 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable-SCore: A Stable Registration-based Framework for 3D Shape Correspondence
Mar 27, 2025



Establishing character shape correspondence is a critical and fundamental task in computer vision and graphics, with diverse applications including re-topology, attribute transfer, and shape interpolation. Current dominant functional map methods, while effective in controlled scenarios, struggle in real situations with more complex challenges such as non-isometric shape discrepancies. In response, we revisit registration-for-correspondence methods and tap their potential for more stable shape correspondence estimation. To overcome their common issues including unstable deformations and the necessity for careful pre-alignment or high-quality initial 3D correspondences, we introduce Stable-SCore: A Stable Registration-based Framework for 3D Shape Correspondence. We first re-purpose a foundation model for 2D character correspondence that ensures reliable and stable 2D mappings. Crucially, we propose a novel Semantic Flow Guided Registration approach that leverages 2D correspondence to guide mesh deformations. Our framework significantly surpasses existing methods in challenging scenarios, and brings possibilities for a wide array of real applications, as demonstrated in our results.
DreamDissector: Learning Disentangled Text-to-3D Generation from 2D Diffusion Priors
Jul 23, 2024
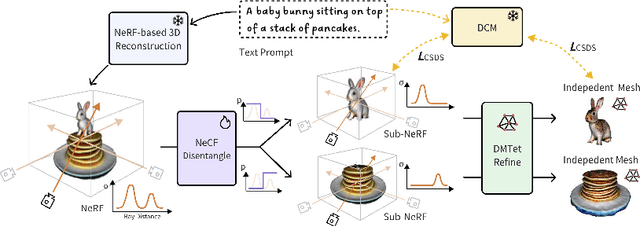
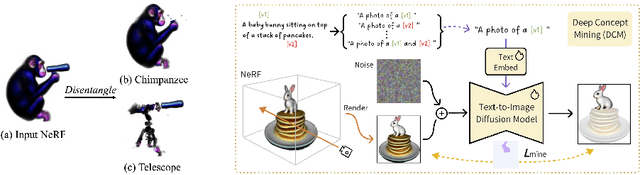

Text-to-3D generation has recently seen significant progress. To enhance its practicality in real-world applications, it is crucial to generate multiple independent objects with interactions, similar to layer-compositing in 2D image editing. However, existing text-to-3D methods struggle with this task, as they are designed to generate either non-independent objects or independent objects lacking spatially plausible interactions. Addressing this, we propose DreamDissector, a text-to-3D method capable of generating multiple independent objects with interactions. DreamDissector accepts a multi-object text-to-3D NeRF as input and produces independent textured meshes. To achieve this, we introduce the Neural Category Field (NeCF) for disentangling the input NeRF. Additionally, we present the Category Score Distillation Sampling (CSDS), facilitated by a Deep Concept Mining (DCM) module, to tackle the concept gap issue in diffusion models. By leveraging NeCF and CSDS, we can effectively derive sub-NeRFs from the original scene. Further refinement enhances geometry and texture. Our experimental results validate the effectiveness of DreamDissector, providing users with novel means to control 3D synthesis at the object level and potentially opening avenues for various creative applications in the future.
Universal Semi-supervised Model Adaptation via Collaborative Consistency Training
Jul 07, 2023In this paper, we introduce a realistic and challenging domain adaptation problem called Universal Semi-supervised Model Adaptation (USMA), which i) requires only a pre-trained source model, ii) allows the source and target domain to have different label sets, i.e., they share a common label set and hold their own private label set, and iii) requires only a few labeled samples in each class of the target domain. To address USMA, we propose a collaborative consistency training framework that regularizes the prediction consistency between two models, i.e., a pre-trained source model and its variant pre-trained with target data only, and combines their complementary strengths to learn a more powerful model. The rationale of our framework stems from the observation that the source model performs better on common categories than the target-only model, while on target-private categories, the target-only model performs better. We also propose a two-perspective, i.e., sample-wise and class-wise, consistency regularization to improve the training. Experimental results demonstrate the effectiveness of our method on several benchmark datasets.
SCoDA: Domain Adaptive Shape Completion for Real Scans
Apr 24, 20233D shape completion from point clouds is a challenging task, especially from scans of real-world objects. Considering the paucity of 3D shape ground truths for real scans, existing works mainly focus on benchmarking this task on synthetic data, e.g. 3D computer-aided design models. However, the domain gap between synthetic and real data limits the generalizability of these methods. Thus, we propose a new task, SCoDA, for the domain adaptation of real scan shape completion from synthetic data. A new dataset, ScanSalon, is contributed with a bunch of elaborate 3D models created by skillful artists according to scans. To address this new task, we propose a novel cross-domain feature fusion method for knowledge transfer and a novel volume-consistent self-training framework for robust learning from real data. Extensive experiments prove our method is effective to bring an improvement of 6%~7% mIoU.
MVImgNet: A Large-scale Dataset of Multi-view Images
Mar 10, 2023



Being data-driven is one of the most iconic properties of deep learning algorithms. The birth of ImageNet drives a remarkable trend of "learning from large-scale data" in computer vision. Pretraining on ImageNet to obtain rich universal representations has been manifested to benefit various 2D visual tasks, and becomes a standard in 2D vision. However, due to the laborious collection of real-world 3D data, there is yet no generic dataset serving as a counterpart of ImageNet in 3D vision, thus how such a dataset can impact the 3D community is unraveled. To remedy this defect, we introduce MVImgNet, a large-scale dataset of multi-view images, which is highly convenient to gain by shooting videos of real-world objects in human daily life. It contains 6.5 million frames from 219,188 videos crossing objects from 238 classes, with rich annotations of object masks, camera parameters, and point clouds. The multi-view attribute endows our dataset with 3D-aware signals, making it a soft bridge between 2D and 3D vision. We conduct pilot studies for probing the potential of MVImgNet on a variety of 3D and 2D visual tasks, including radiance field reconstruction, multi-view stereo, and view-consistent image understanding, where MVImgNet demonstrates promising performance, remaining lots of possibilities for future explorations. Besides, via dense reconstruction on MVImgNet, a 3D object point cloud dataset is derived, called MVPNet, covering 87,200 samples from 150 categories, with the class label on each point cloud. Experiments show that MVPNet can benefit the real-world 3D object classification while posing new challenges to point cloud understanding. MVImgNet and MVPNet will be publicly available, hoping to inspire the broader vision community.
Multi-level Consistency Learning for Semi-supervised Domain Adaptation
May 09, 2022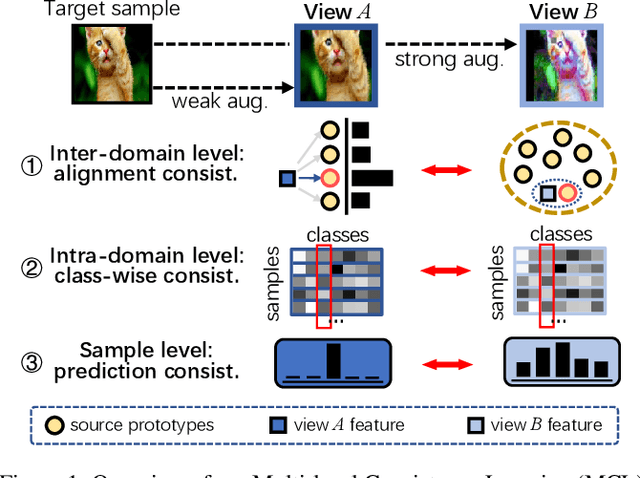
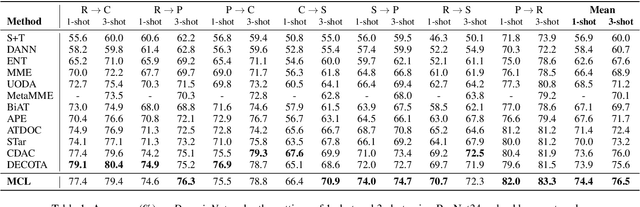
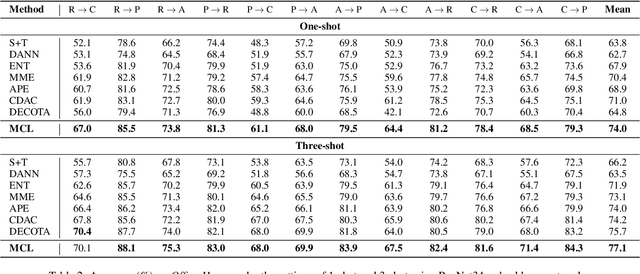
Semi-supervised domain adaptation (SSDA) aims to apply knowledge learned from a fully labeled source domain to a scarcely labeled target domain. In this paper, we propose a Multi-level Consistency Learning (MCL) framework for SSDA. Specifically, our MCL regularizes the consistency of different views of target domain samples at three levels: (i) at inter-domain level, we robustly and accurately align the source and target domains using a prototype-based optimal transport method that utilizes the pros and cons of different views of target samples; (ii) at intra-domain level, we facilitate the learning of both discriminative and compact target feature representations by proposing a novel class-wise contrastive clustering loss; (iii) at sample level, we follow standard practice and improve the prediction accuracy by conducting a consistency-based self-training. Empirically, we verified the effectiveness of our MCL framework on three popular SSDA benchmarks, i.e., VisDA2017, DomainNet, and Office-Home datasets, and the experimental results demonstrate that our MCL framework achieves the state-of-the-art performance.
PointMatch: A Consistency Training Framework for Weakly SupervisedSemantic Segmentation of 3D Point Clouds
Feb 22, 2022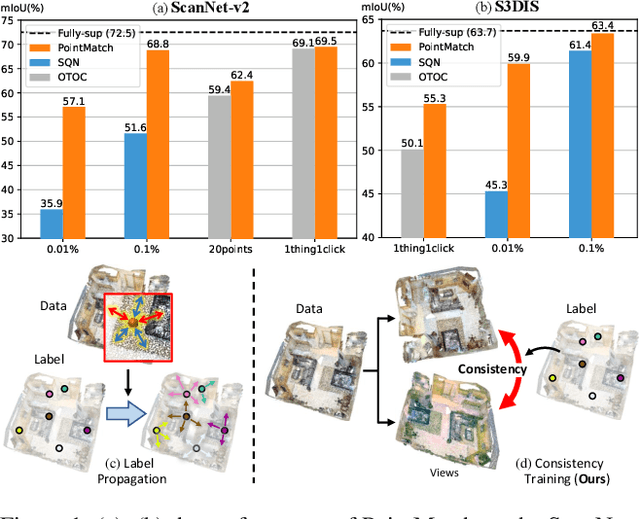
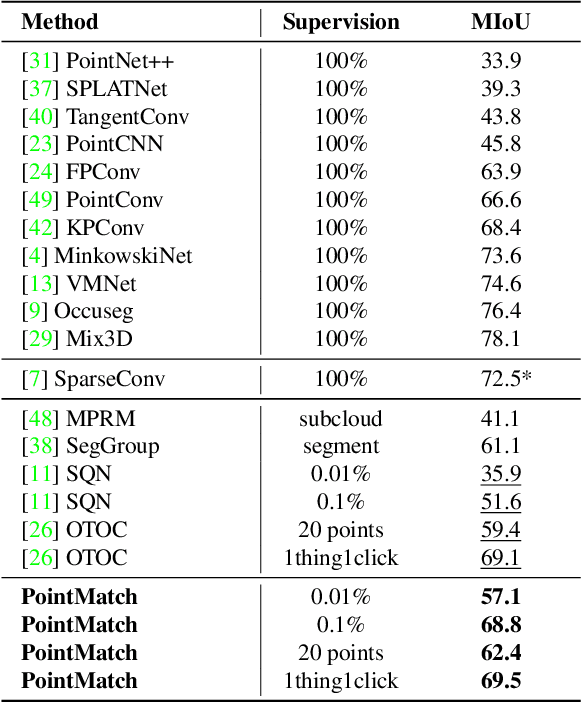
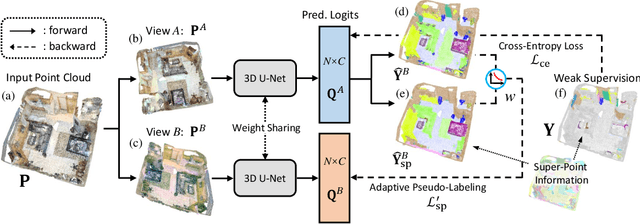
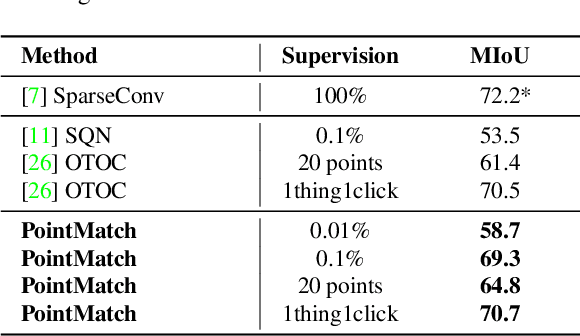
Semantic segmentation of point cloud usually relies on dense annotation that is exhausting and costly, so it attracts wide attention to investigate solutions for the weakly supervised scheme with only sparse points annotated. Existing works start from the given labels and propagate them to highly-related but unlabeled points, with the guidance of data, e.g. intra-point relation. However, it suffers from (i) the inefficient exploitation of data information, and (ii) the strong reliance on labels thus is easily suppressed when given much fewer annotations. Therefore, we propose a novel framework, PointMatch, that stands on both data and label, by applying consistency regularization to sufficiently probe information from data itself and leveraging weak labels as assistance at the same time. By doing so, meaningful information can be learned from both data and label for better representation learning, which also enables the model more robust to the extent of label sparsity. Simple yet effective, the proposed PointMatch achieves the state-of-the-art performance under various weakly-supervised schemes on both ScanNet-v2 and S3DIS datasets, especially on the settings with extremely sparse labels, e.g. surpassing SQN by 21.2% and 17.2% on the 0.01% and 0.1% setting of ScanNet-v2, respectively.
FPConv: Learning Local Flattening for Point Convolution
Mar 14, 2020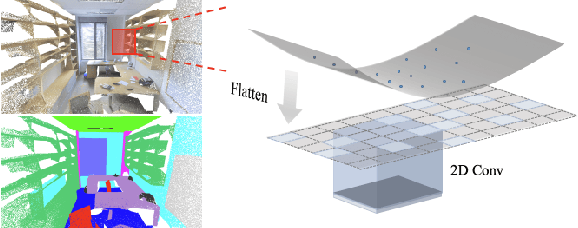
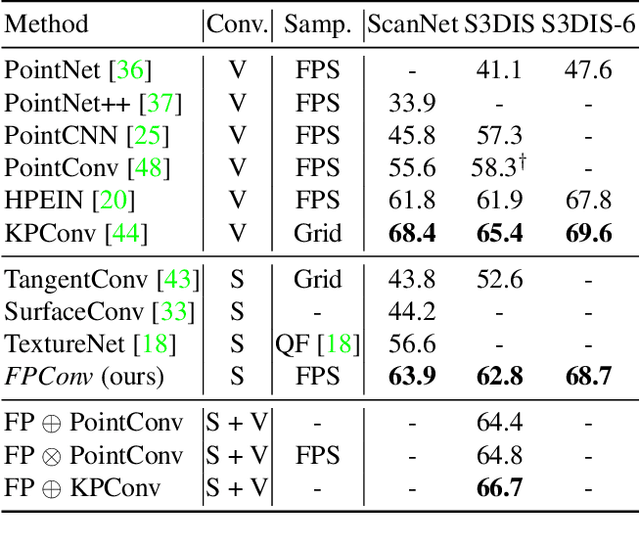
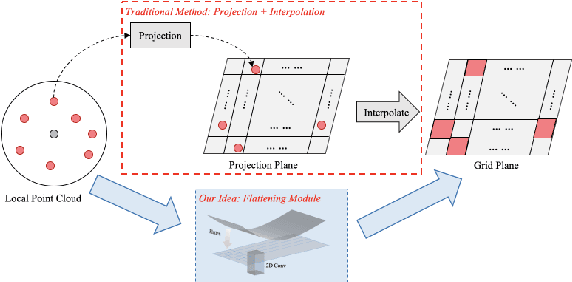
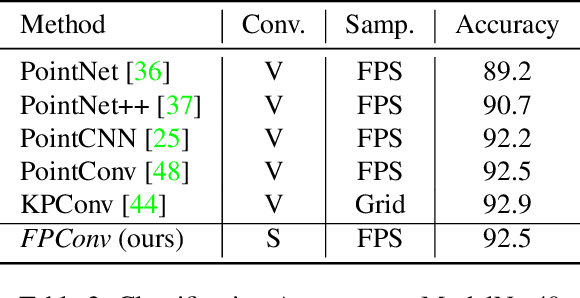
We introduce FPConv, a novel surface-style convolution operator designed for 3D point cloud analysis. Unlike previous methods, FPConv doesn't require transforming to intermediate representation like 3D grid or graph and directly works on surface geometry of point cloud. To be more specific, for each point, FPConv performs a local flattening by automatically learning a weight map to softly project surrounding points onto a 2D grid. Regular 2D convolution can thus be applied for efficient feature learning. FPConv can be easily integrated into various network architectures for tasks like 3D object classification and 3D scene segmentation, and achieve comparable performance with existing volumetric-type convolutions. More importantly, our experiments also show that FPConv can be a complementary of volumetric convolutions and jointly training them can further boost overall performance into state-of-the-art results.
How Effectively Can Indoor Wireless Positioning Relieve Visual Tracking Pains: A Camera-Rao Bound Viewpoint
Mar 09, 2019


Visual tracking is fragile in some difficult scenarios, for instance, appearance ambiguity and variation, occlusion can easily degrade most of visual trackers to some extent. In this paper, visual tracking is empowered with wireless positioning to achieve high accuracy while maintaining robustness. Fundamentally different from the previous works, this study does not involve any specific wireless positioning algorithms. Instead, we use the confidence region derived from the wireless positioning Cramer-Rao bound (CRB) as the search region of visual trackers. The proposed framework is low-cost and very simple to implement, yet readily leads to enhanced and robustified visual tracking performance in difficult scenarios as corroborated by our experimental results. Most importantly, it is utmost valuable for the practioners to pre-evaluate how effectively can the wireless resources available at hand alleviate the visual tracking pains.
Learning Mutually Local-global U-nets For High-resolution Retinal Lesion Segmentation in Fundus Images
Jan 18, 2019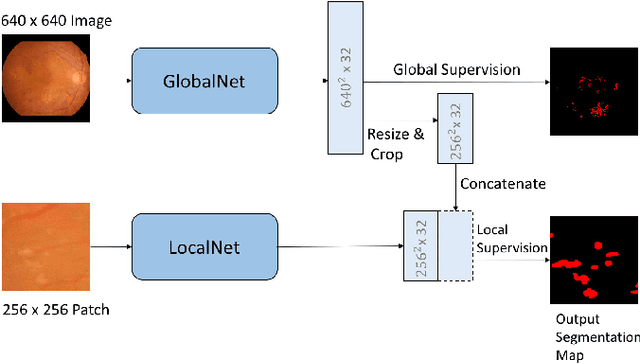
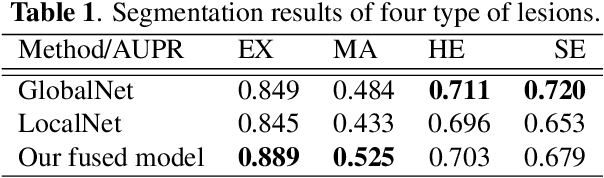


Diabetic retinopathy is the most important complication of diabetes. Early diagnosis of retinal lesions helps to avoid visual loss or blindness. Due to high-resolution and small-size lesion regions, applying existing methods, such as U-Nets, to perform segmentation on fundus photography is very challenging. Although downsampling the input images could simplify the problem, it loses detailed information. Conducting patch-level analysis helps reaching fine-scale segmentation yet usually leads to misunderstanding as the lack of context information. In this paper, we propose an efficient network that combines them together, not only being aware of local details but also taking fully use of the context perceptions. This is implemented by integrating the decoder parts of a global-level U-net and a patch-level one. The two streams are jointly optimized, ensuring that they are enhanced mutually. Experimental results demonstrate our new framework significantly outperforms existing patch-based and global-based methods, especially when the lesion regions are scattered and small-scaled.