 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiT-DVAE: Human Motion Generation via Hierarchical Transformer Dynamical VAE
Paper and Code
Apr 04, 2022
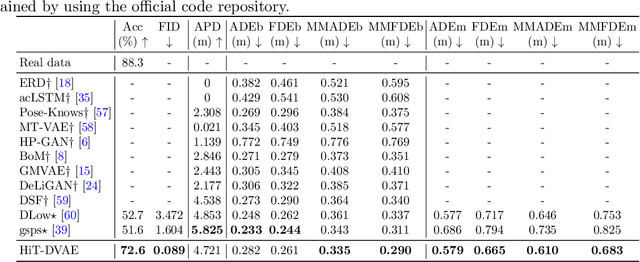
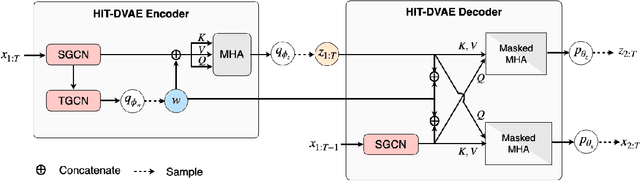
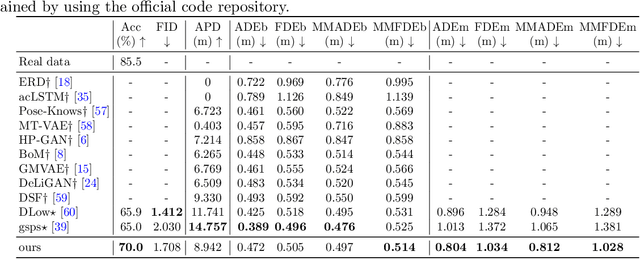
Studies on the automatic processing of 3D human pose data have flourished in the recent past. In this paper, we are interested in the generation of plausible and diverse future human poses following an observed 3D pose sequence. Current methods address this problem by injecting random variables from a single latent space into a deterministic motion prediction framework, which precludes the inherent multi-modality in human motion generation. In addition, previous works rarely explore the use of attention to select which frames are to be used to inform the generation process up to our knowledge. To overcome these limitations, we propose Hierarchical Transformer Dynamical Variational Autoencoder, HiT-DVAE, which implements auto-regressive generation with transformer-like attention mechanisms. HiT-DVAE simultaneously learns the evolution of data and latent space distribution with time correlated probabilistic dependencies, thus enabling the generative model to learn a more complex and time-varying latent space as well as diverse and realistic human motions. Furthermore, the auto-regressive generation brings more flexibility on observation and prediction, i.e. one can have any length of observation and predict arbitrary large sequences of poses with a single pre-trained model. We evaluate the proposed method on HumanEva-I and Human3.6M with various evaluation methods, and outperform the state-of-the-art methods on most of the metrics.