 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Object Dissimilarity for Deep Saliency Prediction
Paper and Code
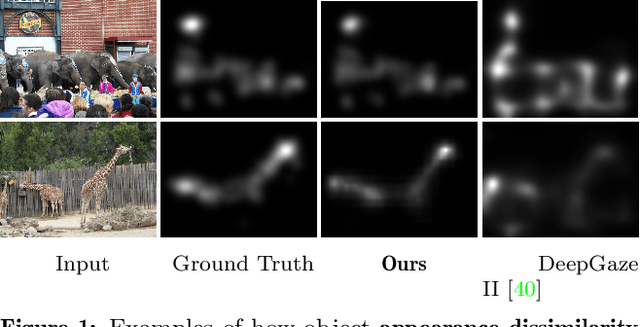
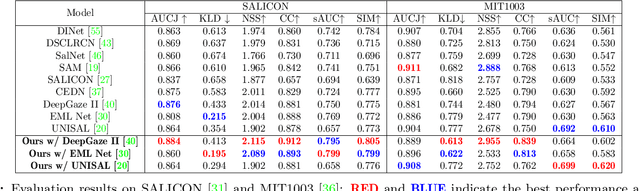


Saliency prediction has made great strides over the past two decades, with current techniques modeling low-level information, such as color, intensity and size contrasts, and high-level one, such as attention and gaze direction for entire objects. Despite this, these methods fail to account for the dissimilarity between objects, which humans naturally do. In this paper, we introduce a detection-guided saliency prediction network that explicitly models the differences between multiple objects, such as their appearance and size dissimilarities. Our approach is general, allowing us to fuse our object dissimilarities with features extracted by any deep saliency prediction network. As evidenced by our experiments, this consistently boosts the accuracy of the baseline networks, enabling us to outperform the state-of-the-art models on three saliency benchmarks, namely SALICON, MIT300 and CAT2000.