 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA vector quantized masked autoencoder for speech emotion recognition
Paper and Code
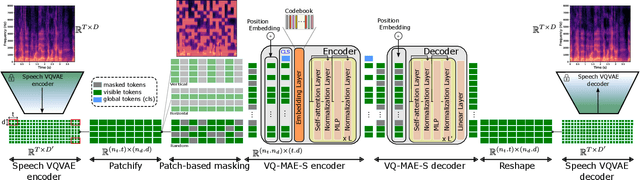
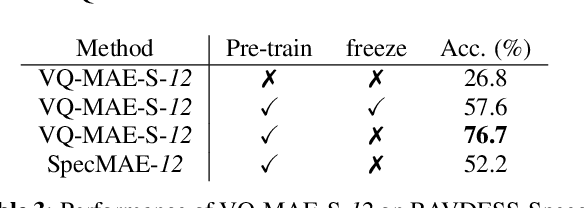

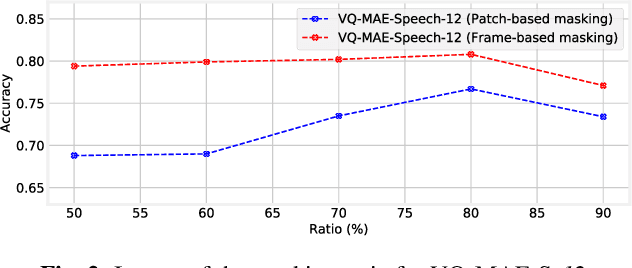
Recent years have seen remarkable progress in speech emotion recognition (SER), thanks to advances in deep learning techniques. However, the limited availability of labeled data remains a significant challenge in the field. Self-supervised learning has recently emerged as a promising solution to address this challenge. In this paper, we propose the vector quantized masked autoencoder for speech (VQ-MAE-S), a self-supervised model that is fine-tuned to recognize emotions from speech signals. The VQ-MAE-S model is based on a masked autoencoder (MAE) that operates in the discrete latent space of a vector-quantized variational autoencoder. Experimental results show that the proposed VQ-MAE-S model, pre-trained on the VoxCeleb2 dataset and fine-tuned on emotional speech data, outperforms an MAE working on the raw spectrogram representation and other state-of-the-art methods in SER.