 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion-DVAE: Unsupervised learning for fast human motion denoising
Jun 09, 2023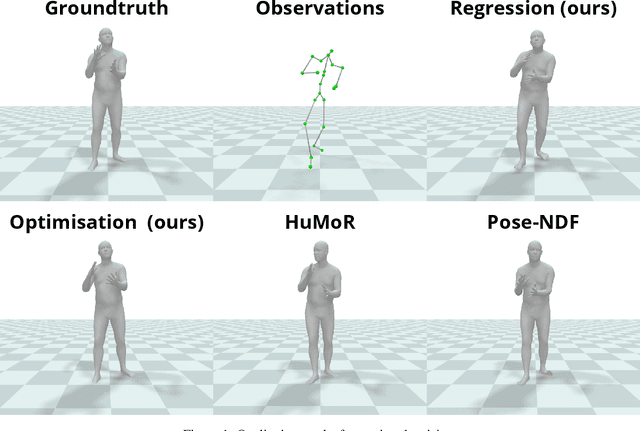



Pose and motion priors are crucial for recovering realistic and accurate human motion from noisy observations. Substantial progress has been made on pose and shape estimation from images, and recent works showed impressive results using priors to refine frame-wise predictions. However, a lot of motion priors only model transitions between consecutive poses and are used in time-consuming optimization procedures, which is problematic for many applications requiring real-time motion capture. We introduce Motion-DVAE, a motion prior to capture the short-term dependencies of human motion. As part of the dynamical variational autoencoder (DVAE) models family, Motion-DVAE combines the generative capability of VAE models and the temporal modeling of recurrent architectures. Together with Motion-DVAE, we introduce an unsupervised learned denoising method unifying regression- and optimization-based approaches in a single framework for real-time 3D human pose estimation. Experiments show that the proposed approach reaches competitive performance with state-of-the-art methods while being much faster.
A Multimodal Dynamical Variational Autoencoder for Audiovisual Speech Representation Learning
May 05, 2023In this paper, we present a multimodal \textit{and} dynamical VAE (MDVAE) applied to unsupervised audio-visual speech representation learning. The latent space is structured to dissociate the latent dynamical factors that are shared between the modalities from those that are specific to each modality. A static latent variable is also introduced to encode the information that is constant over time within an audiovisual speech sequence. The model is trained in an unsupervised manner on an audiovisual emotional speech dataset, in two stages. In the first stage, a vector quantized VAE (VQ-VAE) is learned independently for each modality, without temporal modeling. The second stage consists in learning the MDVAE model on the intermediate representation of the VQ-VAEs before quantization. The disentanglement between static versus dynamical and modality-specific versus modality-common information occurs during this second training stage. Extensive experiments are conducted to investigate how audiovisual speech latent factors are encoded in the latent space of MDVAE. These experiments include manipulating audiovisual speech, audiovisual facial image denoising, and audiovisual speech emotion recognition. The results show that MDVAE effectively combines the audio and visual information in its latent space. They also show that the learned static representation of audiovisual speech can be used for emotion recognition with few labeled data, and with better accuracy compared with unimodal baselines and a state-of-the-art supervised model based on an audiovisual transformer architecture.
A vector quantized masked autoencoder for audiovisual speech emotion recognition
May 05, 2023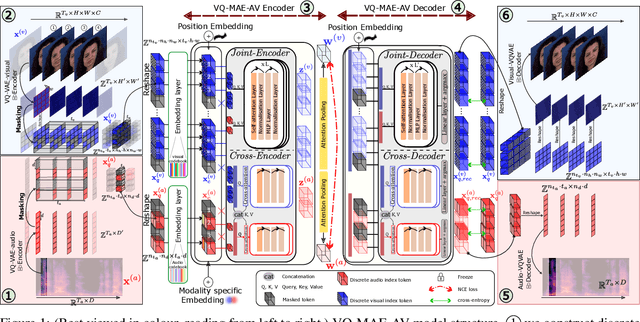
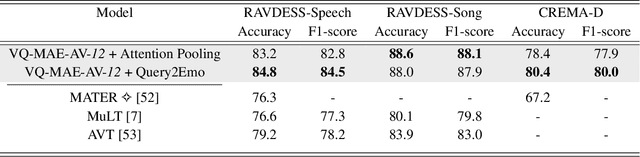
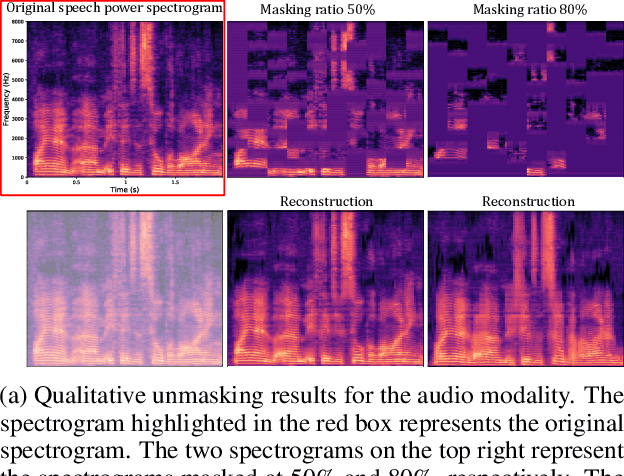
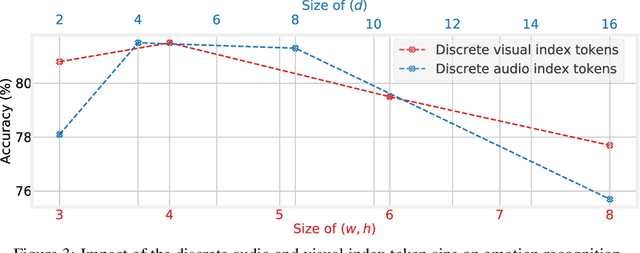
While fully-supervised models have been shown to be effective for audiovisual speech emotion recognition (SER), the limited availability of labeled data remains a major challenge in the field. To address this issue, self-supervised learning approaches, such as masked autoencoders (MAEs), have gained popularity as potential solutions. In this paper, we propose the VQ-MAE-AV model, a vector quantized MAE specifically designed for audiovisual speech self-supervised representation learning. Unlike existing multimodal MAEs that rely on the processing of the raw audiovisual speech data, the proposed method employs a self-supervised paradigm based on discrete audio and visual speech representations learned by two pre-trained vector quantized variational autoencoders. Experimental results show that the proposed approach, which is pre-trained on the VoxCeleb2 database and fine-tuned on standard emotional audiovisual speech datasets, outperforms the state-of-the-art audiovisual SER methods.
A vector quantized masked autoencoder for speech emotion recognition
Apr 21, 2023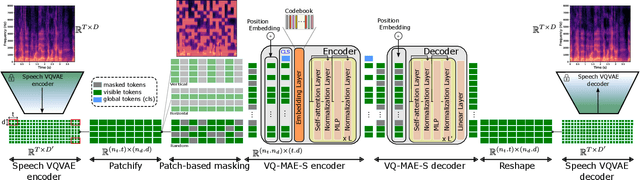
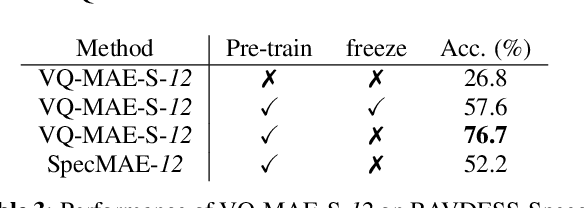

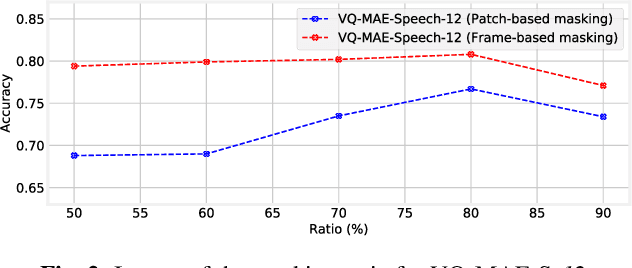
Recent years have seen remarkable progress in speech emotion recognition (SER), thanks to advances in deep learning techniques. However, the limited availability of labeled data remains a significant challenge in the field. Self-supervised learning has recently emerged as a promising solution to address this challenge. In this paper, we propose the vector quantized masked autoencoder for speech (VQ-MAE-S), a self-supervised model that is fine-tuned to recognize emotions from speech signals. The VQ-MAE-S model is based on a masked autoencoder (MAE) that operates in the discrete latent space of a vector-quantized variational autoencoder. Experimental results show that the proposed VQ-MAE-S model, pre-trained on the VoxCeleb2 dataset and fine-tuned on emotional speech data, outperforms an MAE working on the raw spectrogram representation and other state-of-the-art methods in SER.
Learning and controlling the source-filter representation of speech with a variational autoencoder
Apr 14, 2022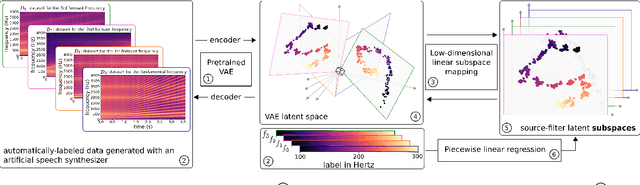
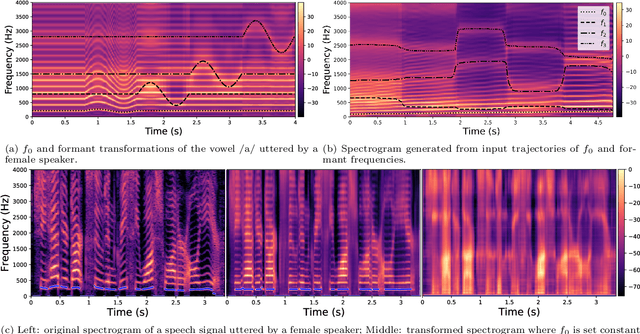
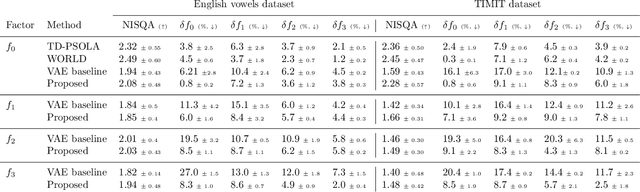
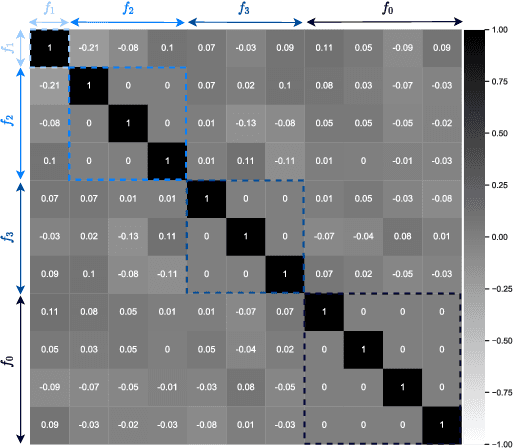
Understanding and controlling latent representations in deep generative models is a challenging yet important problem for analyzing, transforming and generating various types of data. In speech processing, inspiring from the anatomical mechanisms of phonation, the source-filter model considers that speech signals are produced from a few independent and physically meaningful continuous latent factors, among which the fundamental frequency $f_0$ and the formants are of primary importance. In this work, we show that the source-filter model of speech production naturally arises in the latent space of a variational autoencoder (VAE) trained in an unsupervised manner on a dataset of natural speech signals. Using only a few seconds of labeled speech signals generated with an artificial speech synthesizer, we experimentally illustrate that $f_0$ and the formant frequencies are encoded in orthogonal subspaces of the VAE latent space and we develop a weakly-supervised method to accurately and independently control these speech factors of variation within the learned latent subspaces. Without requiring additional information such as text or human-labeled data, this results in a deep generative model of speech spectrograms that is conditioned on $f_0$ and the formant frequencies, and which is applied to the transformation of speech signals.