 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Comics: The AI4VA Dataset for Visual Understanding
Paper and Code



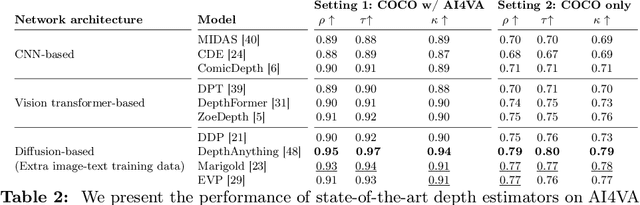
In the evolving landscape of deep learning, there is a pressing need for more comprehensive datasets capable of training models across multiple modalities. Concurrently, in digital humanities, there is a growing demand to leverage technology for diverse media adaptation and creation, yet limited by sparse datasets due to copyright and stylistic constraints. Addressing this gap, our paper presents a novel dataset comprising Franco-Belgian comics from the 1950s annotated for tasks including depth estimation, semantic segmentation, saliency detection, and character identification. It consists of two distinct and consistent styles and incorporates object concepts and labels taken from natural images. By including such diverse information across styles, this dataset not only holds promise for computational creativity but also offers avenues for the digitization of art and storytelling innovation. This dataset is a crucial component of the AI4VA Workshop Challenges~\url{https://sites.google.com/view/ai4vaeccv2024}, where we specifically explore depth and saliency. Dataset details at \url{https://github.com/IVRL/AI4VA}.