 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDT-ICU: Towards Explainable Digital Twins for ICU Patient Monitoring via Multi-Modal and Multi-Task Iterative Inference
Jan 12, 2026We introduce DT-ICU, a multimodal digital twin framework for continuous risk estimation in intensive care. DT-ICU integrates variable-length clinical time series with static patient information in a unified multitask architecture, enabling predictions to be updated as new observations accumulate over the ICU stay. We evaluate DT-ICU on the large, publicly available MIMIC-IV dataset, where it consistently outperforms established baseline models under different evaluation settings. Our test-length analysis shows that meaningful discrimination is achieved shortly after admission, while longer observation windows further improve the ranking of high-risk patients in highly imbalanced cohorts. To examine how the model leverages heterogeneous data sources, we perform systematic modality ablations, revealing that the model learnt a reasonable structured reliance on interventions, physiological response observations, and contextual information. These analyses provide interpretable insights into how multimodal signals are combined and how trade-offs between sensitivity and precision emerge. Together, these results demonstrate that DT-ICU delivers accurate, temporally robust, and interpretable predictions, supporting its potential as a practical digital twin framework for continuous patient monitoring in critical care. The source code and trained model weights for DT-ICU are publicly available at https://github.com/GUO-W/DT-ICU-release.
From COCO to COCO-FP: A Deep Dive into Background False Positives for COCO Detectors
Sep 12, 2024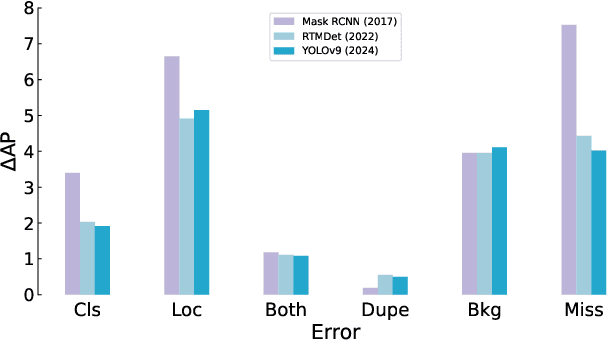
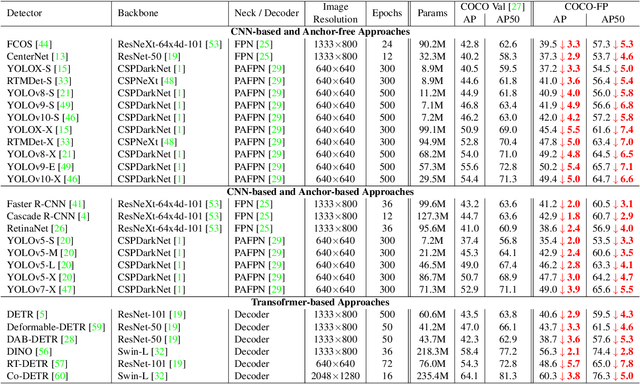
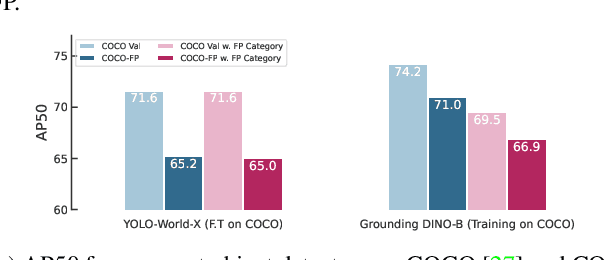
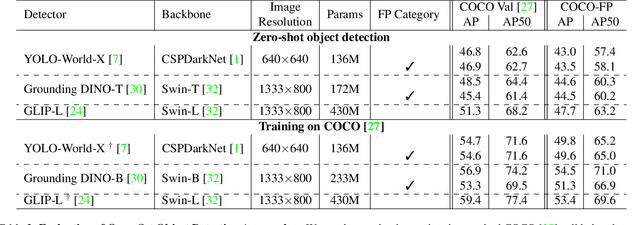
Reducing false positives is essential for enhancing object detector performance, as reflected in the mean Average Precision (mAP) metric. Although object detectors have achieved notable improvements and high mAP scores on the COCO dataset, analysis reveals limited progress in addressing false positives caused by non-target visual clutter-background objects not included in the annotated categories. This issue is particularly critical in real-world applications, such as fire and smoke detection, where minimizing false alarms is crucial. In this study, we introduce COCO-FP, a new evaluation dataset derived from the ImageNet-1K dataset, designed to address this issue. By extending the original COCO validation dataset, COCO-FP specifically assesses object detectors' performance in mitigating background false positives. Our evaluation of both standard and advanced object detectors shows a significant number of false positives in both closed-set and open-set scenarios. For example, the AP50 metric for YOLOv9-E decreases from 72.8 to 65.7 when shifting from COCO to COCO-FP. The dataset is available at https://github.com/COCO-FP/COCO-FP.
LivelySpeaker: Towards Semantic-Aware Co-Speech Gesture Generation
Sep 17, 2023



Gestures are non-verbal but important behaviors accompanying people's speech. While previous methods are able to generate speech rhythm-synchronized gestures, the semantic context of the speech is generally lacking in the gesticulations. Although semantic gestures do not occur very regularly in human speech, they are indeed the key for the audience to understand the speech context in a more immersive environment. Hence, we introduce LivelySpeaker, a framework that realizes semantics-aware co-speech gesture generation and offers several control handles. In particular, our method decouples the task into two stages: script-based gesture generation and audio-guided rhythm refinement. Specifically, the script-based gesture generation leverages the pre-trained CLIP text embeddings as the guidance for generating gestures that are highly semantically aligned with the script. Then, we devise a simple but effective diffusion-based gesture generation backbone simply using pure MLPs, that is conditioned on only audio signals and learns to gesticulate with realistic motions. We utilize such powerful prior to rhyme the script-guided gestures with the audio signals, notably in a zero-shot setting. Our novel two-stage generation framework also enables several applications, such as changing the gesticulation style, editing the co-speech gestures via textual prompting, and controlling the semantic awareness and rhythm alignment with guided diffusion. Extensive experiments demonstrate the advantages of the proposed framework over competing methods. In addition, our core diffusion-based generative model also achieves state-of-the-art performance on two benchmarks. The code and model will be released to facilitate future research.
Back to MLP: A Simple Baseline for Human Motion Prediction
Jul 04, 2022



This paper tackles the problem of human motion prediction, consisting in forecasting future body poses from historically observed sequences. Despite of their performance, current state-of-the-art approaches rely on deep learning architectures of arbitrary complexity, such as Recurrent Neural Networks~(RNN), Transformers or Graph Convolutional Networks~(GCN), typically requiring multiple training stages and more than 3 million of parameters. In this paper we show that the performance of these approaches can be surpassed by a light-weight and purely MLP architecture with only 0.14M parameters when appropriately combined with several standard practices such as representing the body pose with Discrete Cosine Transform (DCT), predicting residual displacement of joints and optimizing velocity as an auxiliary loss. An exhaustive evaluation on Human3.6M, AMASS and 3DPW datasets shows that our method, which we dub siMLPe, consistently outperforms all other approaches. We hope that our simple method could serve a strong baseline to the community and allow re-thinking the problem of human motion prediction and whether current benchmarks do really need intricate architectural designs. Our code is available at \url{https://github.com/dulucas/siMLPe}.
HiT-DVAE: Human Motion Generation via Hierarchical Transformer Dynamical VAE
Apr 04, 2022
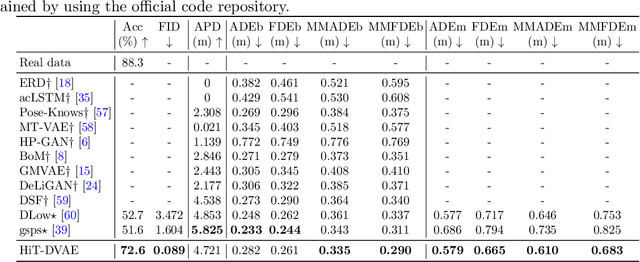
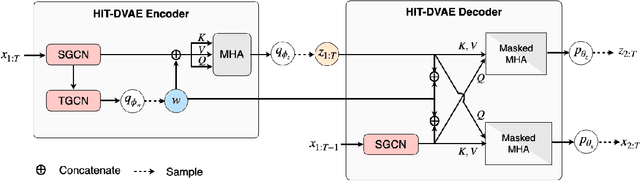
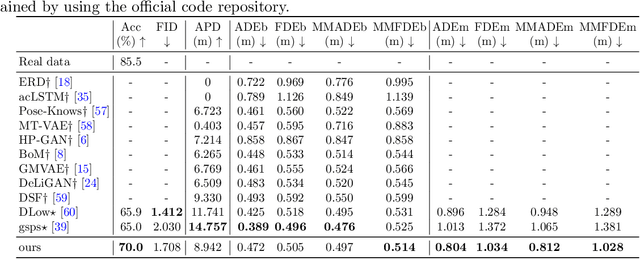
Studies on the automatic processing of 3D human pose data have flourished in the recent past. In this paper, we are interested in the generation of plausible and diverse future human poses following an observed 3D pose sequence. Current methods address this problem by injecting random variables from a single latent space into a deterministic motion prediction framework, which precludes the inherent multi-modality in human motion generation. In addition, previous works rarely explore the use of attention to select which frames are to be used to inform the generation process up to our knowledge. To overcome these limitations, we propose Hierarchical Transformer Dynamical Variational Autoencoder, HiT-DVAE, which implements auto-regressive generation with transformer-like attention mechanisms. HiT-DVAE simultaneously learns the evolution of data and latent space distribution with time correlated probabilistic dependencies, thus enabling the generative model to learn a more complex and time-varying latent space as well as diverse and realistic human motions. Furthermore, the auto-regressive generation brings more flexibility on observation and prediction, i.e. one can have any length of observation and predict arbitrary large sequences of poses with a single pre-trained model. We evaluate the proposed method on HumanEva-I and Human3.6M with various evaluation methods, and outperform the state-of-the-art methods on most of the metrics.
UVO Challenge on Video-based Open-World Segmentation 2021: 1st Place Solution
Nov 01, 2021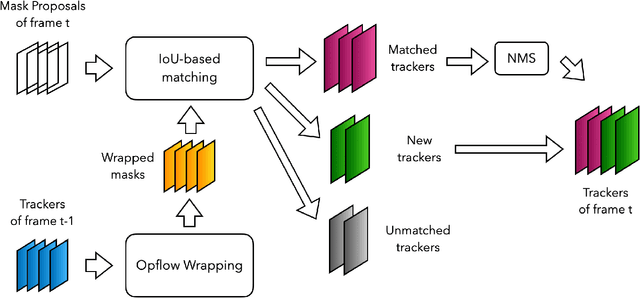


In this report, we introduce our (pretty straightforard) two-step "detect-then-match" video instance segmentation method. The first step performs instance segmentation for each frame to get a large number of instance mask proposals. The second step is to do inter-frame instance mask matching with the help of optical flow. We demonstrate that with high quality mask proposals, a simple matching mechanism is good enough for tracking. Our approach achieves the first place in the UVO 2021 Video-based Open-World Segmentation Challenge.
1st Place Solution for the UVO Challenge on Image-based Open-World Segmentation 2021
Oct 19, 2021



We describe our two-stage instance segmentation framework we use to compete in the challenge. The first stage of our framework consists of an object detector, which generates object proposals in the format of bounding boxes. Then, the images and the detected bounding boxes are fed to the second stage, where a segmentation network is applied to segment the objects in the bounding boxes. We train all our networks in a class-agnostic way. Our approach achieves the first place in the UVO 2021 Image-based Open-World Segmentation Challenge.
Multi-Person Extreme Motion Prediction with Cross-Interaction Attention
May 20, 2021
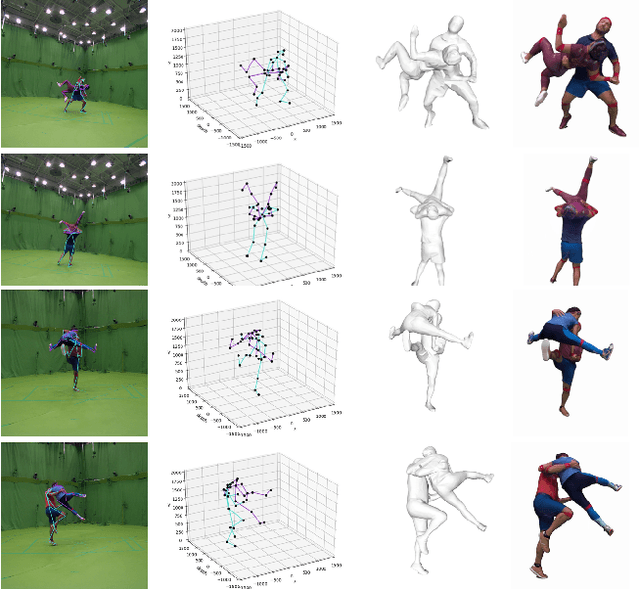


Human motion prediction aims to forecast future human poses given a sequence of past 3D skeletons. While this problem has recently received increasing attention, it has mostly been tackled for single humans in isolation. In this paper we explore this problem from a novel perspective, involving humans performing collaborative tasks. We assume that the input of our system are two sequences of past skeletons for two interacting persons, and we aim to predict the future motion for each of them. For this purpose, we devise a novel cross interaction attention mechanism that exploits historical information of both persons and learns to predict cross dependencies between self poses and the poses of the other person in spite of their spatial or temporal distance. Since no dataset to train such interactive situations is available, we have captured ExPI (Extreme Pose Interaction), a new lab-based person interaction dataset of professional dancers performing acrobatics. ExPI contains 115 sequences with 30k frames and 60k instances with annotated 3D body poses and shapes. We thoroughly evaluate our cross-interaction network on this dataset and show that both in short-term and long-term predictions, it consistently outperforms baselines that independently reason for each person. We plan to release our code jointly with the dataset and the train/test splits to spur future research on the topic.
PI-Net: Pose Interacting Network for Multi-Person Monocular 3D Pose Estimation
Oct 11, 2020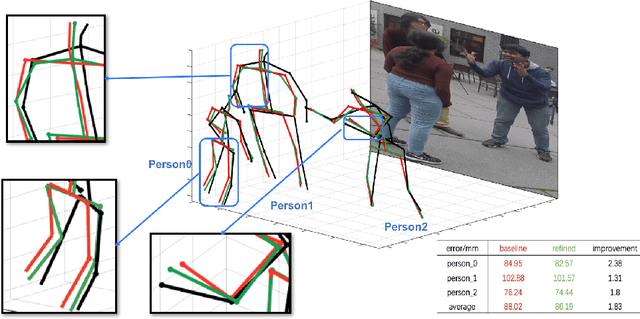
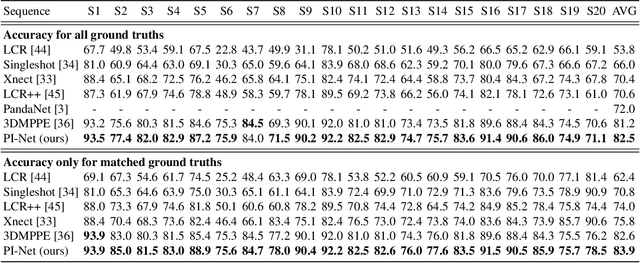
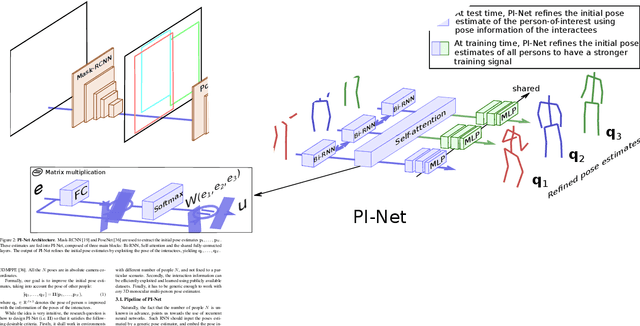
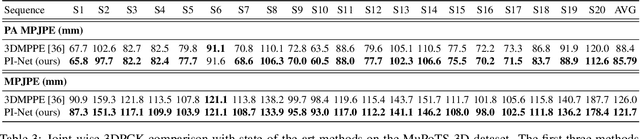
Recent literature addressed the monocular 3D pose estimation task very satisfactorily. In these studies, different persons are usually treated as independent pose instances to estimate. However, in many every-day situations, people are interacting, and the pose of an individual depends on the pose of his/her interactees. In this paper, we investigate how to exploit this dependency to enhance current - and possibly future - deep networks for 3D monocular pose estimation. Our pose interacting network, or PI-Net, inputs the initial pose estimates of a variable number of interactees into a recurrent architecture used to refine the pose of the person-of-interest. Evaluating such a method is challenging due to the limited availability of public annotated multi-person 3D human pose datasets. We demonstrate the effectiveness of our method in the MuPoTS dataset, setting the new state-of-the-art on it. Qualitative results on other multi-person datasets (for which 3D pose ground-truth is not available) showcase the proposed PI-Net. PI-Net is implemented in PyTorch and the code will be made available upon acceptance of the paper.
Towards a Systematic Computational Framework for Modeling Multi-Agent Decision-Making at Micro Level for Smart Vehicles in a Smart World
Sep 25, 2020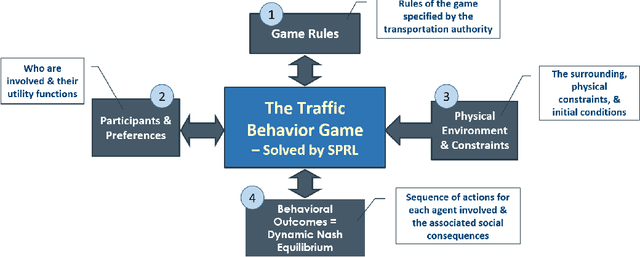
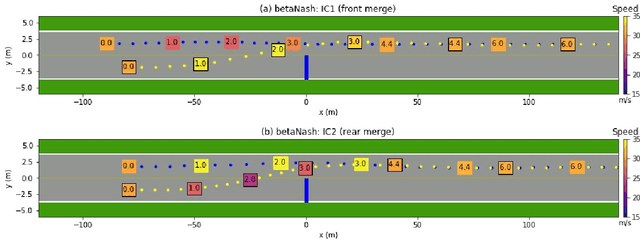
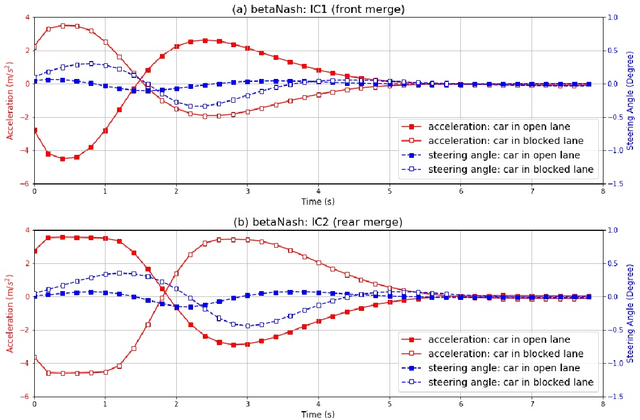
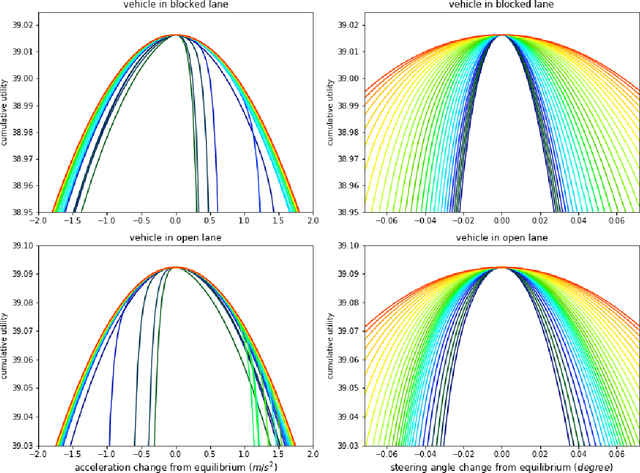
We propose a multi-agent based computational framework for modeling decision-making and strategic interaction at micro level for smart vehicles in a smart world. The concepts of Markov game and best response dynamics are heavily leveraged. Our aim is to make the framework conceptually sound and computationally practical for a range of realistic applications, including micro path planning for autonomous vehicles. To this end, we first convert the would-be stochastic game problem into a closely related deterministic one by introducing risk premium in the utility function for each individual agent. We show how the sub-game perfect Nash equilibrium of the simplified deterministic game can be solved by an algorithm based on best response dynamics. In order to better model human driving behaviors with bounded rationality, we seek to further simplify the solution concept by replacing the Nash equilibrium condition with a heuristic and adaptive optimization with finite look-ahead anticipation. In addition, the algorithm corresponding to the new solution concept drastically improves the computational efficiency. To demonstrate how our approach can be applied to realistic traffic settings, we conduct a simulation experiment: to derive merging and yielding behaviors on a double-lane highway with an unexpected barrier. Despite assumption differences involved in the two solution concepts, the derived numerical solutions show that the endogenized driving behaviors are very similar. We also briefly comment on how the proposed framework can be further extended in a number of directions in our forthcoming work, such as behavioral calibration using real traffic video data, computational mechanism design for traffic policy optimization, and so on.