 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Comics: The AI4VA Dataset for Visual Understanding
Oct 27, 2024


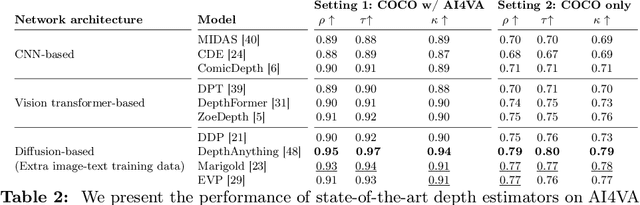
In the evolving landscape of deep learning, there is a pressing need for more comprehensive datasets capable of training models across multiple modalities. Concurrently, in digital humanities, there is a growing demand to leverage technology for diverse media adaptation and creation, yet limited by sparse datasets due to copyright and stylistic constraints. Addressing this gap, our paper presents a novel dataset comprising Franco-Belgian comics from the 1950s annotated for tasks including depth estimation, semantic segmentation, saliency detection, and character identification. It consists of two distinct and consistent styles and incorporates object concepts and labels taken from natural images. By including such diverse information across styles, this dataset not only holds promise for computational creativity but also offers avenues for the digitization of art and storytelling innovation. This dataset is a crucial component of the AI4VA Workshop Challenges~\url{https://sites.google.com/view/ai4vaeccv2024}, where we specifically explore depth and saliency. Dataset details at \url{https://github.com/IVRL/AI4VA}.
Data Augmentation via Latent Diffusion for Saliency Prediction
Sep 11, 2024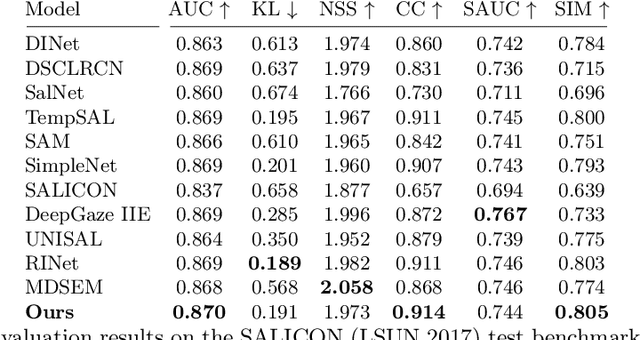
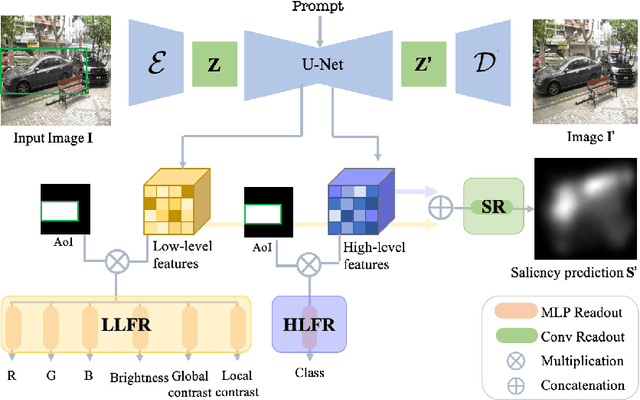


Saliency prediction models are constrained by the limited diversity and quantity of labeled data. Standard data augmentation techniques such as rotating and cropping alter scene composition, affecting saliency. We propose a novel data augmentation method for deep saliency prediction that edits natural images while preserving the complexity and variability of real-world scenes. Since saliency depends on high-level and low-level features, our approach involves learning both by incorporating photometric and semantic attributes such as color, contrast, brightness, and class. To that end, we introduce a saliency-guided cross-attention mechanism that enables targeted edits on the photometric properties, thereby enhancing saliency within specific image regions. Experimental results show that our data augmentation method consistently improves the performance of various saliency models. Moreover, leveraging the augmentation features for saliency prediction yields superior performance on publicly available saliency benchmarks. Our predictions align closely with human visual attention patterns in the edited images, as validated by a user study.
TempSAL -- Uncovering Temporal Information for Deep Saliency Prediction
Jan 05, 2023Deep saliency prediction algorithms complement the object recognition features, they typically rely on additional information, such as scene context, semantic relationships, gaze direction, and object dissimilarity. However, none of these models consider the temporal nature of gaze shifts during image observation. We introduce a novel saliency prediction model that learns to output saliency maps in sequential time intervals by exploiting human temporal attention patterns. Our approach locally modulates the saliency predictions by combining the learned temporal maps. Our experiments show that our method outperforms the state-of-the-art models, including a multi-duration saliency model, on the SALICON benchmark. Our code will be publicly available on GitHub.
Modeling Object Dissimilarity for Deep Saliency Prediction
Apr 08, 2021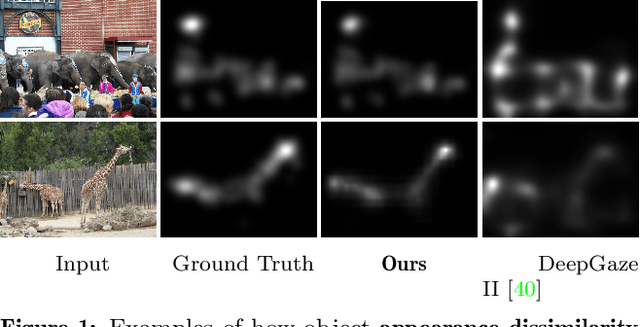
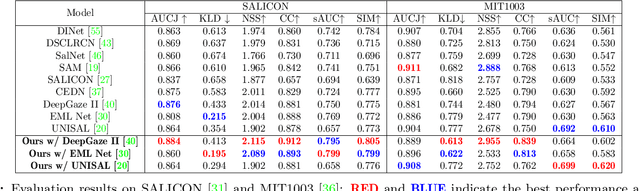


Saliency prediction has made great strides over the past two decades, with current techniques modeling low-level information, such as color, intensity and size contrasts, and high-level one, such as attention and gaze direction for entire objects. Despite this, these methods fail to account for the dissimilarity between objects, which humans naturally do. In this paper, we introduce a detection-guided saliency prediction network that explicitly models the differences between multiple objects, such as their appearance and size dissimilarities. Our approach is general, allowing us to fuse our object dissimilarities with features extracted by any deep saliency prediction network. As evidenced by our experiments, this consistently boosts the accuracy of the baseline networks, enabling us to outperform the state-of-the-art models on three saliency benchmarks, namely SALICON, MIT300 and CAT2000.