 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuteur: Language-Driven Cinematographic Framing for Human-Centric Video Generation
Jun 01, 2026Generative video models have achieved remarkable visual fidelity and temporal coherence, yet intentional camera control remains elusive. Existing frameworks treat camera motion as a byproduct of pixel synthesis, producing trajectories that are stochastic, spatially inconsistent, and indifferent to the human subject driving the scene. In this work, we present Auteur, a method for language-driven, human-centric camera framing in generative video. Our core insight is that professional filmmakers conceive shots not as world-space trajectories but as framings defined relative to the actor, encoding shot size, angle, and composition as functions of human pose and motion. We formalize this intuition as a human-centric camera parameterization and introduce a Domain-Specific Language (DSL) that is convertible to standard 6-DoF camera parameters. A fine-tuned multimodal large language model then acts as a virtual director, mapping natural language descriptions and coarse human motion to sparse DSL keyframes that are deterministically interpolated into continuous camera trajectories, which are then provided as input to video generators. We train and evaluate Auteur on a new dataset of 34K aligned text, human motion, and DSL-annotated camera trajectories drawn from procedural synthesis and real-world movie footage from the CondensedMovies dataset. Auteur enables cinematographic framing of human-centered scenes, a capability largely absent in prior generative models. To assess this behavior, we propose new framing-focused metrics, and our experiments show that Auteur consistently outperforms existing methods
LightCtrl: Training-free Controllable Video Relighting
Mar 28, 2026Recent diffusion models have achieved remarkable success in image relighting, and this success has quickly been extended to video relighting. However, existing methods offer limited explicit control over illumination in the relighted output. We present LightCtrl, the first controllable video relighting method that enables explicit control of video illumination through a user-supplied light trajectory in a training-free manner. Our approach combines pre-trained diffusion models: an image relighting model processes each frame individually, followed by a video diffusion prior to enhance temporal consistency. To achieve explicit control over dynamically varying lighting, we introduce two key components. First, a Light Map Injection module samples light trajectory-specific noise and injects it into the latent representation of the source video, improving illumination coherence with the conditional light trajectory. Second, a Geometry-Aware Relighting module dynamically combines RGB and normal map latents in the frequency domain to suppress the influence of the original lighting, further enhancing adherence to the input light trajectory. Experiments show that LightCtrl produces high-quality videos with diverse illumination changes that closely follow the specified light trajectory, demonstrating improved controllability over baseline methods. Code is available at: https://github.com/GVCLab/LightCtrl.
LoST: Level of Semantics Tokenization for 3D Shapes
Mar 18, 2026Tokenization is a fundamental technique in the generative modeling of various modalities. In particular, it plays a critical role in autoregressive (AR) models, which have recently emerged as a compelling option for 3D generation. However, optimal tokenization of 3D shapes remains an open question. State-of-the-art (SOTA) methods primarily rely on geometric level-of-detail (LoD) hierarchies, originally designed for rendering and compression. These spatial hierarchies are often token-inefficient and lack semantic coherence for AR modeling. We propose Level-of-Semantics Tokenization (LoST), which orders tokens by semantic salience, such that early prefixes decode into complete, plausible shapes that possess principal semantics, while subsequent tokens refine instance-specific geometric and semantic details. To train LoST, we introduce Relational Inter-Distance Alignment (RIDA), a novel 3D semantic alignment loss that aligns the relational structure of the 3D shape latent space with that of the semantic DINO feature space. Experiments show that LoST achieves SOTA reconstruction, surpassing previous LoD-based 3D shape tokenizers by large margins on both geometric and semantic reconstruction metrics. Moreover, LoST achieves efficient, high-quality AR 3D generation and enables downstream tasks like semantic retrieval, while using only 0.1%-10% of the tokens needed by prior AR models.
Memory-V2V: Augmenting Video-to-Video Diffusion Models with Memory
Jan 22, 2026Recent foundational video-to-video diffusion models have achieved impressive results in editing user provided videos by modifying appearance, motion, or camera movement. However, real-world video editing is often an iterative process, where users refine results across multiple rounds of interaction. In this multi-turn setting, current video editors struggle to maintain cross-consistency across sequential edits. In this work, we tackle, for the first time, the problem of cross-consistency in multi-turn video editing and introduce Memory-V2V, a simple, yet effective framework that augments existing video-to-video models with explicit memory. Given an external cache of previously edited videos, Memory-V2V employs accurate retrieval and dynamic tokenization strategies to condition the current editing step on prior results. To further mitigate redundancy and computational overhead, we propose a learnable token compressor within the DiT backbone that compresses redundant conditioning tokens while preserving essential visual cues, achieving an overall speedup of 30%. We validate Memory-V2V on challenging tasks including video novel view synthesis and text-conditioned long video editing. Extensive experiments show that Memory-V2V produces videos that are significantly more cross-consistent with minimal computational overhead, while maintaining or even improving task-specific performance over state-of-the-art baselines. Project page: https://dohunlee1.github.io/MemoryV2V
SpaceTimePilot: Generative Rendering of Dynamic Scenes Across Space and Time
Dec 31, 2025We present SpaceTimePilot, a video diffusion model that disentangles space and time for controllable generative rendering. Given a monocular video, SpaceTimePilot can independently alter the camera viewpoint and the motion sequence within the generative process, re-rendering the scene for continuous and arbitrary exploration across space and time. To achieve this, we introduce an effective animation time-embedding mechanism in the diffusion process, allowing explicit control of the output video's motion sequence with respect to that of the source video. As no datasets provide paired videos of the same dynamic scene with continuous temporal variations, we propose a simple yet effective temporal-warping training scheme that repurposes existing multi-view datasets to mimic temporal differences. This strategy effectively supervises the model to learn temporal control and achieve robust space-time disentanglement. To further enhance the precision of dual control, we introduce two additional components: an improved camera-conditioning mechanism that allows altering the camera from the first frame, and CamxTime, the first synthetic space-and-time full-coverage rendering dataset that provides fully free space-time video trajectories within a scene. Joint training on the temporal-warping scheme and the CamxTime dataset yields more precise temporal control. We evaluate SpaceTimePilot on both real-world and synthetic data, demonstrating clear space-time disentanglement and strong results compared to prior work. Project page: https://zheninghuang.github.io/Space-Time-Pilot/ Code: https://github.com/ZheningHuang/spacetimepilot
EasyOmnimatte: Taming Pretrained Inpainting Diffusion Models for End-to-End Video Layered Decomposition
Dec 26, 2025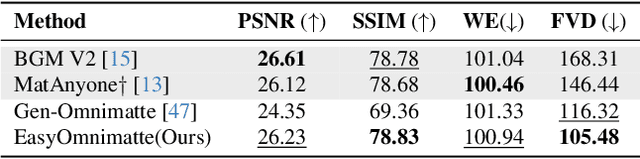
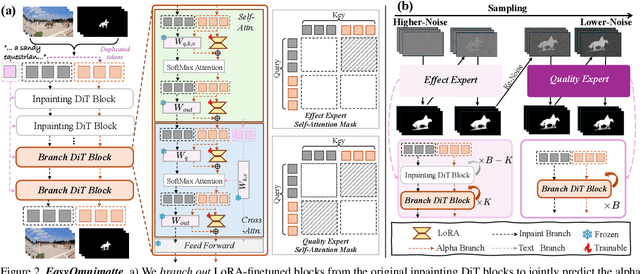
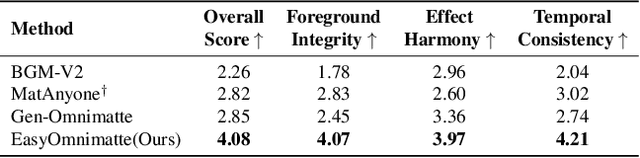
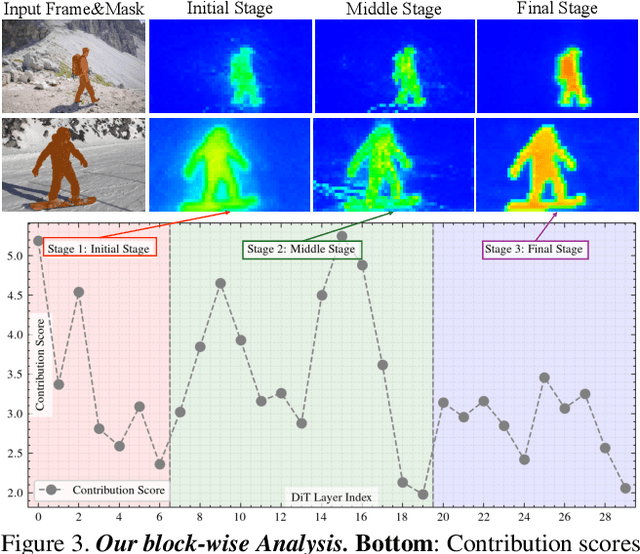
Existing video omnimatte methods typically rely on slow, multi-stage, or inference-time optimization pipelines that fail to fully exploit powerful generative priors, producing suboptimal decompositions. Our key insight is that, if a video inpainting model can be finetuned to remove the foreground-associated effects, then it must be inherently capable of perceiving these effects, and hence can also be finetuned for the complementary task: foreground layer decomposition with associated effects. However, although naïvely finetuning the inpainting model with LoRA applied to all blocks can produce high-quality alpha mattes, it fails to capture associated effects. Our systematic analysis reveals this arises because effect-related cues are primarily encoded in specific DiT blocks and become suppressed when LoRA is applied across all blocks. To address this, we introduce EasyOmnimatte, the first unified, end-to-end video omnimatte method. Concretely, we finetune a pretrained video inpainting diffusion model to learn dual complementary experts while keeping its original weights intact: an Effect Expert, where LoRA is applied only to effect-sensitive DiT blocks to capture the coarse structure of the foreground and associated effects, and a fully LoRA-finetuned Quality Expert learns to refine the alpha matte. During sampling, Effect Expert is used for denoising at early, high-noise steps, while Quality Expert takes over at later, low-noise steps. This design eliminates the need for two full diffusion passes, significantly reducing computational cost without compromising output quality. Ablation studies validate the effectiveness of this Dual-Expert strategy. Experiments demonstrate that EasyOmnimatte sets a new state-of-the-art for video omnimatte and enables various downstream tasks, significantly outperforming baselines in both quality and efficiency.
V-RGBX: Video Editing with Accurate Controls over Intrinsic Properties
Dec 12, 2025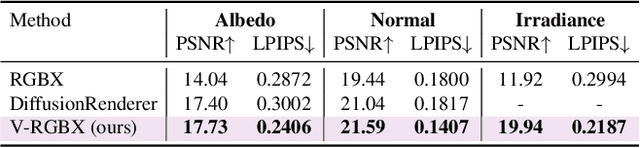
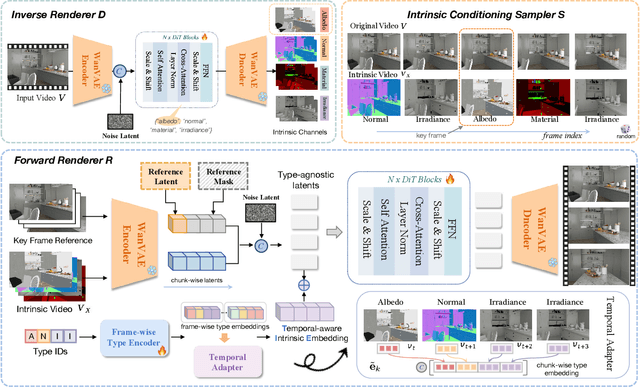
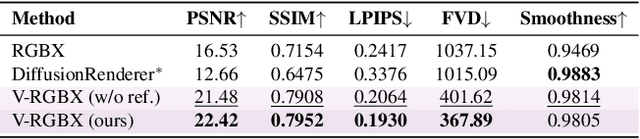

Large-scale video generation models have shown remarkable potential in modeling photorealistic appearance and lighting interactions in real-world scenes. However, a closed-loop framework that jointly understands intrinsic scene properties (e.g., albedo, normal, material, and irradiance), leverages them for video synthesis, and supports editable intrinsic representations remains unexplored. We present V-RGBX, the first end-to-end framework for intrinsic-aware video editing. V-RGBX unifies three key capabilities: (1) video inverse rendering into intrinsic channels, (2) photorealistic video synthesis from these intrinsic representations, and (3) keyframe-based video editing conditioned on intrinsic channels. At the core of V-RGBX is an interleaved conditioning mechanism that enables intuitive, physically grounded video editing through user-selected keyframes, supporting flexible manipulation of any intrinsic modality. Extensive qualitative and quantitative results show that V-RGBX produces temporally consistent, photorealistic videos while propagating keyframe edits across sequences in a physically plausible manner. We demonstrate its effectiveness in diverse applications, including object appearance editing and scene-level relighting, surpassing the performance of prior methods.
Democratizing High-Fidelity Co-Speech Gesture Video Generation
Jul 09, 2025Co-speech gesture video generation aims to synthesize realistic, audio-aligned videos of speakers, complete with synchronized facial expressions and body gestures. This task presents challenges due to the significant one-to-many mapping between audio and visual content, further complicated by the scarcity of large-scale public datasets and high computational demands. We propose a lightweight framework that utilizes 2D full-body skeletons as an efficient auxiliary condition to bridge audio signals with visual outputs. Our approach introduces a diffusion model conditioned on fine-grained audio segments and a skeleton extracted from the speaker's reference image, predicting skeletal motions through skeleton-audio feature fusion to ensure strict audio coordination and body shape consistency. The generated skeletons are then fed into an off-the-shelf human video generation model with the speaker's reference image to synthesize high-fidelity videos. To democratize research, we present CSG-405-the first public dataset with 405 hours of high-resolution videos across 71 speech types, annotated with 2D skeletons and diverse speaker demographics. Experiments show that our method exceeds state-of-the-art approaches in visual quality and synchronization while generalizing across speakers and contexts.
CT4D: Consistent Text-to-4D Generation with Animatable Meshes
Aug 15, 2024

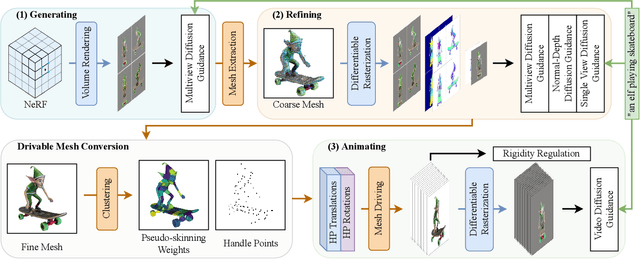

Text-to-4D generation has recently been demonstrated viable by integrating a 2D image diffusion model with a video diffusion model. However, existing models tend to produce results with inconsistent motions and geometric structures over time. To this end, we present a novel framework, coined CT4D, which directly operates on animatable meshes for generating consistent 4D content from arbitrary user-supplied prompts. The primary challenges of our mesh-based framework involve stably generating a mesh with details that align with the text prompt while directly driving it and maintaining surface continuity. Our CT4D framework incorporates a unique Generate-Refine-Animate (GRA) algorithm to enhance the creation of text-aligned meshes. To improve surface continuity, we divide a mesh into several smaller regions and implement a uniform driving function within each area. Additionally, we constrain the animating stage with a rigidity regulation to ensure cross-region continuity. Our experimental results, both qualitative and quantitative, demonstrate that our CT4D framework surpasses existing text-to-4D techniques in maintaining interframe consistency and preserving global geometry. Furthermore, we showcase that this enhanced representation inherently possesses the capability for combinational 4D generation and texture editing.
CraftsMan: High-fidelity Mesh Generation with 3D Native Generation and Interactive Geometry Refiner
May 23, 2024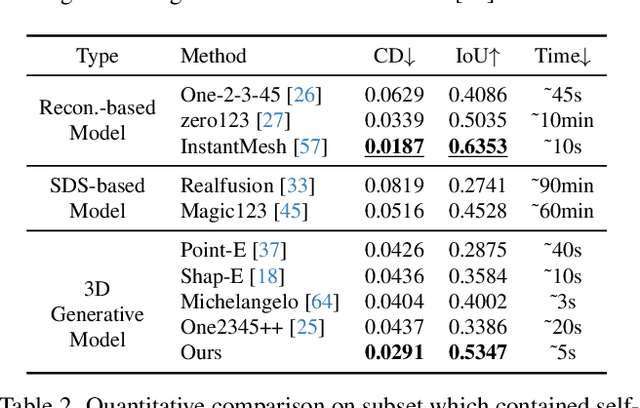



We present a novel generative 3D modeling system, coined CraftsMan, which can generate high-fidelity 3D geometries with highly varied shapes, regular mesh topologies, and detailed surfaces, and, notably, allows for refining the geometry in an interactive manner. Despite the significant advancements in 3D generation, existing methods still struggle with lengthy optimization processes, irregular mesh topologies, noisy surfaces, and difficulties in accommodating user edits, consequently impeding their widespread adoption and implementation in 3D modeling software. Our work is inspired by the craftsman, who usually roughs out the holistic figure of the work first and elaborates the surface details subsequently. Specifically, we employ a 3D native diffusion model, which operates on latent space learned from latent set-based 3D representations, to generate coarse geometries with regular mesh topology in seconds. In particular, this process takes as input a text prompt or a reference image and leverages a powerful multi-view (MV) diffusion model to generate multiple views of the coarse geometry, which are fed into our MV-conditioned 3D diffusion model for generating the 3D geometry, significantly improving robustness and generalizability. Following that, a normal-based geometry refiner is used to significantly enhance the surface details. This refinement can be performed automatically, or interactively with user-supplied edits. Extensive experiments demonstrate that our method achieves high efficacy in producing superior-quality 3D assets compared to existing methods. HomePage: https://craftsman3d.github.io/, Code: https://github.com/wyysf-98/CraftsMan