 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobile-VTON: High-Fidelity On-Device Virtual Try-On
Mar 03, 2026Virtual try-on (VTON) has recently achieved impressive visual fidelity, but most existing systems require uploading personal photos to cloud-based GPUs, raising privacy concerns and limiting on-device deployment. To address this, we present Mobile-VTON, a high-quality, privacy-preserving framework that enables fully offline virtual try-on on commodity mobile devices using only a single user image and a garment image. Mobile-VTON introduces a modular TeacherNet-GarmentNet-TryonNet (TGT) architecture that integrates knowledge distillation, garment-conditioned generation, and garment alignment into a unified pipeline optimized for on-device efficiency. Within this framework, we propose a Feature-Guided Adversarial (FGA) Distillation strategy that combines teacher supervision with adversarial learning to better match real-world image distributions. GarmentNet is trained with a trajectory-consistency loss to preserve garment semantics across diffusion steps, while TryonNet uses latent concatenation and lightweight cross-modal conditioning to enable robust garment-to-person alignment without large-scale pretraining. By combining these components, Mobile-VTON achieves high-fidelity generation with low computational overhead. Experiments on VITON-HD and DressCode at 1024 x 768 show that it matches or outperforms strong server-based baselines while running entirely offline. These results demonstrate that high-quality VTON is not only feasible but also practical on-device, offering a secure solution for real-world applications.
* The project page is available at: https://zhenchenwan.github.io/Mobile-VTON/
Condition Matters in Full-head 3D GANs
Feb 06, 2026Conditioning is crucial for stable training of full-head 3D GANs. Without any conditioning signal, the model suffers from severe mode collapse, making it impractical to training. However, a series of previous full-head 3D GANs conventionally choose the view angle as the conditioning input, which leads to a bias in the learned 3D full-head space along the conditional view direction. This is evident in the significant differences in generation quality and diversity between the conditional view and non-conditional views of the generated 3D heads, resulting in global incoherence across different head regions. In this work, we propose to use view-invariant semantic feature as the conditioning input, thereby decoupling the generative capability of 3D heads from the viewing direction. To construct a view-invariant semantic condition for each training image, we create a novel synthesized head image dataset. We leverage FLUX.1 Kontext to extend existing high-quality frontal face datasets to a wide range of view angles. The image clip feature extracted from the frontal view is then used as a shared semantic condition across all views in the extended images, ensuring semantic alignment while eliminating directional bias. This also allows supervision from different views of the same subject to be consolidated under a shared semantic condition, which accelerates training and enhances the global coherence of the generated 3D heads. Moreover, as GANs often experience slower improvements in diversity once the generator learns a few modes that successfully fool the discriminator, our semantic conditioning encourages the generator to follow the true semantic distribution, thereby promoting continuous learning and diverse generation. Extensive experiments on full-head synthesis and single-view GAN inversion demonstrate that our method achieves significantly higher fidelity, diversity, and generalizability.
CT4D: Consistent Text-to-4D Generation with Animatable Meshes
Aug 15, 2024

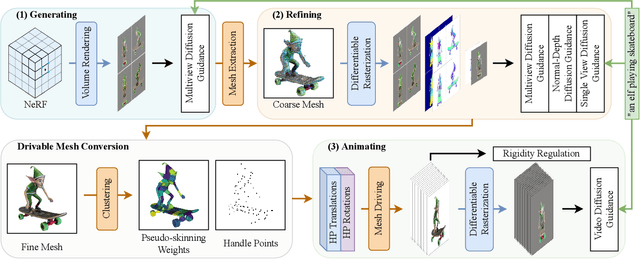

Text-to-4D generation has recently been demonstrated viable by integrating a 2D image diffusion model with a video diffusion model. However, existing models tend to produce results with inconsistent motions and geometric structures over time. To this end, we present a novel framework, coined CT4D, which directly operates on animatable meshes for generating consistent 4D content from arbitrary user-supplied prompts. The primary challenges of our mesh-based framework involve stably generating a mesh with details that align with the text prompt while directly driving it and maintaining surface continuity. Our CT4D framework incorporates a unique Generate-Refine-Animate (GRA) algorithm to enhance the creation of text-aligned meshes. To improve surface continuity, we divide a mesh into several smaller regions and implement a uniform driving function within each area. Additionally, we constrain the animating stage with a rigidity regulation to ensure cross-region continuity. Our experimental results, both qualitative and quantitative, demonstrate that our CT4D framework surpasses existing text-to-4D techniques in maintaining interframe consistency and preserving global geometry. Furthermore, we showcase that this enhanced representation inherently possesses the capability for combinational 4D generation and texture editing.
SphereHead: Stable 3D Full-head Synthesis with Spherical Tri-plane Representation
Apr 08, 2024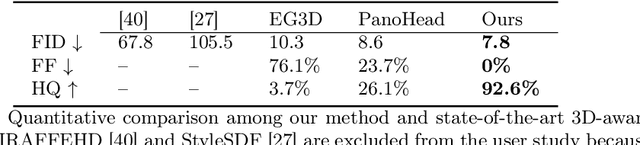

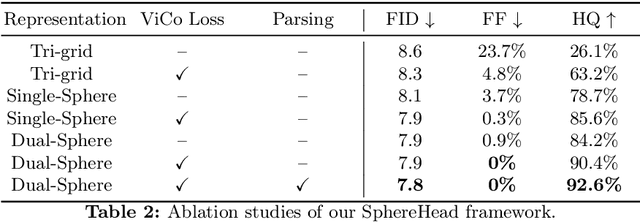
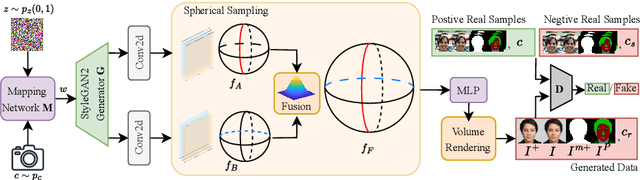
While recent advances in 3D-aware Generative Adversarial Networks (GANs) have aided the development of near-frontal view human face synthesis, the challenge of comprehensively synthesizing a full 3D head viewable from all angles still persists. Although PanoHead proves the possibilities of using a large-scale dataset with images of both frontal and back views for full-head synthesis, it often causes artifacts for back views. Based on our in-depth analysis, we found the reasons are mainly twofold. First, from network architecture perspective, we found each plane in the utilized tri-plane/tri-grid representation space tends to confuse the features from both sides, causing "mirroring" artifacts (e.g., the glasses appear in the back). Second, from data supervision aspect, we found that existing discriminator training in 3D GANs mainly focuses on the quality of the rendered image itself, and does not care much about its plausibility with the perspective from which it was rendered. This makes it possible to generate "face" in non-frontal views, due to its easiness to fool the discriminator. In response, we propose SphereHead, a novel tri-plane representation in the spherical coordinate system that fits the human head's geometric characteristics and efficiently mitigates many of the generated artifacts. We further introduce a view-image consistency loss for the discriminator to emphasize the correspondence of the camera parameters and the images. The combination of these efforts results in visually superior outcomes with significantly fewer artifacts. Our code and dataset are publicly available at https://lhyfst.github.io/spherehead.
DenseMP: Unsupervised Dense Pre-training for Few-shot Medical Image Segmentation
Jul 13, 2023Few-shot medical image semantic segmentation is of paramount importance in the domain of medical image analysis. However, existing methodologies grapple with the challenge of data scarcity during the training phase, leading to over-fitting. To mitigate this issue, we introduce a novel Unsupervised Dense Few-shot Medical Image Segmentation Model Training Pipeline (DenseMP) that capitalizes on unsupervised dense pre-training. DenseMP is composed of two distinct stages: (1) segmentation-aware dense contrastive pre-training, and (2) few-shot-aware superpixel guided dense pre-training. These stages collaboratively yield a pre-trained initial model specifically designed for few-shot medical image segmentation, which can subsequently be fine-tuned on the target dataset. Our proposed pipeline significantly enhances the performance of the widely recognized few-shot segmentation model, PA-Net, achieving state-of-the-art results on the Abd-CT and Abd-MRI datasets. Code will be released after acceptance.
SCoDA: Domain Adaptive Shape Completion for Real Scans
Apr 24, 20233D shape completion from point clouds is a challenging task, especially from scans of real-world objects. Considering the paucity of 3D shape ground truths for real scans, existing works mainly focus on benchmarking this task on synthetic data, e.g. 3D computer-aided design models. However, the domain gap between synthetic and real data limits the generalizability of these methods. Thus, we propose a new task, SCoDA, for the domain adaptation of real scan shape completion from synthetic data. A new dataset, ScanSalon, is contributed with a bunch of elaborate 3D models created by skillful artists according to scans. To address this new task, we propose a novel cross-domain feature fusion method for knowledge transfer and a novel volume-consistent self-training framework for robust learning from real data. Extensive experiments prove our method is effective to bring an improvement of 6%~7% mIoU.
Structure-Preserving Super Resolution with Gradient Guidance
Mar 29, 2020
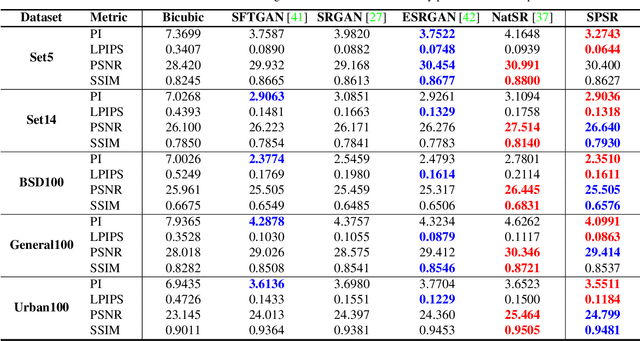
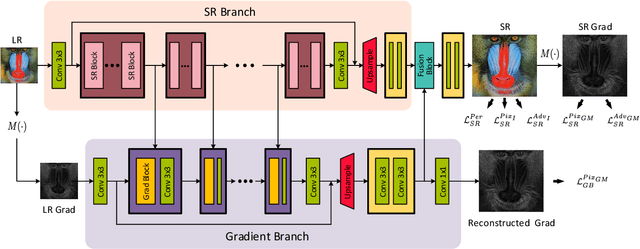

Structures matter in single image super resolution (SISR). Recent studies benefiting from generative adversarial network (GAN) have promoted the development of SISR by recovering photo-realistic images. However, there are always undesired structural distortions in the recovered images. In this paper, we propose a structure-preserving super resolution method to alleviate the above issue while maintaining the merits of GAN-based methods to generate perceptual-pleasant details. Specifically, we exploit gradient maps of images to guide the recovery in two aspects. On the one hand, we restore high-resolution gradient maps by a gradient branch to provide additional structure priors for the SR process. On the other hand, we propose a gradient loss which imposes a second-order restriction on the super-resolved images. Along with the previous image-space loss functions, the gradient-space objectives help generative networks concentrate more on geometric structures. Moreover, our method is model-agnostic, which can be potentially used for off-the-shelf SR networks. Experimental results show that we achieve the best PI and LPIPS performance and meanwhile comparable PSNR and SSIM compared with state-of-the-art perceptual-driven SR methods. Visual results demonstrate our superiority in restoring structures while generating natural SR images.