 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTexSpot: 3D Texture Enhancement with Spatially-uniform Point Latent Representation
Feb 14, 2026High-quality 3D texture generation remains a fundamental challenge due to the view-inconsistency inherent in current mainstream multi-view diffusion pipelines. Existing representations either rely on UV maps, which suffer from distortion during unwrapping, or point-based methods, which tightly couple texture fidelity to geometric density that limits high-resolution texture generation. To address these limitations, we introduce TexSpot, a diffusion-based texture enhancement framework. At its core is Texlet, a novel 3D texture representation that merges the geometric expressiveness of point-based 3D textures with the compactness of UV-based representation. Each Texlet latent vector encodes a local texture patch via a 2D encoder and is further aggregated using a 3D encoder to incorporate global shape context. A cascaded 3D-to-2D decoder reconstructs high-quality texture patches, enabling the Texlet space learning. Leveraging this representation, we train a diffusion transformer conditioned on Texlets to refine and enhance textures produced by multi-view diffusion methods. Extensive experiments demonstrate that TexSpot significantly improves visual fidelity, geometric consistency, and robustness over existing state-of-the-art 3D texture generation and enhancement approaches. Project page: https://texlet-arch.github.io/TexSpot-page.
UniPart: Part-Level 3D Generation with Unified 3D Geom-Seg Latents
Dec 10, 2025Part-level 3D generation is essential for applications requiring decomposable and structured 3D synthesis. However, existing methods either rely on implicit part segmentation with limited granularity control or depend on strong external segmenters trained on large annotated datasets. In this work, we observe that part awareness emerges naturally during whole-object geometry learning and propose Geom-Seg VecSet, a unified geometry-segmentation latent representation that jointly encodes object geometry and part-level structure. Building on this representation, we introduce UniPart, a two-stage latent diffusion framework for image-guided part-level 3D generation. The first stage performs joint geometry generation and latent part segmentation, while the second stage conditions part-level diffusion on both whole-object and part-specific latents. A dual-space generation scheme further enhances geometric fidelity by predicting part latents in both global and canonical spaces. Extensive experiments demonstrate that UniPart achieves superior segmentation controllability and part-level geometric quality compared with existing approaches.
Hi3DGen: High-fidelity 3D Geometry Generation from Images via Normal Bridging
Mar 31, 2025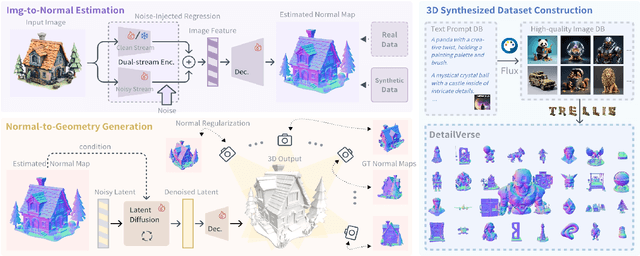
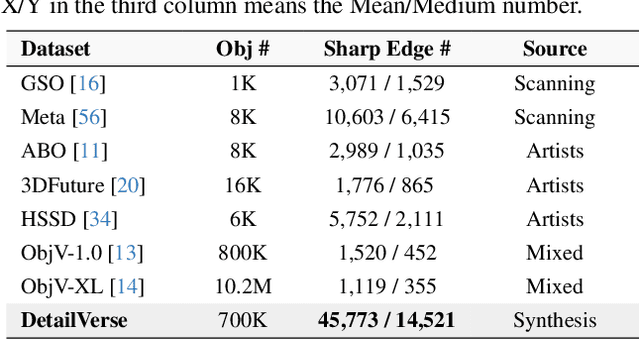
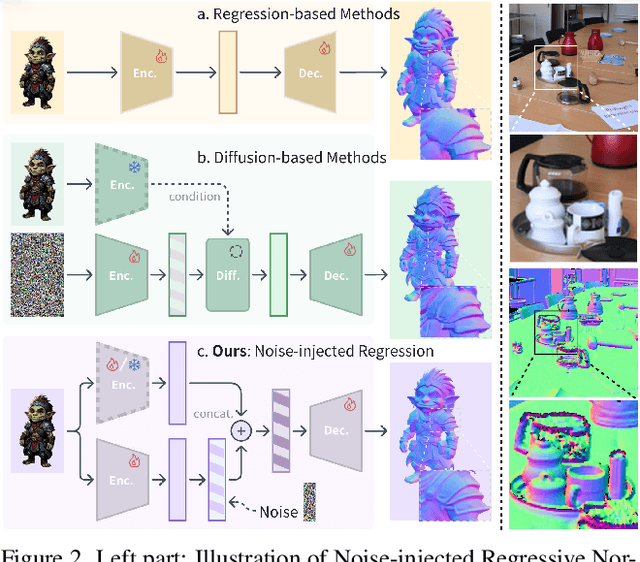
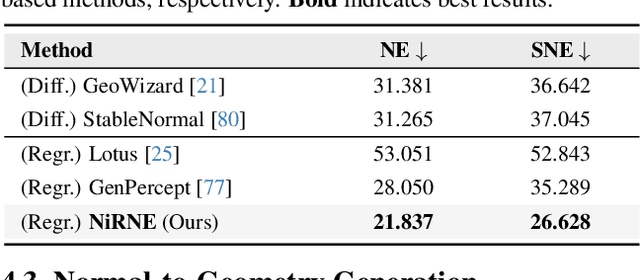
With the growing demand for high-fidelity 3D models from 2D images, existing methods still face significant challenges in accurately reproducing fine-grained geometric details due to limitations in domain gaps and inherent ambiguities in RGB images. To address these issues, we propose Hi3DGen, a novel framework for generating high-fidelity 3D geometry from images via normal bridging. Hi3DGen consists of three key components: (1) an image-to-normal estimator that decouples the low-high frequency image pattern with noise injection and dual-stream training to achieve generalizable, stable, and sharp estimation; (2) a normal-to-geometry learning approach that uses normal-regularized latent diffusion learning to enhance 3D geometry generation fidelity; and (3) a 3D data synthesis pipeline that constructs a high-quality dataset to support training. Extensive experiments demonstrate the effectiveness and superiority of our framework in generating rich geometric details, outperforming state-of-the-art methods in terms of fidelity. Our work provides a new direction for high-fidelity 3D geometry generation from images by leveraging normal maps as an intermediate representation.
MVImgNet2.0: A Larger-scale Dataset of Multi-view Images
Dec 02, 2024
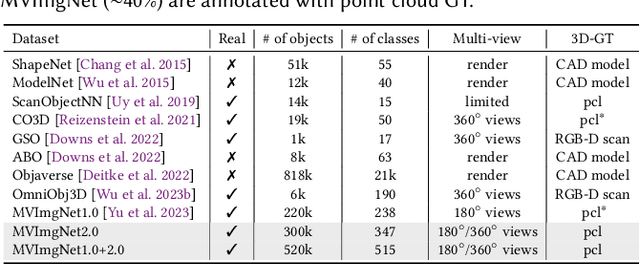

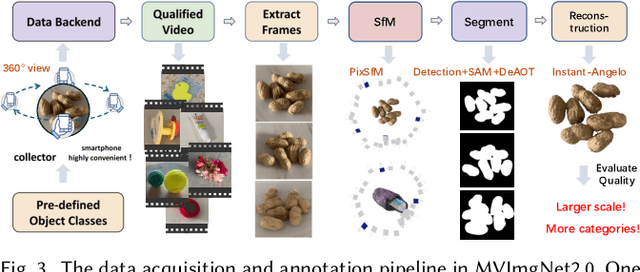
MVImgNet is a large-scale dataset that contains multi-view images of ~220k real-world objects in 238 classes. As a counterpart of ImageNet, it introduces 3D visual signals via multi-view shooting, making a soft bridge between 2D and 3D vision. This paper constructs the MVImgNet2.0 dataset that expands MVImgNet into a total of ~520k objects and 515 categories, which derives a 3D dataset with a larger scale that is more comparable to ones in the 2D domain. In addition to the expanded dataset scale and category range, MVImgNet2.0 is of a higher quality than MVImgNet owing to four new features: (i) most shoots capture 360-degree views of the objects, which can support the learning of object reconstruction with completeness; (ii) the segmentation manner is advanced to produce foreground object masks of higher accuracy; (iii) a more powerful structure-from-motion method is adopted to derive the camera pose for each frame of a lower estimation error; (iv) higher-quality dense point clouds are reconstructed via advanced methods for objects captured in 360-degree views, which can serve for downstream applications. Extensive experiments confirm the value of the proposed MVImgNet2.0 in boosting the performance of large 3D reconstruction models. MVImgNet2.0 will be public at luyues.github.io/mvimgnet2, including multi-view images of all 520k objects, the reconstructed high-quality point clouds, and data annotation codes, hoping to inspire the broader vision community.
* ACM Transactions on Graphics (TOG), SIGGRAPH Asia 2024
DreamDissector: Learning Disentangled Text-to-3D Generation from 2D Diffusion Priors
Jul 23, 2024
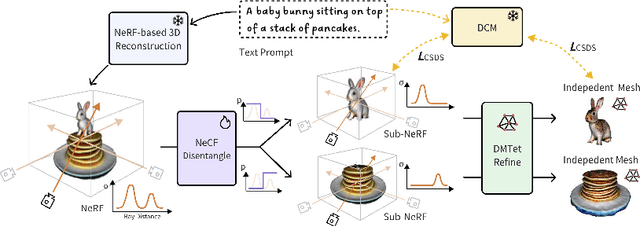
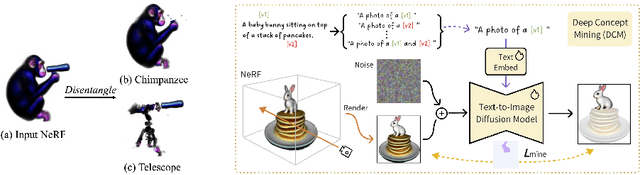

Text-to-3D generation has recently seen significant progress. To enhance its practicality in real-world applications, it is crucial to generate multiple independent objects with interactions, similar to layer-compositing in 2D image editing. However, existing text-to-3D methods struggle with this task, as they are designed to generate either non-independent objects or independent objects lacking spatially plausible interactions. Addressing this, we propose DreamDissector, a text-to-3D method capable of generating multiple independent objects with interactions. DreamDissector accepts a multi-object text-to-3D NeRF as input and produces independent textured meshes. To achieve this, we introduce the Neural Category Field (NeCF) for disentangling the input NeRF. Additionally, we present the Category Score Distillation Sampling (CSDS), facilitated by a Deep Concept Mining (DCM) module, to tackle the concept gap issue in diffusion models. By leveraging NeCF and CSDS, we can effectively derive sub-NeRFs from the original scene. Further refinement enhances geometry and texture. Our experimental results validate the effectiveness of DreamDissector, providing users with novel means to control 3D synthesis at the object level and potentially opening avenues for various creative applications in the future.
StableNormal: Reducing Diffusion Variance for Stable and Sharp Normal
Jun 24, 2024


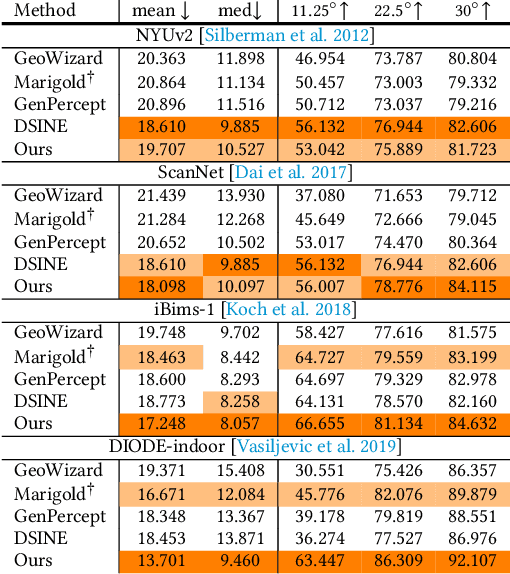
This work addresses the challenge of high-quality surface normal estimation from monocular colored inputs (i.e., images and videos), a field which has recently been revolutionized by repurposing diffusion priors. However, previous attempts still struggle with stochastic inference, conflicting with the deterministic nature of the Image2Normal task, and costly ensembling step, which slows down the estimation process. Our method, StableNormal, mitigates the stochasticity of the diffusion process by reducing inference variance, thus producing "Stable-and-Sharp" normal estimates without any additional ensembling process. StableNormal works robustly under challenging imaging conditions, such as extreme lighting, blurring, and low quality. It is also robust against transparent and reflective surfaces, as well as cluttered scenes with numerous objects. Specifically, StableNormal employs a coarse-to-fine strategy, which starts with a one-step normal estimator (YOSO) to derive an initial normal guess, that is relatively coarse but reliable, then followed by a semantic-guided refinement process (SG-DRN) that refines the normals to recover geometric details. The effectiveness of StableNormal is demonstrated through competitive performance in standard datasets such as DIODE-indoor, iBims, ScannetV2 and NYUv2, and also in various downstream tasks, such as surface reconstruction and normal enhancement. These results evidence that StableNormal retains both the "stability" and "sharpness" for accurate normal estimation. StableNormal represents a baby attempt to repurpose diffusion priors for deterministic estimation. To democratize this, code and models have been publicly available in hf.co/Stable-X
IPoD: Implicit Field Learning with Point Diffusion for Generalizable 3D Object Reconstruction from Single RGB-D Images
Mar 30, 2024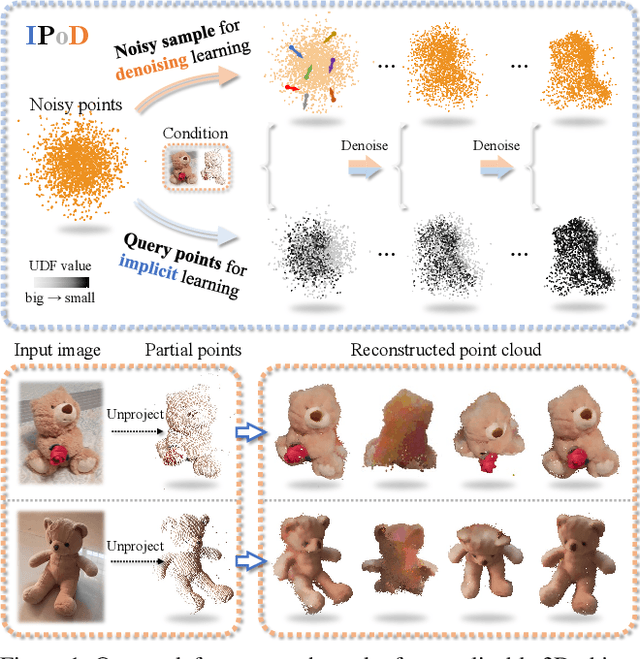
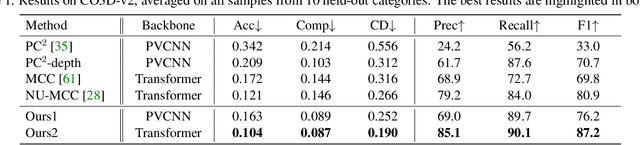
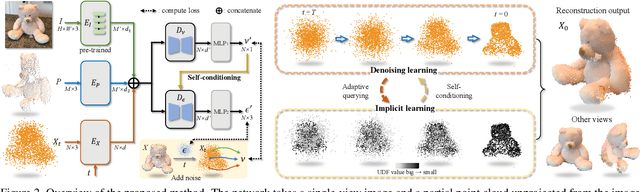
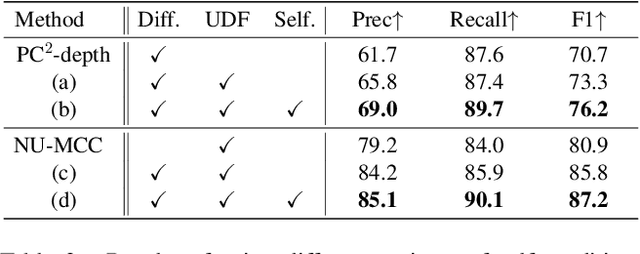
Generalizable 3D object reconstruction from single-view RGB-D images remains a challenging task, particularly with real-world data. Current state-of-the-art methods develop Transformer-based implicit field learning, necessitating an intensive learning paradigm that requires dense query-supervision uniformly sampled throughout the entire space. We propose a novel approach, IPoD, which harmonizes implicit field learning with point diffusion. This approach treats the query points for implicit field learning as a noisy point cloud for iterative denoising, allowing for their dynamic adaptation to the target object shape. Such adaptive query points harness diffusion learning's capability for coarse shape recovery and also enhances the implicit representation's ability to delineate finer details. Besides, an additional self-conditioning mechanism is designed to use implicit predictions as the guidance of diffusion learning, leading to a cooperative system. Experiments conducted on the CO3D-v2 dataset affirm the superiority of IPoD, achieving 7.8% improvement in F-score and 28.6% in Chamfer distance over existing methods. The generalizability of IPoD is also demonstrated on the MVImgNet dataset. Our project page is at https://yushuang-wu.github.io/IPoD.
RichDreamer: A Generalizable Normal-Depth Diffusion Model for Detail Richness in Text-to-3D
Nov 28, 2023


Lifting 2D diffusion for 3D generation is a challenging problem due to the lack of geometric prior and the complex entanglement of materials and lighting in natural images. Existing methods have shown promise by first creating the geometry through score-distillation sampling (SDS) applied to rendered surface normals, followed by appearance modeling. However, relying on a 2D RGB diffusion model to optimize surface normals is suboptimal due to the distribution discrepancy between natural images and normals maps, leading to instability in optimization. In this paper, recognizing that the normal and depth information effectively describe scene geometry and be automatically estimated from images, we propose to learn a generalizable Normal-Depth diffusion model for 3D generation. We achieve this by training on the large-scale LAION dataset together with the generalizable image-to-depth and normal prior models. In an attempt to alleviate the mixed illumination effects in the generated materials, we introduce an albedo diffusion model to impose data-driven constraints on the albedo component. Our experiments show that when integrated into existing text-to-3D pipelines, our models significantly enhance the detail richness, achieving state-of-the-art results. Our project page is https://lingtengqiu.github.io/RichDreamer/.
Efficient View Synthesis with Neural Radiance Distribution Field
Aug 22, 2023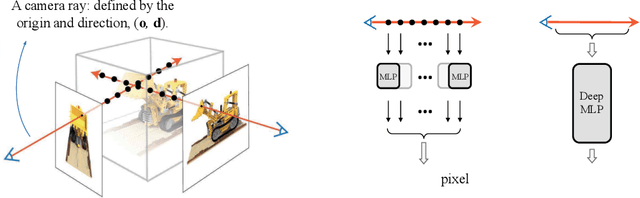

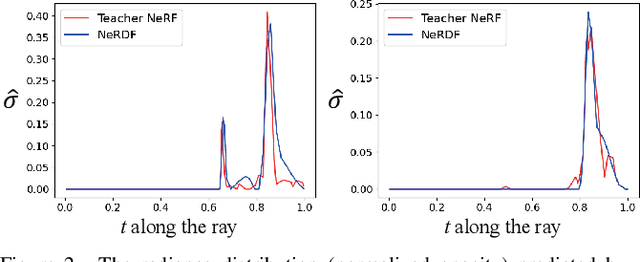
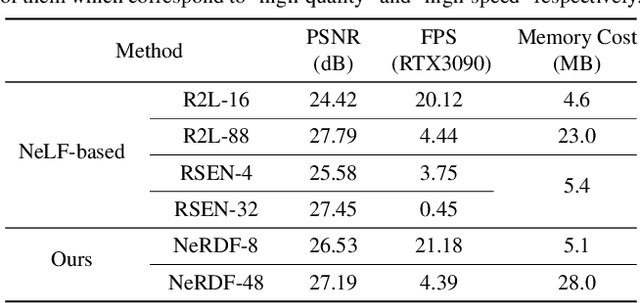
Recent work on Neural Radiance Fields (NeRF) has demonstrated significant advances in high-quality view synthesis. A major limitation of NeRF is its low rendering efficiency due to the need for multiple network forwardings to render a single pixel. Existing methods to improve NeRF either reduce the number of required samples or optimize the implementation to accelerate the network forwarding. Despite these efforts, the problem of multiple sampling persists due to the intrinsic representation of radiance fields. In contrast, Neural Light Fields (NeLF) reduce the computation cost of NeRF by querying only one single network forwarding per pixel. To achieve a close visual quality to NeRF, existing NeLF methods require significantly larger network capacities which limits their rendering efficiency in practice. In this work, we propose a new representation called Neural Radiance Distribution Field (NeRDF) that targets efficient view synthesis in real-time. Specifically, we use a small network similar to NeRF while preserving the rendering speed with a single network forwarding per pixel as in NeLF. The key is to model the radiance distribution along each ray with frequency basis and predict frequency weights using the network. Pixel values are then computed via volume rendering on radiance distributions. Experiments show that our proposed method offers a better trade-off among speed, quality, and network size than existing methods: we achieve a ~254x speed-up over NeRF with similar network size, with only a marginal performance decline. Our project page is at yushuang-wu.github.io/NeRDF.
Universal Semi-supervised Model Adaptation via Collaborative Consistency Training
Jul 07, 2023In this paper, we introduce a realistic and challenging domain adaptation problem called Universal Semi-supervised Model Adaptation (USMA), which i) requires only a pre-trained source model, ii) allows the source and target domain to have different label sets, i.e., they share a common label set and hold their own private label set, and iii) requires only a few labeled samples in each class of the target domain. To address USMA, we propose a collaborative consistency training framework that regularizes the prediction consistency between two models, i.e., a pre-trained source model and its variant pre-trained with target data only, and combines their complementary strengths to learn a more powerful model. The rationale of our framework stems from the observation that the source model performs better on common categories than the target-only model, while on target-private categories, the target-only model performs better. We also propose a two-perspective, i.e., sample-wise and class-wise, consistency regularization to improve the training. Experimental results demonstrate the effectiveness of our method on several benchmark datasets.