 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Comics: The AI4VA Dataset for Visual Understanding
Oct 27, 2024


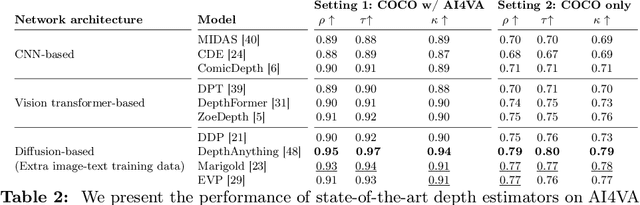
In the evolving landscape of deep learning, there is a pressing need for more comprehensive datasets capable of training models across multiple modalities. Concurrently, in digital humanities, there is a growing demand to leverage technology for diverse media adaptation and creation, yet limited by sparse datasets due to copyright and stylistic constraints. Addressing this gap, our paper presents a novel dataset comprising Franco-Belgian comics from the 1950s annotated for tasks including depth estimation, semantic segmentation, saliency detection, and character identification. It consists of two distinct and consistent styles and incorporates object concepts and labels taken from natural images. By including such diverse information across styles, this dataset not only holds promise for computational creativity but also offers avenues for the digitization of art and storytelling innovation. This dataset is a crucial component of the AI4VA Workshop Challenges~\url{https://sites.google.com/view/ai4vaeccv2024}, where we specifically explore depth and saliency. Dataset details at \url{https://github.com/IVRL/AI4VA}.
OMH: Structured Sparsity via Optimally Matched Hierarchy for Unsupervised Semantic Segmentation
Mar 11, 2024
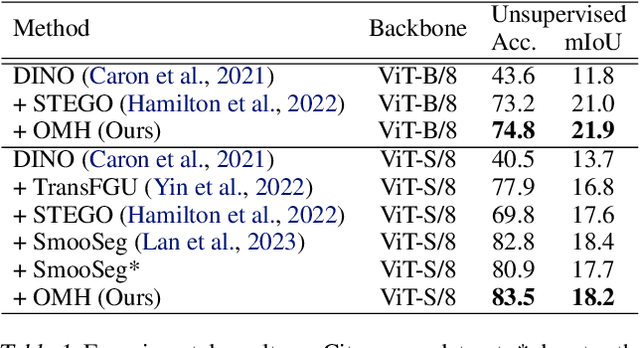
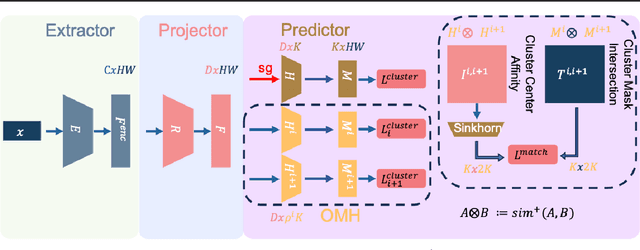

Unsupervised Semantic Segmentation (USS) involves segmenting images without relying on predefined labels, aiming to alleviate the burden of extensive human labeling. Existing methods utilize features generated by self-supervised models and specific priors for clustering. However, their clustering objectives are not involved in the optimization of the features during training. Additionally, due to the lack of clear class definitions in USS, the resulting segments may not align well with the clustering objective. In this paper, we introduce a novel approach called Optimally Matched Hierarchy (OMH) to simultaneously address the above issues. The core of our method lies in imposing structured sparsity on the feature space, which allows the features to encode information with different levels of granularity. The structure of this sparsity stems from our hierarchy (OMH). To achieve this, we learn a soft but sparse hierarchy among parallel clusters through Optimal Transport. Our OMH yields better unsupervised segmentation performance compared to existing USS methods. Our extensive experiments demonstrate the benefits of OMH when utilizing our differentiable paradigm. We will make our code publicly available.
DSI2I: Dense Style for Unpaired Image-to-Image Translation
Dec 29, 2022Unpaired exemplar-based image-to-image (UEI2I) translation aims to translate a source image to a target image domain with the style of a target image exemplar, without ground-truth input-translation pairs. Existing UEI2I methods represent style using either a global, image-level feature vector, or one vector per object instance/class but requiring knowledge of the scene semantics. Here, by contrast, we propose to represent style as a dense feature map, allowing for a finer-grained transfer to the source image without requiring any external semantic information. We then rely on perceptual and adversarial losses to disentangle our dense style and content representations, and exploit unsupervised cross-domain semantic correspondences to warp the exemplar style to the source content. We demonstrate the effectiveness of our method on two datasets using standard metrics together with a new localized style metric measuring style similarity in a class-wise manner. Our results evidence that the translations produced by our approach are more diverse and closer to the exemplars than those of the state-of-the-art methods while nonetheless preserving the source content.
DSR: Towards Drone Image Super-Resolution
Aug 25, 2022
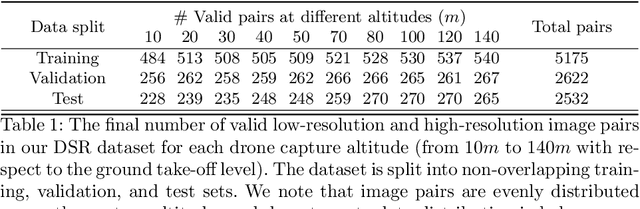

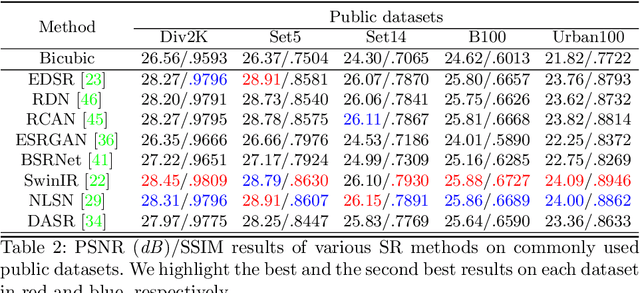
Despite achieving remarkable progress in recent years, single-image super-resolution methods are developed with several limitations. Specifically, they are trained on fixed content domains with certain degradations (whether synthetic or real). The priors they learn are prone to overfitting the training configuration. Therefore, the generalization to novel domains such as drone top view data, and across altitudes, is currently unknown. Nonetheless, pairing drones with proper image super-resolution is of great value. It would enable drones to fly higher covering larger fields of view, while maintaining a high image quality. To answer these questions and pave the way towards drone image super-resolution, we explore this application with particular focus on the single-image case. We propose a novel drone image dataset, with scenes captured at low and high resolutions, and across a span of altitudes. Our results show that off-the-shelf state-of-the-art networks witness a significant drop in performance on this different domain. We additionally show that simple fine-tuning, and incorporating altitude awareness into the network's architecture, both improve the reconstruction performance.