 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiff-TONE: Timestep Optimization for iNstrument Editing in Text-to-Music Diffusion Models
Jun 18, 2025Breakthroughs in text-to-music generation models are transforming the creative landscape, equipping musicians with innovative tools for composition and experimentation like never before. However, controlling the generation process to achieve a specific desired outcome remains a significant challenge. Even a minor change in the text prompt, combined with the same random seed, can drastically alter the generated piece. In this paper, we explore the application of existing text-to-music diffusion models for instrument editing. Specifically, for an existing audio track, we aim to leverage a pretrained text-to-music diffusion model to edit the instrument while preserving the underlying content. Based on the insight that the model first focuses on the overall structure or content of the audio, then adds instrument information, and finally refines the quality, we show that selecting a well-chosen intermediate timestep, identified through an instrument classifier, yields a balance between preserving the original piece's content and achieving the desired timbre. Our method does not require additional training of the text-to-music diffusion model, nor does it compromise the generation process's speed.
Using Random Codebooks for Audio Neural AutoEncoders
Sep 25, 2024



Latent representation learning has been an active field of study for decades in numerous applications. Inspired among others by the tokenization from Natural Language Processing and motivated by the research of a simple data representation, recent works have introduced a quantization step into the feature extraction. In this work, we propose a novel strategy to build the neural discrete representation by means of random codebooks. These codebooks are obtained by randomly sampling a large, predefined fixed codebook. We experimentally show the merits and potential of our approach in a task of audio compression and reconstruction.
Learning Source Disentanglement in Neural Audio Codec
Sep 17, 2024



Neural audio codecs have significantly advanced audio compression by efficiently converting continuous audio signals into discrete tokens. These codecs preserve high-quality sound and enable sophisticated sound generation through generative models trained on these tokens. However, existing neural codec models are typically trained on large, undifferentiated audio datasets, neglecting the essential discrepancies between sound domains like speech, music, and environmental sound effects. This oversight complicates data modeling and poses additional challenges to the controllability of sound generation. To tackle these issues, we introduce the Source-Disentangled Neural Audio Codec (SD-Codec), a novel approach that combines audio coding and source separation. By jointly learning audio resynthesis and separation, SD-Codec explicitly assigns audio signals from different domains to distinct codebooks, sets of discrete representations. Experimental results indicate that SD-Codec not only maintains competitive resynthesis quality but also, supported by the separation results, demonstrates successful disentanglement of different sources in the latent space, thereby enhancing interpretability in audio codec and providing potential finer control over the audio generation process.
Speech Modeling with a Hierarchical Transformer Dynamical VAE
Mar 07, 2023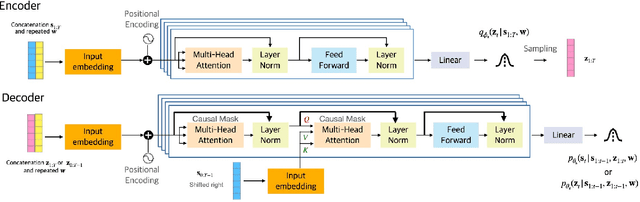
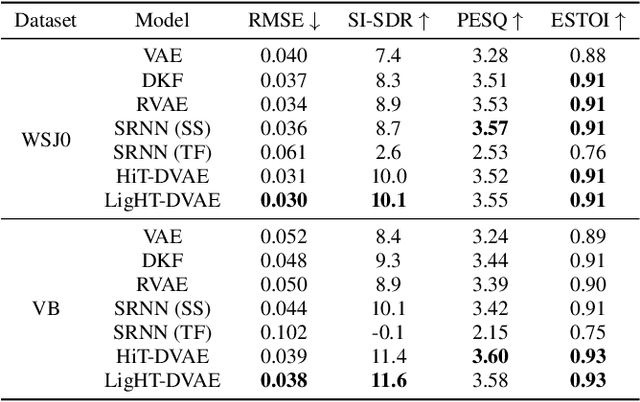
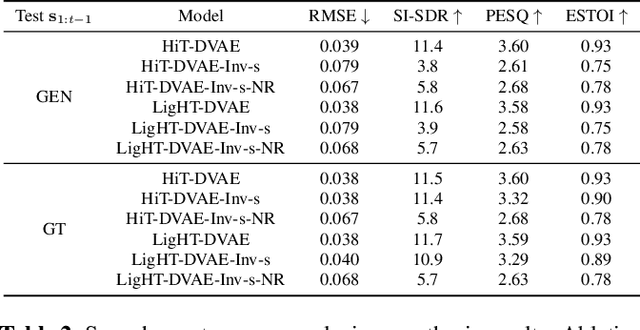
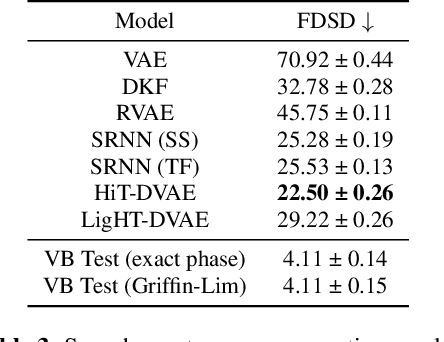
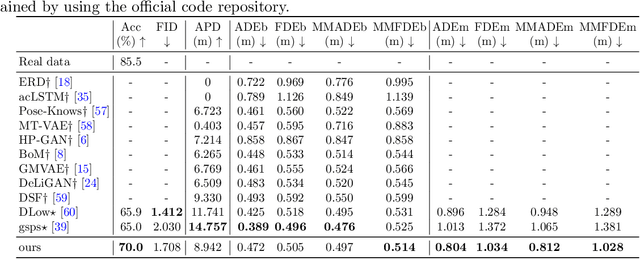
The dynamical variational autoencoders (DVAEs) are a family of latent-variable deep generative models that extends the VAE to model a sequence of observed data and a corresponding sequence of latent vectors. In almost all the DVAEs of the literature, the temporal dependencies within each sequence and across the two sequences are modeled with recurrent neural networks. In this paper, we propose to model speech signals with the Hierarchical Transformer DVAE (HiT-DVAE), which is a DVAE with two levels of latent variable (sequence-wise and frame-wise) and in which the temporal dependencies are implemented with the Transformer architecture. We show that HiT-DVAE outperforms several other DVAEs for speech spectrogram modeling, while enabling a simpler training procedure, revealing its high potential for downstream low-level speech processing tasks such as speech enhancement.
HiT-DVAE: Human Motion Generation via Hierarchical Transformer Dynamical VAE
Apr 04, 2022
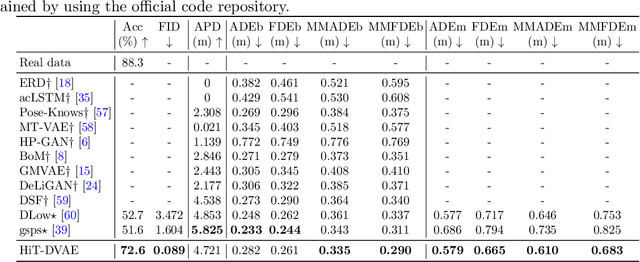
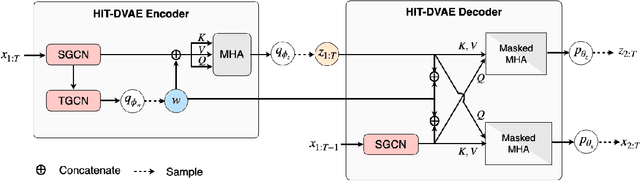
Studies on the automatic processing of 3D human pose data have flourished in the recent past. In this paper, we are interested in the generation of plausible and diverse future human poses following an observed 3D pose sequence. Current methods address this problem by injecting random variables from a single latent space into a deterministic motion prediction framework, which precludes the inherent multi-modality in human motion generation. In addition, previous works rarely explore the use of attention to select which frames are to be used to inform the generation process up to our knowledge. To overcome these limitations, we propose Hierarchical Transformer Dynamical Variational Autoencoder, HiT-DVAE, which implements auto-regressive generation with transformer-like attention mechanisms. HiT-DVAE simultaneously learns the evolution of data and latent space distribution with time correlated probabilistic dependencies, thus enabling the generative model to learn a more complex and time-varying latent space as well as diverse and realistic human motions. Furthermore, the auto-regressive generation brings more flexibility on observation and prediction, i.e. one can have any length of observation and predict arbitrary large sequences of poses with a single pre-trained model. We evaluate the proposed method on HumanEva-I and Human3.6M with various evaluation methods, and outperform the state-of-the-art methods on most of the metrics.
Unsupervised Speech Enhancement using Dynamical Variational Auto-Encoders
Jun 23, 2021
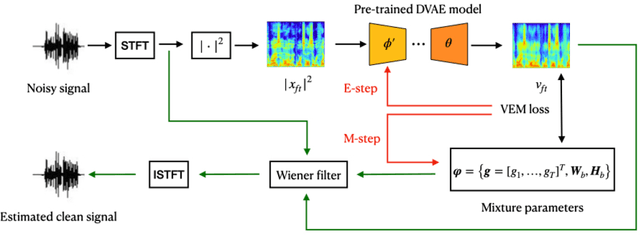
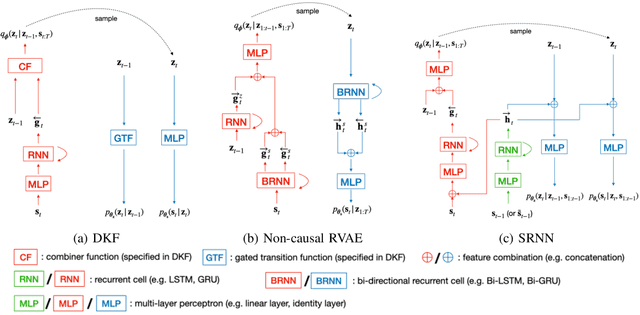
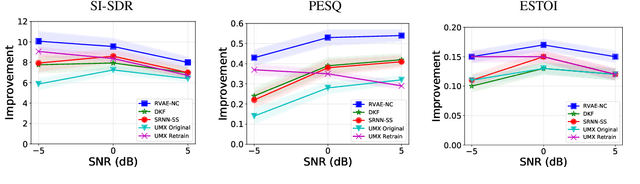
Dynamical variational auto-encoders (DVAEs) are a class of deep generative models with latent variables, dedicated to time series data modeling. DVAEs can be considered as extensions of the variational autoencoder (VAE) that include the modeling of temporal dependencies between successive observed and/or latent vectors in data sequences. Previous work has shown the interest of DVAEs and their better performance over the VAE for speech signals (spectrogram) modeling. Independently, the VAE has been successfully applied to speech enhancement in noise, in an unsupervised noise-agnostic set-up that does not require the use of a parallel dataset of clean and noisy speech samples for training, but only requires clean speech signals. In this paper, we extend those works to DVAE-based single-channel unsupervised speech enhancement, hence exploiting both speech signals unsupervised representation learning and dynamics modeling. We propose an unsupervised speech enhancement algorithm based on the most general form of DVAEs, that we then adapt to three specific DVAE models to illustrate the versatility of the framework. More precisely, we combine DVAE-based speech priors with a noise model based on nonnegative matrix factorization, and we derive a variational expectation-maximization (VEM) algorithm to perform speech enhancement. Experimental results show that the proposed approach based on DVAEs outperforms its VAE counterpart and a supervised speech enhancement baseline.
A Benchmark of Dynamical Variational Autoencoders applied to Speech Spectrogram Modeling
Jun 14, 2021

The Variational Autoencoder (VAE) is a powerful deep generative model that is now extensively used to represent high-dimensional complex data via a low-dimensional latent space learned in an unsupervised manner. In the original VAE model, input data vectors are processed independently. In recent years, a series of papers have presented different extensions of the VAE to process sequential data, that not only model the latent space, but also model the temporal dependencies within a sequence of data vectors and corresponding latent vectors, relying on recurrent neural networks. We recently performed a comprehensive review of those models and unified them into a general class called Dynamical Variational Autoencoders (DVAEs). In the present paper, we present the results of an experimental benchmark comparing six of those DVAE models on the speech analysis-resynthesis task, as an illustration of the high potential of DVAEs for speech modeling.
Multi-Person Extreme Motion Prediction with Cross-Interaction Attention
May 20, 2021
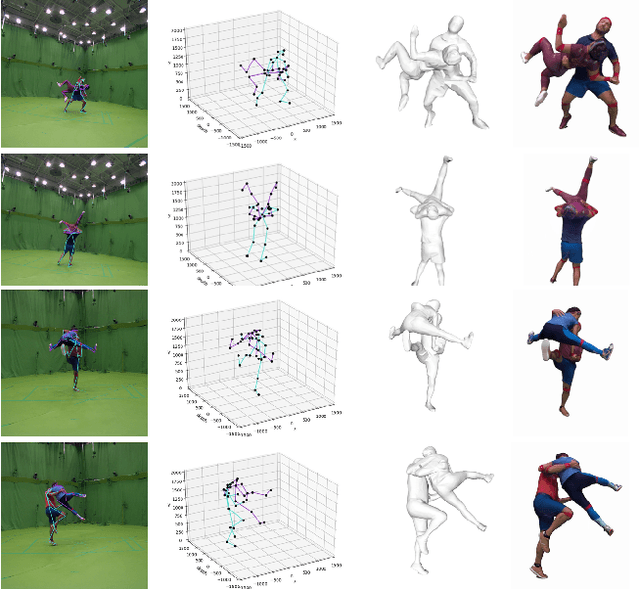


Human motion prediction aims to forecast future human poses given a sequence of past 3D skeletons. While this problem has recently received increasing attention, it has mostly been tackled for single humans in isolation. In this paper we explore this problem from a novel perspective, involving humans performing collaborative tasks. We assume that the input of our system are two sequences of past skeletons for two interacting persons, and we aim to predict the future motion for each of them. For this purpose, we devise a novel cross interaction attention mechanism that exploits historical information of both persons and learns to predict cross dependencies between self poses and the poses of the other person in spite of their spatial or temporal distance. Since no dataset to train such interactive situations is available, we have captured ExPI (Extreme Pose Interaction), a new lab-based person interaction dataset of professional dancers performing acrobatics. ExPI contains 115 sequences with 30k frames and 60k instances with annotated 3D body poses and shapes. We thoroughly evaluate our cross-interaction network on this dataset and show that both in short-term and long-term predictions, it consistently outperforms baselines that independently reason for each person. We plan to release our code jointly with the dataset and the train/test splits to spur future research on the topic.
Dynamical Variational Autoencoders: A Comprehensive Review
Aug 28, 2020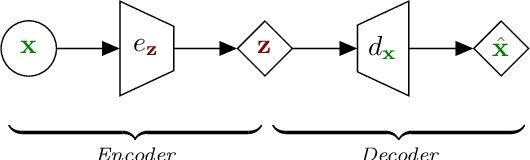

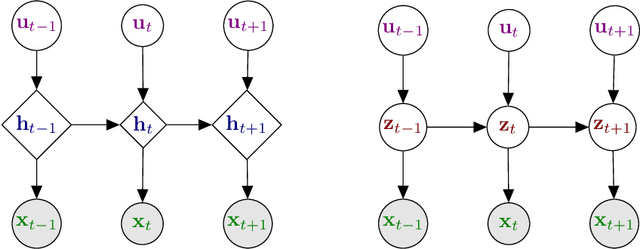
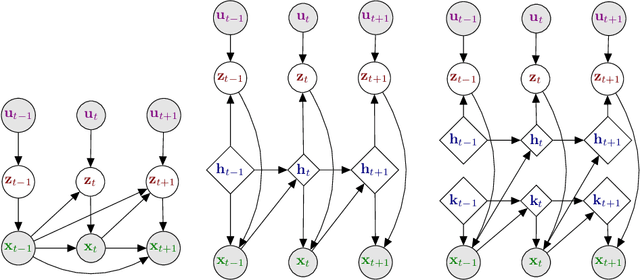
The Variational Autoencoder (VAE) is a powerful deep generative model that is now extensively used to represent high-dimensional complex data via a low-dimensional latent space that is learned in an unsupervised manner. In the original VAE model, input data vectors are processed independently. In the recent years, a series of papers have presented different extensions of the VAE to sequential data, that not only model the latent space, but also model the temporal dependencies within a sequence of data vectors and/or corresponding latent vectors, relying on recurrent neural networks or state space models. In this paper we perform an extensive literature review of these models. Importantly, we introduce and discuss a general class of models called Dynamical Variational Autoencoders (DVAEs) that encompass a large subset of these temporal VAE extensions. Then we present in details seven different instances of DVAE that were recently proposed in the literature, with an effort to homogenize the notations and presentation lines, as well as to relate those models with existing classical temporal models (that are also presented for the sake of completeness). We reimplemented those seven DVAE models and we present the results of an experimental benchmark that we conducted on the speech analysis-resynthesis task (the PyTorch code will be made publicly available). An extensive discussion is presented at the end of the paper, aiming to comment on important issues concerning the DVAE class of models and to describe future research guidelines.