 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling strategies for speech enhancement in the latent space of a neural audio codec
Oct 30, 2025Neural audio codecs (NACs) provide compact latent speech representations in the form of sequences of continuous vectors or discrete tokens. In this work, we investigate how these two types of speech representations compare when used as training targets for supervised speech enhancement. We consider both autoregressive and non-autoregressive speech enhancement models based on the Conformer architecture, as well as a simple baseline where the NAC encoder is simply fine-tuned for speech enhancement. Our experiments reveal three key findings: predicting continuous latent representations consistently outperforms discrete token prediction; autoregressive models achieve higher quality but at the expense of intelligibility and efficiency, making non-autoregressive models more attractive in practice; and encoder fine-tuning yields the strongest enhancement metrics overall, though at the cost of degraded codec reconstruction. The code and audio samples are available online.
AnCoGen: Analysis, Control and Generation of Speech with a Masked Autoencoder
Jan 09, 2025This article introduces AnCoGen, a novel method that leverages a masked autoencoder to unify the analysis, control, and generation of speech signals within a single model. AnCoGen can analyze speech by estimating key attributes, such as speaker identity, pitch, content, loudness, signal-to-noise ratio, and clarity index. In addition, it can generate speech from these attributes and allow precise control of the synthesized speech by modifying them. Extensive experiments demonstrated the effectiveness of AnCoGen across speech analysis-resynthesis, pitch estimation, pitch modification, and speech enhancement.
MEGA: Masked Generative Autoencoder for Human Mesh Recovery
May 29, 2024Human Mesh Recovery (HMR) from a single RGB image is a highly ambiguous problem, as similar 2D projections can correspond to multiple 3D interpretations. Nevertheless, most HMR methods overlook this ambiguity and make a single prediction without accounting for the associated uncertainty. A few approaches generate a distribution of human meshes, enabling the sampling of multiple predictions; however, none of them is competitive with the latest single-output model when making a single prediction. This work proposes a new approach based on masked generative modeling. By tokenizing the human pose and shape, we formulate the HMR task as generating a sequence of discrete tokens conditioned on an input image. We introduce MEGA, a MaskEd Generative Autoencoder trained to recover human meshes from images and partial human mesh token sequences. Given an image, our flexible generation scheme allows us to predict a single human mesh in deterministic mode or to generate multiple human meshes in stochastic mode. MEGA enables us to propose multiple outputs and to evaluate the uncertainty of the predictions. Experiments on in-the-wild benchmarks show that MEGA achieves state-of-the-art performance in deterministic and stochastic modes, outperforming single-output and multi-output approaches.
Objective and subjective evaluation of speech enhancement methods in the UDASE task of the 7th CHiME challenge
Feb 02, 2024



Supervised models for speech enhancement are trained using artificially generated mixtures of clean speech and noise signals. However, the synthetic training conditions may not accurately reflect real-world conditions encountered during testing. This discrepancy can result in poor performance when the test domain significantly differs from the synthetic training domain. To tackle this issue, the UDASE task of the 7th CHiME challenge aimed to leverage real-world noisy speech recordings from the test domain for unsupervised domain adaptation of speech enhancement models. Specifically, this test domain corresponds to the CHiME-5 dataset, characterized by real multi-speaker and conversational speech recordings made in noisy and reverberant domestic environments, for which ground-truth clean speech signals are not available. In this paper, we present the objective and subjective evaluations of the systems that were submitted to the CHiME-7 UDASE task, and we provide an analysis of the results. This analysis reveals a limited correlation between subjective ratings and several supervised nonintrusive performance metrics recently proposed for speech enhancement. Conversely, the results suggest that more traditional intrusive objective metrics can be used for in-domain performance evaluation using the reverberant LibriCHiME-5 dataset developed for the challenge. The subjective evaluation indicates that all systems successfully reduced the background noise, but always at the expense of increased distortion. Out of the four speech enhancement methods evaluated subjectively, only one demonstrated an improvement in overall quality compared to the unprocessed noisy speech, highlighting the difficulty of the task. The tools and audio material created for the CHiME-7 UDASE task are shared with the community.
VQ-HPS: Human Pose and Shape Estimation in a Vector-Quantized Latent Space
Dec 13, 2023



Human Pose and Shape Estimation (HPSE) from RGB images can be broadly categorized into two main groups: parametric and non-parametric approaches. Parametric techniques leverage a low-dimensional statistical body model for realistic results, whereas recent non-parametric methods achieve higher precision by directly regressing the 3D coordinates of the human body. Despite their strengths, both approaches face limitations: the parameters of statistical body models pose challenges as regression targets, and predicting 3D coordinates introduces computational complexities and issues related to smoothness. In this work, we take a novel approach to address the HPSE problem. We introduce a unique method involving a low-dimensional discrete latent representation of the human mesh, framing HPSE as a classification task. Instead of predicting body model parameters or 3D vertex coordinates, our focus is on forecasting the proposed discrete latent representation, which can be decoded into a registered human mesh. This innovative paradigm offers two key advantages: firstly, predicting a low-dimensional discrete representation confines our predictions to the space of anthropomorphic poses and shapes; secondly, by framing the problem as a classification task, we can harness the discriminative power inherent in neural networks. Our proposed model, VQ-HPS, a transformer-based architecture, forecasts the discrete latent representation of the mesh, trained through minimizing a cross-entropy loss. Our results demonstrate that VQ-HPS outperforms the current state-of-the-art non-parametric approaches while yielding results as realistic as those produced by parametric methods. This highlights the significant potential of the classification approach for HPSE.
The CHiME-7 UDASE task: Unsupervised domain adaptation for conversational speech enhancement
Jul 07, 2023Supervised speech enhancement models are trained using artificially generated mixtures of clean speech and noise signals, which may not match real-world recording conditions at test time. This mismatch can lead to poor performance if the test domain significantly differs from the synthetic training domain. In this paper, we introduce the unsupervised domain adaptation for conversational speech enhancement (UDASE) task of the 7th CHiME challenge. This task aims to leverage real-world noisy speech recordings from the target test domain for unsupervised domain adaptation of speech enhancement models. The target test domain corresponds to the multi-speaker reverberant conversational speech recordings of the CHiME-5 dataset, for which the ground-truth clean speech reference is not available. Given a CHiME-5 recording, the task is to estimate the clean, potentially multi-speaker, reverberant speech, removing the additive background noise. We discuss the motivation for the CHiME-7 UDASE task and describe the data, the task, and the baseline system.
Unsupervised speech enhancement with deep dynamical generative speech and noise models
Jun 13, 2023

This work builds on a previous work on unsupervised speech enhancement using a dynamical variational autoencoder (DVAE) as the clean speech model and non-negative matrix factorization (NMF) as the noise model. We propose to replace the NMF noise model with a deep dynamical generative model (DDGM) depending either on the DVAE latent variables, or on the noisy observations, or on both. This DDGM can be trained in three configurations: noise-agnostic, noise-dependent and noise adaptation after noise-dependent training. Experimental results show that the proposed method achieves competitive performance compared to state-of-the-art unsupervised speech enhancement methods, while the noise-dependent training configuration yields a much more time-efficient inference process.
Motion-DVAE: Unsupervised learning for fast human motion denoising
Jun 09, 2023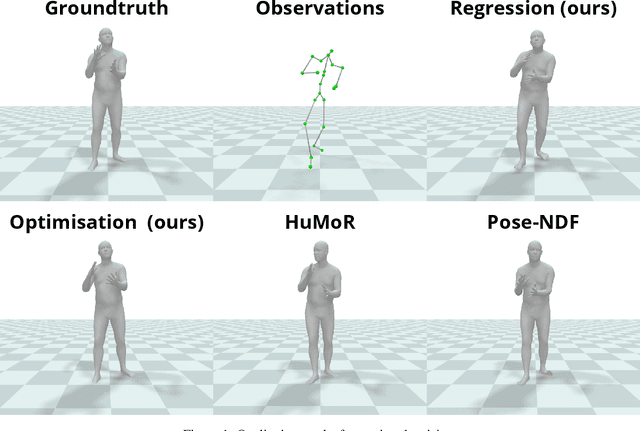



Pose and motion priors are crucial for recovering realistic and accurate human motion from noisy observations. Substantial progress has been made on pose and shape estimation from images, and recent works showed impressive results using priors to refine frame-wise predictions. However, a lot of motion priors only model transitions between consecutive poses and are used in time-consuming optimization procedures, which is problematic for many applications requiring real-time motion capture. We introduce Motion-DVAE, a motion prior to capture the short-term dependencies of human motion. As part of the dynamical variational autoencoder (DVAE) models family, Motion-DVAE combines the generative capability of VAE models and the temporal modeling of recurrent architectures. Together with Motion-DVAE, we introduce an unsupervised learned denoising method unifying regression- and optimization-based approaches in a single framework for real-time 3D human pose estimation. Experiments show that the proposed approach reaches competitive performance with state-of-the-art methods while being much faster.
A vector quantized masked autoencoder for audiovisual speech emotion recognition
May 05, 2023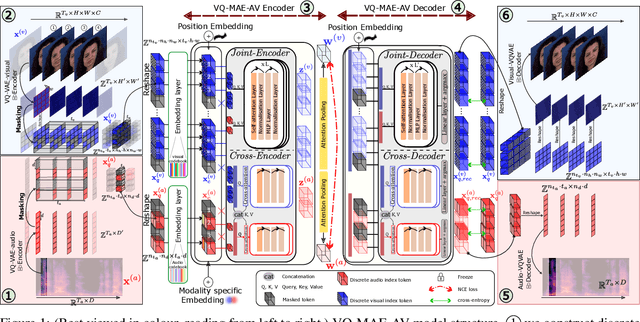
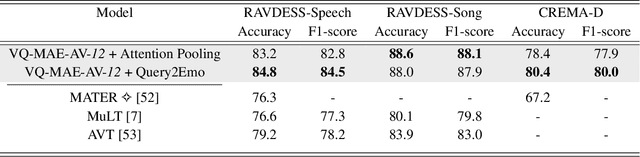
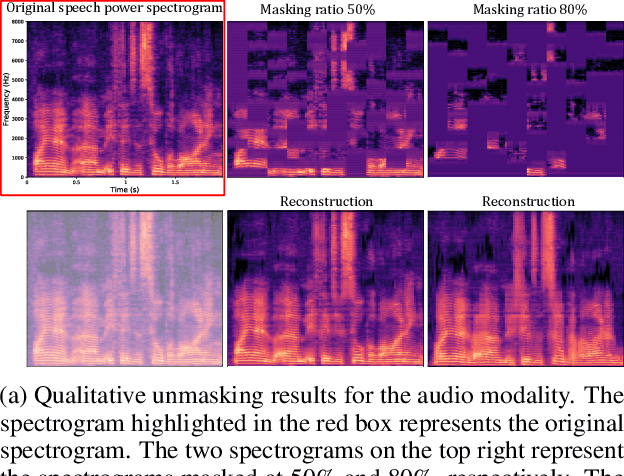
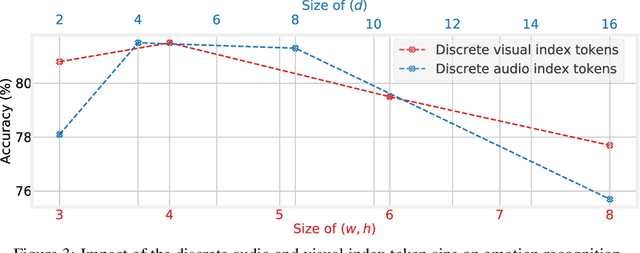
While fully-supervised models have been shown to be effective for audiovisual speech emotion recognition (SER), the limited availability of labeled data remains a major challenge in the field. To address this issue, self-supervised learning approaches, such as masked autoencoders (MAEs), have gained popularity as potential solutions. In this paper, we propose the VQ-MAE-AV model, a vector quantized MAE specifically designed for audiovisual speech self-supervised representation learning. Unlike existing multimodal MAEs that rely on the processing of the raw audiovisual speech data, the proposed method employs a self-supervised paradigm based on discrete audio and visual speech representations learned by two pre-trained vector quantized variational autoencoders. Experimental results show that the proposed approach, which is pre-trained on the VoxCeleb2 database and fine-tuned on standard emotional audiovisual speech datasets, outperforms the state-of-the-art audiovisual SER methods.
A Multimodal Dynamical Variational Autoencoder for Audiovisual Speech Representation Learning
May 05, 2023In this paper, we present a multimodal \textit{and} dynamical VAE (MDVAE) applied to unsupervised audio-visual speech representation learning. The latent space is structured to dissociate the latent dynamical factors that are shared between the modalities from those that are specific to each modality. A static latent variable is also introduced to encode the information that is constant over time within an audiovisual speech sequence. The model is trained in an unsupervised manner on an audiovisual emotional speech dataset, in two stages. In the first stage, a vector quantized VAE (VQ-VAE) is learned independently for each modality, without temporal modeling. The second stage consists in learning the MDVAE model on the intermediate representation of the VQ-VAEs before quantization. The disentanglement between static versus dynamical and modality-specific versus modality-common information occurs during this second training stage. Extensive experiments are conducted to investigate how audiovisual speech latent factors are encoded in the latent space of MDVAE. These experiments include manipulating audiovisual speech, audiovisual facial image denoising, and audiovisual speech emotion recognition. The results show that MDVAE effectively combines the audio and visual information in its latent space. They also show that the learned static representation of audiovisual speech can be used for emotion recognition with few labeled data, and with better accuracy compared with unimodal baselines and a state-of-the-art supervised model based on an audiovisual transformer architecture.