 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCT4D: Consistent Text-to-4D Generation with Animatable Meshes
Paper and Code


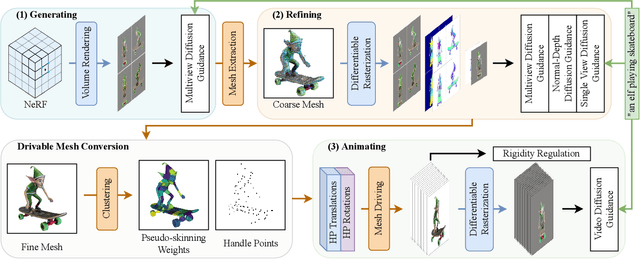

Text-to-4D generation has recently been demonstrated viable by integrating a 2D image diffusion model with a video diffusion model. However, existing models tend to produce results with inconsistent motions and geometric structures over time. To this end, we present a novel framework, coined CT4D, which directly operates on animatable meshes for generating consistent 4D content from arbitrary user-supplied prompts. The primary challenges of our mesh-based framework involve stably generating a mesh with details that align with the text prompt while directly driving it and maintaining surface continuity. Our CT4D framework incorporates a unique Generate-Refine-Animate (GRA) algorithm to enhance the creation of text-aligned meshes. To improve surface continuity, we divide a mesh into several smaller regions and implement a uniform driving function within each area. Additionally, we constrain the animating stage with a rigidity regulation to ensure cross-region continuity. Our experimental results, both qualitative and quantitative, demonstrate that our CT4D framework surpasses existing text-to-4D techniques in maintaining interframe consistency and preserving global geometry. Furthermore, we showcase that this enhanced representation inherently possesses the capability for combinational 4D generation and texture editing.