 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaBit: Parametric Modeling of 3D Biped Cartoon Characters with a Topological-consistent Dataset
Mar 24, 2023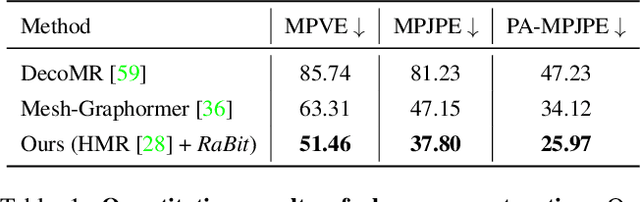


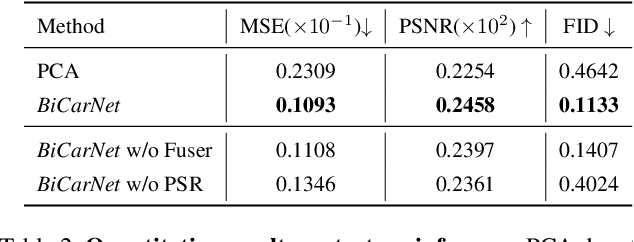
Assisting people in efficiently producing visually plausible 3D characters has always been a fundamental research topic in computer vision and computer graphics. Recent learning-based approaches have achieved unprecedented accuracy and efficiency in the area of 3D real human digitization. However, none of the prior works focus on modeling 3D biped cartoon characters, which are also in great demand in gaming and filming. In this paper, we introduce 3DBiCar, the first large-scale dataset of 3D biped cartoon characters, and RaBit, the corresponding parametric model. Our dataset contains 1,500 topologically consistent high-quality 3D textured models which are manually crafted by professional artists. Built upon the data, RaBit is thus designed with a SMPL-like linear blend shape model and a StyleGAN-based neural UV-texture generator, simultaneously expressing the shape, pose, and texture. To demonstrate the practicality of 3DBiCar and RaBit, various applications are conducted, including single-view reconstruction, sketch-based modeling, and 3D cartoon animation. For the single-view reconstruction setting, we find a straightforward global mapping from input images to the output UV-based texture maps tends to lose detailed appearances of some local parts (e.g., nose, ears). Thus, a part-sensitive texture reasoner is adopted to make all important local areas perceived. Experiments further demonstrate the effectiveness of our method both qualitatively and quantitatively. 3DBiCar and RaBit are available at gaplab.cuhk.edu.cn/projects/RaBit.
PointMatch: A Consistency Training Framework for Weakly SupervisedSemantic Segmentation of 3D Point Clouds
Feb 22, 2022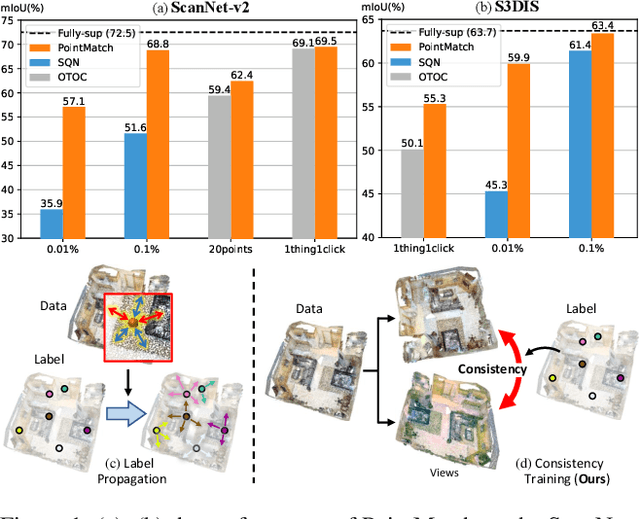
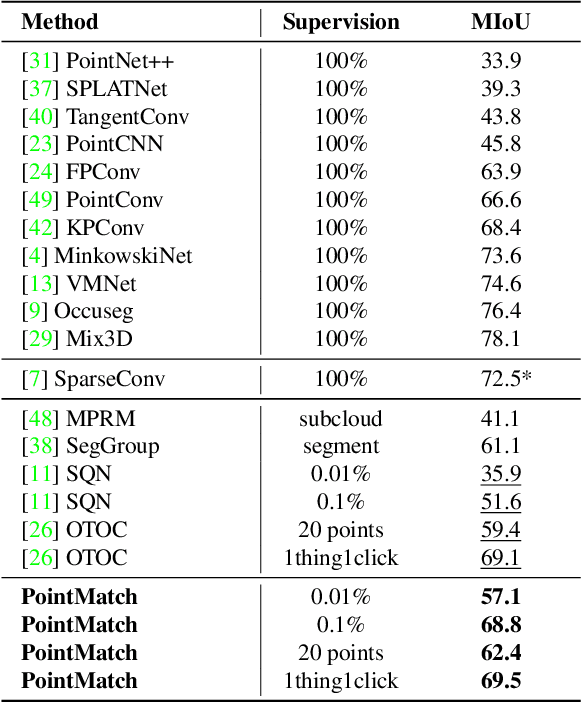
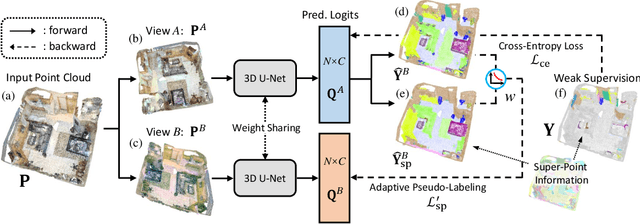
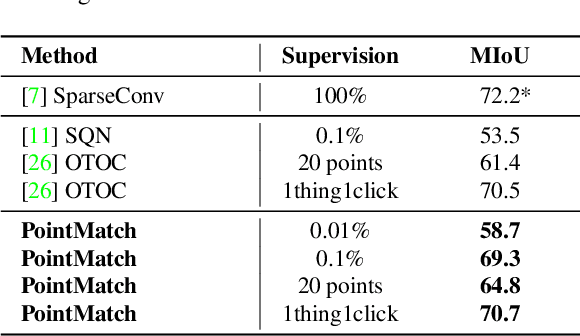
Semantic segmentation of point cloud usually relies on dense annotation that is exhausting and costly, so it attracts wide attention to investigate solutions for the weakly supervised scheme with only sparse points annotated. Existing works start from the given labels and propagate them to highly-related but unlabeled points, with the guidance of data, e.g. intra-point relation. However, it suffers from (i) the inefficient exploitation of data information, and (ii) the strong reliance on labels thus is easily suppressed when given much fewer annotations. Therefore, we propose a novel framework, PointMatch, that stands on both data and label, by applying consistency regularization to sufficiently probe information from data itself and leveraging weak labels as assistance at the same time. By doing so, meaningful information can be learned from both data and label for better representation learning, which also enables the model more robust to the extent of label sparsity. Simple yet effective, the proposed PointMatch achieves the state-of-the-art performance under various weakly-supervised schemes on both ScanNet-v2 and S3DIS datasets, especially on the settings with extremely sparse labels, e.g. surpassing SQN by 21.2% and 17.2% on the 0.01% and 0.1% setting of ScanNet-v2, respectively.
FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding
Mar 13, 2021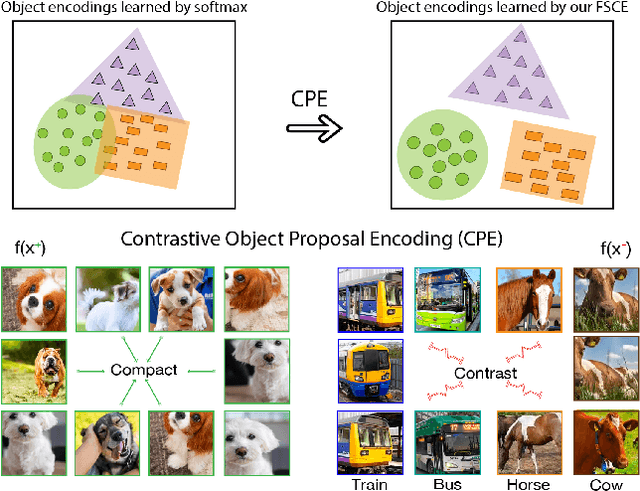


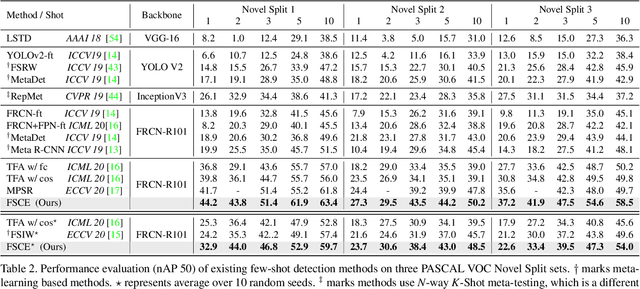
Emerging interests have been brought to recognize previously unseen objects given very few training examples, known as few-shot object detection (FSOD). Recent researches demonstrate that good feature embedding is the key to reach favorable few-shot learning performance. We observe object proposals with different Intersection-of-Union (IoU) scores are analogous to the intra-image augmentation used in contrastive approaches. And we exploit this analogy and incorporate supervised contrastive learning to achieve more robust objects representations in FSOD. We present Few-Shot object detection via Contrastive proposals Encoding (FSCE), a simple yet effective approach to learning contrastive-aware object proposal encodings that facilitate the classification of detected objects. We notice the degradation of average precision (AP) for rare objects mainly comes from misclassifying novel instances as confusable classes. And we ease the misclassification issues by promoting instance level intra-class compactness and inter-class variance via our contrastive proposal encoding loss (CPE loss). Our design outperforms current state-of-the-art works in any shot and all data splits, with up to +8.8% on standard benchmark PASCAL VOC and +2.7% on challenging COCO benchmark. Code is available at: https: //github.com/MegviiDetection/FSCE