 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenseAnnotate: Enabling Scalable Dense Caption Collection for Images and 3D Scenes via Spoken Descriptions
Nov 16, 2025With the rapid adoption of multimodal large language models (MLLMs) across diverse applications, there is a pressing need for task-centered, high-quality training data. A key limitation of current training datasets is their reliance on sparse annotations mined from the Internet or entered via manual typing that capture only a fraction of an image's visual content. Dense annotations are more valuable but remain scarce. Traditional text-based annotation pipelines are poorly suited for creating dense annotations: typing limits expressiveness, slows annotation speed, and underrepresents nuanced visual features, especially in specialized areas such as multicultural imagery and 3D asset annotation. In this paper, we present DenseAnnotate, an audio-driven online annotation platform that enables efficient creation of dense, fine-grained annotations for images and 3D assets. Annotators narrate observations aloud while synchronously linking spoken phrases to image regions or 3D scene parts. Our platform incorporates speech-to-text transcription and region-of-attention marking. To demonstrate the effectiveness of DenseAnnotate, we conducted case studies involving over 1,000 annotators across two domains: culturally diverse images and 3D scenes. We curate a human-annotated multi-modal dataset of 3,531 images, 898 3D scenes, and 7,460 3D objects, with audio-aligned dense annotations in 20 languages, including 8,746 image captions, 2,000 scene captions, and 19,000 object captions. Models trained on this dataset exhibit improvements of 5% in multilingual, 47% in cultural alignment, and 54% in 3D spatial capabilities. Our results show that our platform offers a feasible approach for future vision-language research and can be applied to various tasks and diverse types of data.
LimiX: Unleashing Structured-Data Modeling Capability for Generalist Intelligence
Sep 03, 2025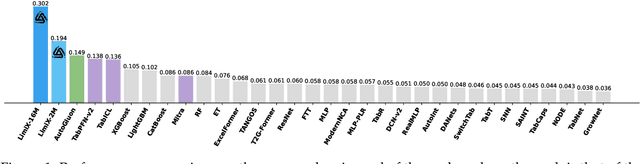
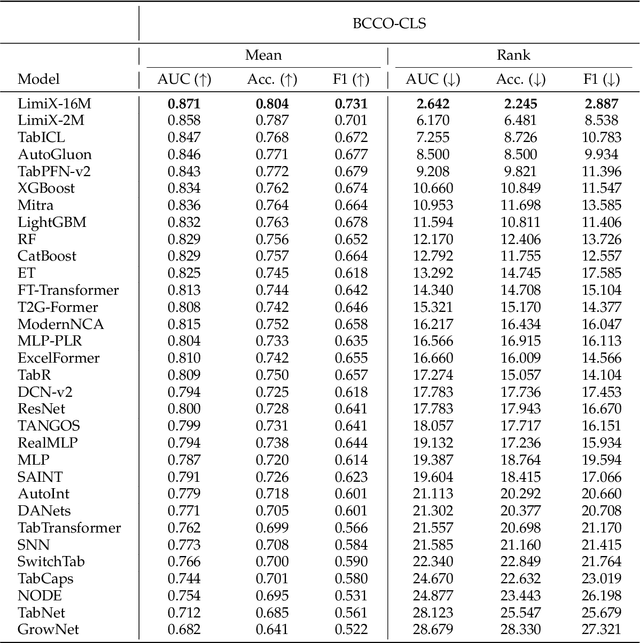
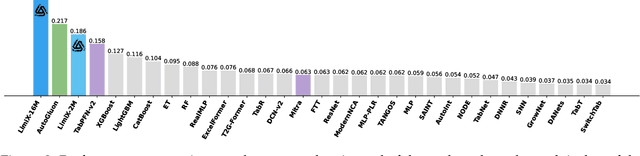
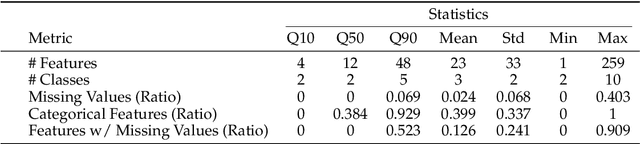
We argue that progress toward general intelligence requires complementary foundation models grounded in language, the physical world, and structured data. This report presents LimiX, the first installment of our large structured-data models (LDMs). LimiX treats structured data as a joint distribution over variables and missingness, thus capable of addressing a wide range of tabular tasks through query-based conditional prediction via a single model. LimiX is pretrained using masked joint-distribution modeling with an episodic, context-conditional objective, where the model predicts for query subsets conditioned on dataset-specific contexts, supporting rapid, training-free adaptation at inference. We evaluate LimiX across 10 large structured-data benchmarks with broad regimes of sample size, feature dimensionality, class number, categorical-to-numerical feature ratio, missingness, and sample-to-feature ratios. With a single model and a unified interface, LimiX consistently surpasses strong baselines including gradient-boosting trees, deep tabular networks, recent tabular foundation models, and automated ensembles, as shown in Figure 1 and Figure 2. The superiority holds across a wide range of tasks, such as classification, regression, missing value imputation, and data generation, often by substantial margins, while avoiding task-specific architectures or bespoke training per task. All LimiX models are publicly accessible under Apache 2.0.
DiverseDialogue: A Methodology for Designing Chatbots with Human-Like Diversity
Aug 30, 2024Large Language Models (LLMs), which simulate human users, are frequently employed to evaluate chatbots in applications such as tutoring and customer service. Effective evaluation necessitates a high degree of human-like diversity within these simulations. In this paper, we demonstrate that conversations generated by GPT-4o mini, when used as simulated human participants, systematically differ from those between actual humans across multiple linguistic features. These features include topic variation, lexical attributes, and both the average behavior and diversity (variance) of the language used. To address these discrepancies, we propose an approach that automatically generates prompts for user simulations by incorporating features derived from real human interactions, such as age, gender, emotional tone, and the topics discussed. We assess our approach using differential language analysis combined with deep linguistic inquiry. Our method of prompt optimization, tailored to target specific linguistic features, shows significant improvements. Specifically, it enhances the human-likeness of LLM chatbot conversations, increasing their linguistic diversity. On average, we observe a 54 percent reduction in the error of average features between human and LLM-generated conversations. This method of constructing chatbot sets with human-like diversity holds great potential for enhancing the evaluation process of user-facing bots.
Mixture of Dynamical Variational Autoencoders for Multi-Source Trajectory Modeling and Separation
Dec 07, 2023
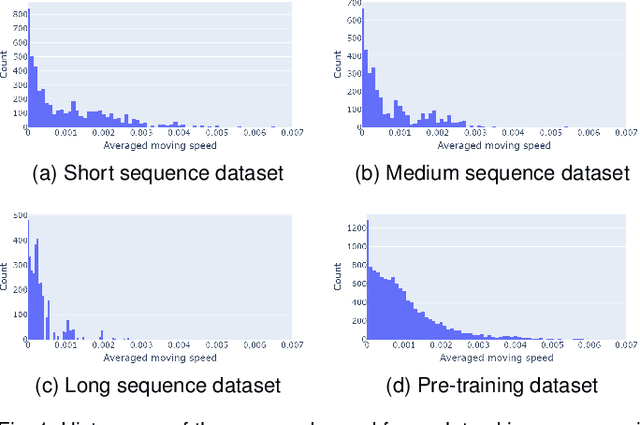

In this paper, we propose a latent-variable generative model called mixture of dynamical variational autoencoders (MixDVAE) to model the dynamics of a system composed of multiple moving sources. A DVAE model is pre-trained on a single-source dataset to capture the source dynamics. Then, multiple instances of the pre-trained DVAE model are integrated into a multi-source mixture model with a discrete observation-to-source assignment latent variable. The posterior distributions of both the discrete observation-to-source assignment variable and the continuous DVAE variables representing the sources content/position are estimated using a variational expectation-maximization algorithm, leading to multi-source trajectories estimation. We illustrate the versatility of the proposed MixDVAE model on two tasks: a computer vision task, namely multi-object tracking, and an audio processing task, namely single-channel audio source separation. Experimental results show that the proposed method works well on these two tasks, and outperforms several baseline methods.
Unsupervised speech enhancement with deep dynamical generative speech and noise models
Jun 13, 2023This work builds on a previous work on unsupervised speech enhancement using a dynamical variational autoencoder (DVAE) as the clean speech model and non-negative matrix factorization (NMF) as the noise model. We propose to replace the NMF noise model with a deep dynamical generative model (DDGM) depending either on the DVAE latent variables, or on the noisy observations, or on both. This DDGM can be trained in three configurations: noise-agnostic, noise-dependent and noise adaptation after noise-dependent training. Experimental results show that the proposed method achieves competitive performance compared to state-of-the-art unsupervised speech enhancement methods, while the noise-dependent training configuration yields a much more time-efficient inference process.
Speech Modeling with a Hierarchical Transformer Dynamical VAE
Mar 07, 2023The dynamical variational autoencoders (DVAEs) are a family of latent-variable deep generative models that extends the VAE to model a sequence of observed data and a corresponding sequence of latent vectors. In almost all the DVAEs of the literature, the temporal dependencies within each sequence and across the two sequences are modeled with recurrent neural networks. In this paper, we propose to model speech signals with the Hierarchical Transformer DVAE (HiT-DVAE), which is a DVAE with two levels of latent variable (sequence-wise and frame-wise) and in which the temporal dependencies are implemented with the Transformer architecture. We show that HiT-DVAE outperforms several other DVAEs for speech spectrogram modeling, while enabling a simpler training procedure, revealing its high potential for downstream low-level speech processing tasks such as speech enhancement.
DSR: Towards Drone Image Super-Resolution
Aug 25, 2022
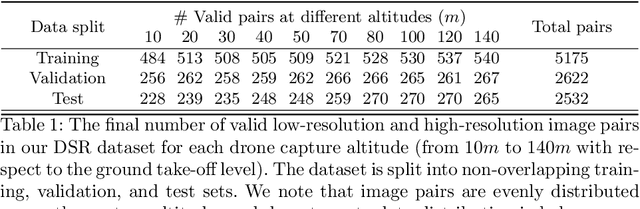

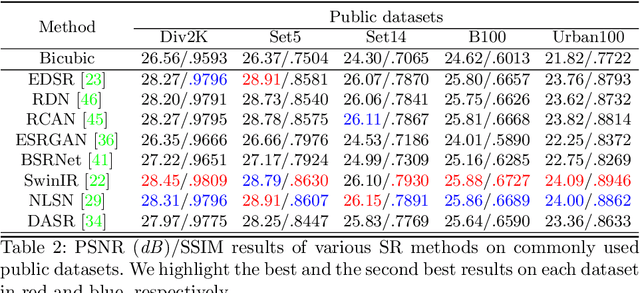
Despite achieving remarkable progress in recent years, single-image super-resolution methods are developed with several limitations. Specifically, they are trained on fixed content domains with certain degradations (whether synthetic or real). The priors they learn are prone to overfitting the training configuration. Therefore, the generalization to novel domains such as drone top view data, and across altitudes, is currently unknown. Nonetheless, pairing drones with proper image super-resolution is of great value. It would enable drones to fly higher covering larger fields of view, while maintaining a high image quality. To answer these questions and pave the way towards drone image super-resolution, we explore this application with particular focus on the single-image case. We propose a novel drone image dataset, with scenes captured at low and high resolutions, and across a span of altitudes. Our results show that off-the-shelf state-of-the-art networks witness a significant drop in performance on this different domain. We additionally show that simple fine-tuning, and incorporating altitude awareness into the network's architecture, both improve the reconstruction performance.
Towards Robust Drone Vision in the Wild
Aug 21, 2022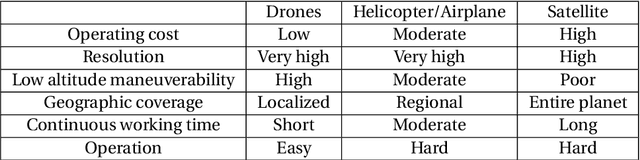


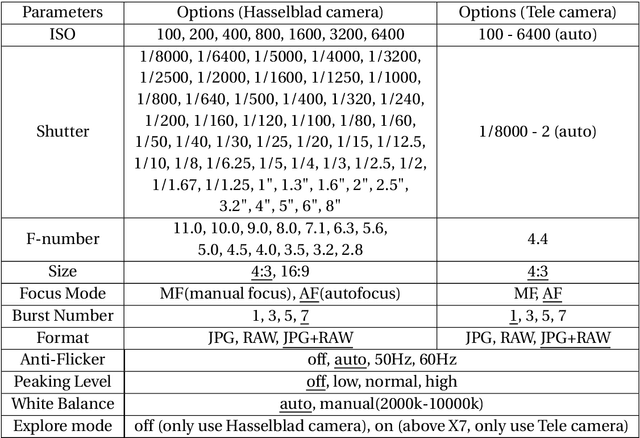
The past few years have witnessed the burst of drone-based applications where computer vision plays an essential role. However, most public drone-based vision datasets focus on detection and tracking. On the other hand, the performance of most existing image super-resolution methods is sensitive to the dataset, specifically, the degradation model between high-resolution and low-resolution images. In this thesis, we propose the first image super-resolution dataset for drone vision. Image pairs are captured by two cameras on the drone with different focal lengths. We collect data at different altitudes and then propose pre-processing steps to align image pairs. Extensive empirical studies show domain gaps exist among images captured at different altitudes. Meanwhile, the performance of pretrained image super-resolution networks also suffers a drop on our dataset and varies among altitudes. Finally, we propose two methods to build a robust image super-resolution network at different altitudes. The first feeds altitude information into the network through altitude-aware layers. The second uses one-shot learning to quickly adapt the super-resolution model to unknown altitudes. Our results reveal that the proposed methods can efficiently improve the performance of super-resolution networks at varying altitudes.
Unsupervised Multiple-Object Tracking with a Dynamical Variational Autoencoder
Feb 21, 2022

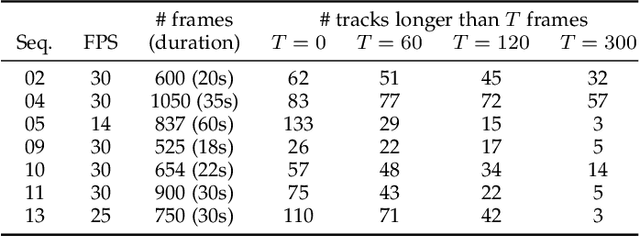

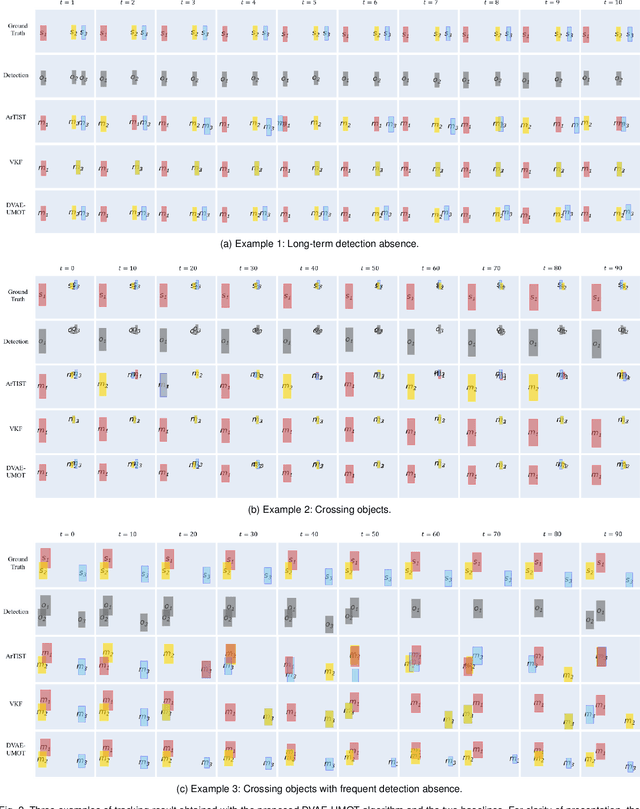
In this paper, we present an unsupervised probabilistic model and associated estimation algorithm for multi-object tracking (MOT) based on a dynamical variational autoencoder (DVAE), called DVAE-UMOT. The DVAE is a latent-variable deep generative model that can be seen as an extension of the variational autoencoder for the modeling of temporal sequences. It is included in DVAE-UMOT to model the objects' dynamics, after being pre-trained on an unlabeled synthetic dataset of single-object trajectories. Then the distributions and parameters of DVAE-UMOT are estimated on each multi-object sequence to track using the principles of variational inference: Definition of an approximate posterior distribution of the latent variables and maximization of the corresponding evidence lower bound of the data likehood function. DVAE-UMOT is shown experimentally to compete well with and even surpass the performance of two state-of-the-art probabilistic MOT models. Code and data are publicly available.
Fidelity Estimation Improves Noisy-Image Classification with Pretrained Networks
Jun 01, 2021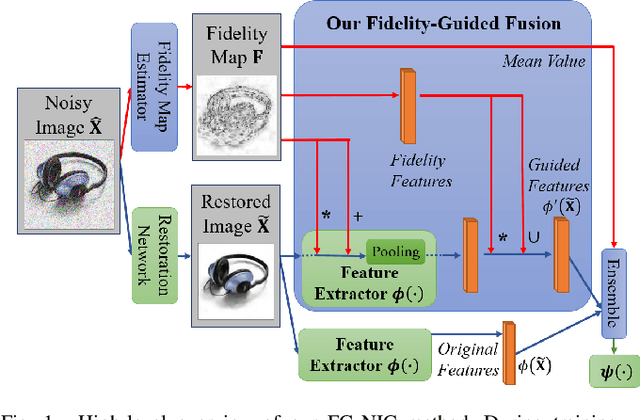


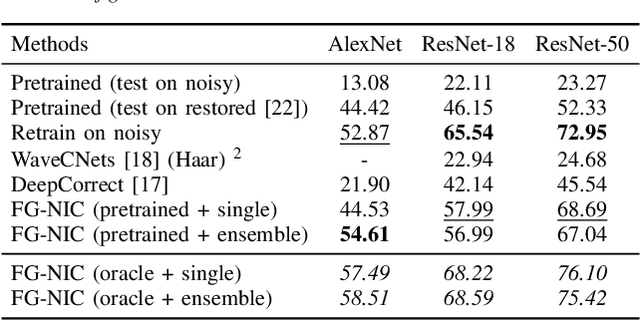
Image classification has significantly improved using deep learning. This is mainly due to convolutional neural networks (CNNs) that are capable of learning rich feature extractors from large datasets. However, most deep learning classification methods are trained on clean images and are not robust when handling noisy ones, even if a restoration preprocessing step is applied. While novel methods address this problem, they rely on modified feature extractors and thus necessitate retraining. We instead propose a method that can be applied on a pretrained classifier. Our method exploits a fidelity map estimate that is fused into the internal representations of the feature extractor, thereby guiding the attention of the network and making it more robust to noisy data. We improve the noisy-image classification (NIC) results by significantly large margins, especially at high noise levels, and come close to the fully retrained approaches. Furthermore, as proof of concept, we show that when using our oracle fidelity map we even outperform the fully retrained methods, whether trained on noisy or restored images.