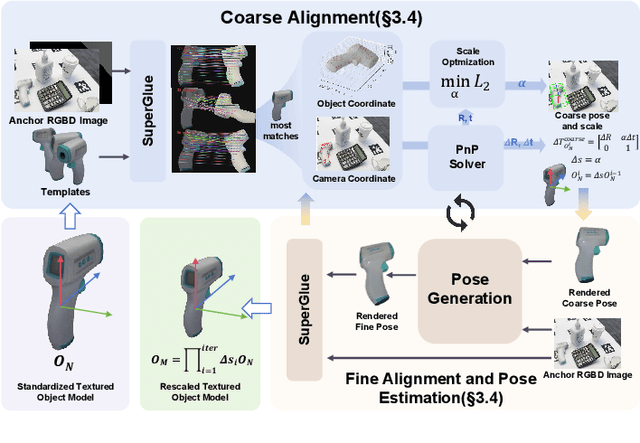
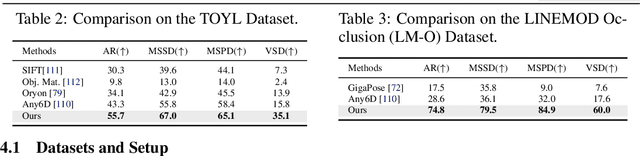
Estimating the 6D pose of arbitrary unseen objects from a single reference image is critical for robotics operating in the long-tail of real-world instances. However, this setting is notoriously challenging: 3D models are rarely available, single-view reconstructions lack metric scale, and domain gaps between generated models and real-world images undermine robustness. We propose OnePoseViaGen, a pipeline that tackles these challenges through two key components. First, a coarse-to-fine alignment module jointly refines scale and pose by combining multi-view feature matching with render-and-compare refinement. Second, a text-guided generative domain randomization strategy diversifies textures, enabling effective fine-tuning of pose estimators with synthetic data. Together, these steps allow high-fidelity single-view 3D generation to support reliable one-shot 6D pose estimation. On challenging benchmarks (YCBInEOAT, Toyota-Light, LM-O), OnePoseViaGen achieves state-of-the-art performance far surpassing prior approaches. We further demonstrate robust dexterous grasping with a real robot hand, validating the practicality of our method in real-world manipulation. Project page: https://gzwsama.github.io/OnePoseviaGen.github.io/
Light of Normals: Unified Feature Representation for Universal Photometric Stereo
Jun 24, 2025
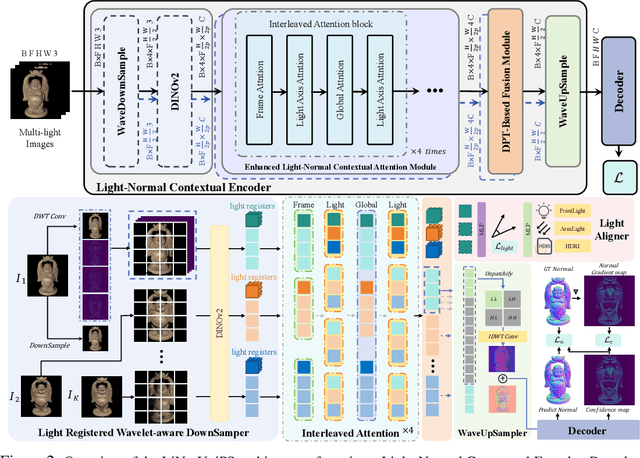
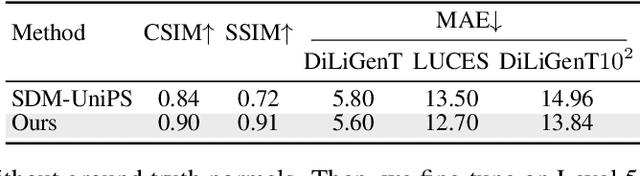

Universal photometric stereo (PS) aims to recover high-quality surface normals from objects under arbitrary lighting conditions without relying on specific illumination models. Despite recent advances such as SDM-UniPS and Uni MS-PS, two fundamental challenges persist: 1) the deep coupling between varying illumination and surface normal features, where ambiguity in observed intensity makes it difficult to determine whether brightness variations stem from lighting changes or surface orientation; and 2) the preservation of high-frequency geometric details in complex surfaces, where intricate geometries create self-shadowing, inter-reflections, and subtle normal variations that conventional feature processing operations struggle to capture accurately.
Unifying Appearance Codes and Bilateral Grids for Driving Scene Gaussian Splatting
Jun 06, 2025Neural rendering techniques, including NeRF and Gaussian Splatting (GS), rely on photometric consistency to produce high-quality reconstructions. However, in real-world scenarios, it is challenging to guarantee perfect photometric consistency in acquired images. Appearance codes have been widely used to address this issue, but their modeling capability is limited, as a single code is applied to the entire image. Recently, the bilateral grid was introduced to perform pixel-wise color mapping, but it is difficult to optimize and constrain effectively. In this paper, we propose a novel multi-scale bilateral grid that unifies appearance codes and bilateral grids. We demonstrate that this approach significantly improves geometric accuracy in dynamic, decoupled autonomous driving scene reconstruction, outperforming both appearance codes and bilateral grids. This is crucial for autonomous driving, where accurate geometry is important for obstacle avoidance and control. Our method shows strong results across four datasets: Waymo, NuScenes, Argoverse, and PandaSet. We further demonstrate that the improvement in geometry is driven by the multi-scale bilateral grid, which effectively reduces floaters caused by photometric inconsistency.
Hi3DGen: High-fidelity 3D Geometry Generation from Images via Normal Bridging
Mar 31, 2025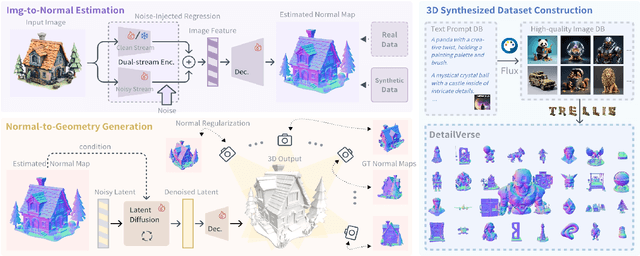
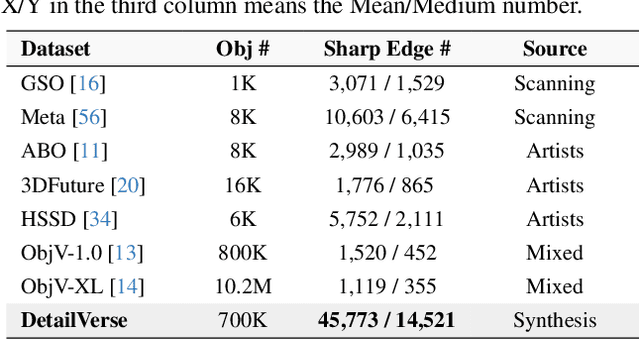
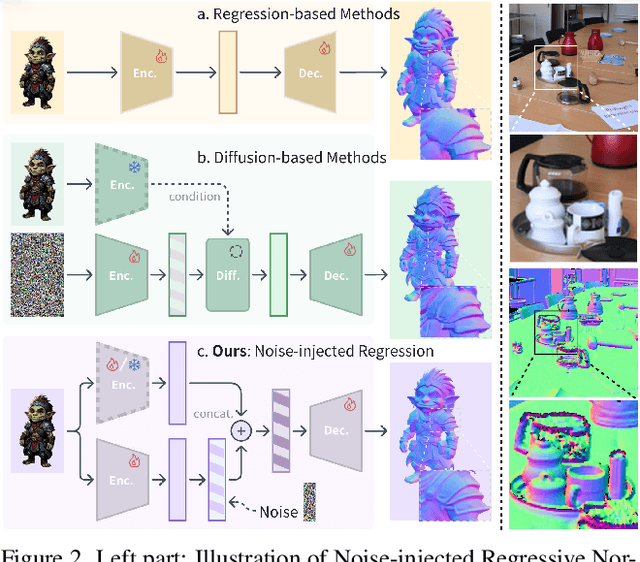
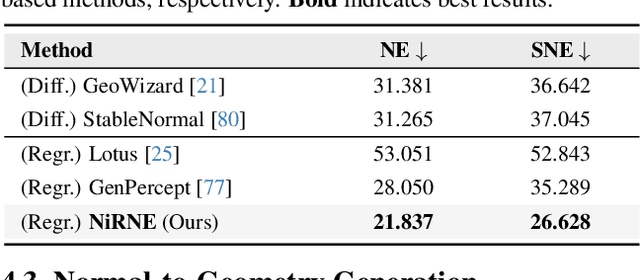
With the growing demand for high-fidelity 3D models from 2D images, existing methods still face significant challenges in accurately reproducing fine-grained geometric details due to limitations in domain gaps and inherent ambiguities in RGB images. To address these issues, we propose Hi3DGen, a novel framework for generating high-fidelity 3D geometry from images via normal bridging. Hi3DGen consists of three key components: (1) an image-to-normal estimator that decouples the low-high frequency image pattern with noise injection and dual-stream training to achieve generalizable, stable, and sharp estimation; (2) a normal-to-geometry learning approach that uses normal-regularized latent diffusion learning to enhance 3D geometry generation fidelity; and (3) a 3D data synthesis pipeline that constructs a high-quality dataset to support training. Extensive experiments demonstrate the effectiveness and superiority of our framework in generating rich geometric details, outperforming state-of-the-art methods in terms of fidelity. Our work provides a new direction for high-fidelity 3D geometry generation from images by leveraging normal maps as an intermediate representation.
OccluGaussian: Occlusion-Aware Gaussian Splatting for Large Scene Reconstruction and Rendering
Mar 20, 2025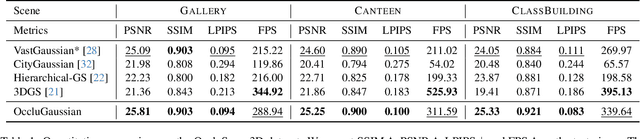
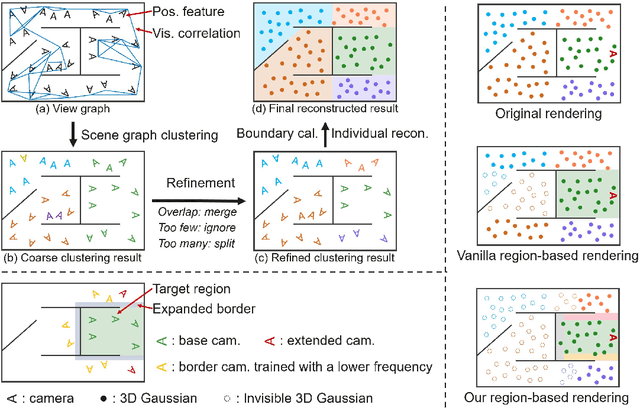
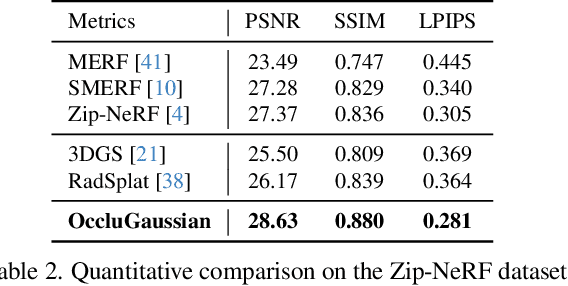
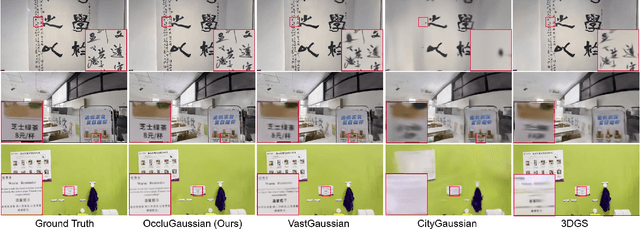
In large-scale scene reconstruction using 3D Gaussian splatting, it is common to partition the scene into multiple smaller regions and reconstruct them individually. However, existing division methods are occlusion-agnostic, meaning that each region may contain areas with severe occlusions. As a result, the cameras within those regions are less correlated, leading to a low average contribution to the overall reconstruction. In this paper, we propose an occlusion-aware scene division strategy that clusters training cameras based on their positions and co-visibilities to acquire multiple regions. Cameras in such regions exhibit stronger correlations and a higher average contribution, facilitating high-quality scene reconstruction. We further propose a region-based rendering technique to accelerate large scene rendering, which culls Gaussians invisible to the region where the viewpoint is located. Such a technique significantly speeds up the rendering without compromising quality. Extensive experiments on multiple large scenes show that our method achieves superior reconstruction results with faster rendering speed compared to existing state-of-the-art approaches. Project page: https://occlugaussian.github.io.
StableNormal: Reducing Diffusion Variance for Stable and Sharp Normal
Jun 24, 2024


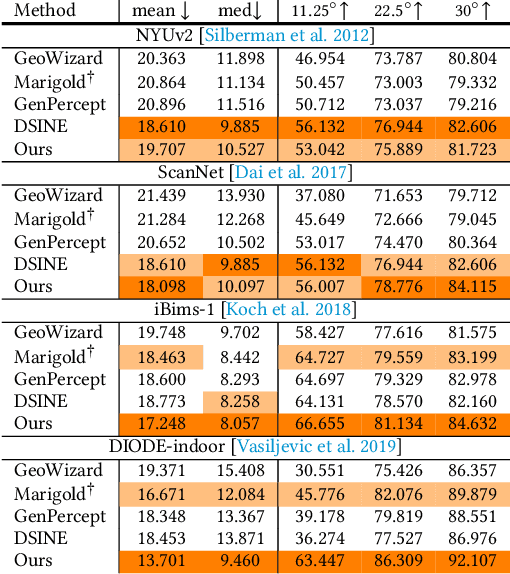
This work addresses the challenge of high-quality surface normal estimation from monocular colored inputs (i.e., images and videos), a field which has recently been revolutionized by repurposing diffusion priors. However, previous attempts still struggle with stochastic inference, conflicting with the deterministic nature of the Image2Normal task, and costly ensembling step, which slows down the estimation process. Our method, StableNormal, mitigates the stochasticity of the diffusion process by reducing inference variance, thus producing "Stable-and-Sharp" normal estimates without any additional ensembling process. StableNormal works robustly under challenging imaging conditions, such as extreme lighting, blurring, and low quality. It is also robust against transparent and reflective surfaces, as well as cluttered scenes with numerous objects. Specifically, StableNormal employs a coarse-to-fine strategy, which starts with a one-step normal estimator (YOSO) to derive an initial normal guess, that is relatively coarse but reliable, then followed by a semantic-guided refinement process (SG-DRN) that refines the normals to recover geometric details. The effectiveness of StableNormal is demonstrated through competitive performance in standard datasets such as DIODE-indoor, iBims, ScannetV2 and NYUv2, and also in various downstream tasks, such as surface reconstruction and normal enhancement. These results evidence that StableNormal retains both the "stability" and "sharpness" for accurate normal estimation. StableNormal represents a baby attempt to repurpose diffusion priors for deterministic estimation. To democratize this, code and models have been publicly available in hf.co/Stable-X
GauStudio: A Modular Framework for 3D Gaussian Splatting and Beyond
Mar 28, 2024We present GauStudio, a novel modular framework for modeling 3D Gaussian Splatting (3DGS) to provide standardized, plug-and-play components for users to easily customize and implement a 3DGS pipeline. Supported by our framework, we propose a hybrid Gaussian representation with foreground and skyball background models. Experiments demonstrate this representation reduces artifacts in unbounded outdoor scenes and improves novel view synthesis. Finally, we propose Gaussian Splatting Surface Reconstruction (GauS), a novel render-then-fuse approach for high-fidelity mesh reconstruction from 3DGS inputs without fine-tuning. Overall, our GauStudio framework, hybrid representation, and GauS approach enhance 3DGS modeling and rendering capabilities, enabling higher-quality novel view synthesis and surface reconstruction.