 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Mesh Modeling for Anny Body
Nov 05, 2025Parametric body models are central to many human-centric tasks, yet existing models often rely on costly 3D scans and learned shape spaces that are proprietary and demographically narrow. We introduce Anny, a simple, fully differentiable, and scan-free human body model grounded in anthropometric knowledge from the MakeHuman community. Anny defines a continuous, interpretable shape space, where phenotype parameters (e.g. gender, age, height, weight) control blendshapes spanning a wide range of human forms -- across ages (from infants to elders), body types, and proportions. Calibrated using WHO population statistics, it provides realistic and demographically grounded human shape variation within a single unified model. Thanks to its openness and semantic control, Anny serves as a versatile foundation for 3D human modeling -- supporting millimeter-accurate scan fitting, controlled synthetic data generation, and Human Mesh Recovery (HMR). We further introduce Anny-One, a collection of 800k photorealistic humans generated with Anny, showing that despite its simplicity, HMR models trained with Anny can match the performance of those trained with scan-based body models, while remaining interpretable and broadly representative. The Anny body model and its code are released under the Apache 2.0 license, making Anny an accessible foundation for human-centric 3D modeling.
MEGA: Masked Generative Autoencoder for Human Mesh Recovery
May 29, 2024Human Mesh Recovery (HMR) from a single RGB image is a highly ambiguous problem, as similar 2D projections can correspond to multiple 3D interpretations. Nevertheless, most HMR methods overlook this ambiguity and make a single prediction without accounting for the associated uncertainty. A few approaches generate a distribution of human meshes, enabling the sampling of multiple predictions; however, none of them is competitive with the latest single-output model when making a single prediction. This work proposes a new approach based on masked generative modeling. By tokenizing the human pose and shape, we formulate the HMR task as generating a sequence of discrete tokens conditioned on an input image. We introduce MEGA, a MaskEd Generative Autoencoder trained to recover human meshes from images and partial human mesh token sequences. Given an image, our flexible generation scheme allows us to predict a single human mesh in deterministic mode or to generate multiple human meshes in stochastic mode. MEGA enables us to propose multiple outputs and to evaluate the uncertainty of the predictions. Experiments on in-the-wild benchmarks show that MEGA achieves state-of-the-art performance in deterministic and stochastic modes, outperforming single-output and multi-output approaches.
VQ-HPS: Human Pose and Shape Estimation in a Vector-Quantized Latent Space
Dec 13, 2023



Human Pose and Shape Estimation (HPSE) from RGB images can be broadly categorized into two main groups: parametric and non-parametric approaches. Parametric techniques leverage a low-dimensional statistical body model for realistic results, whereas recent non-parametric methods achieve higher precision by directly regressing the 3D coordinates of the human body. Despite their strengths, both approaches face limitations: the parameters of statistical body models pose challenges as regression targets, and predicting 3D coordinates introduces computational complexities and issues related to smoothness. In this work, we take a novel approach to address the HPSE problem. We introduce a unique method involving a low-dimensional discrete latent representation of the human mesh, framing HPSE as a classification task. Instead of predicting body model parameters or 3D vertex coordinates, our focus is on forecasting the proposed discrete latent representation, which can be decoded into a registered human mesh. This innovative paradigm offers two key advantages: firstly, predicting a low-dimensional discrete representation confines our predictions to the space of anthropomorphic poses and shapes; secondly, by framing the problem as a classification task, we can harness the discriminative power inherent in neural networks. Our proposed model, VQ-HPS, a transformer-based architecture, forecasts the discrete latent representation of the mesh, trained through minimizing a cross-entropy loss. Our results demonstrate that VQ-HPS outperforms the current state-of-the-art non-parametric approaches while yielding results as realistic as those produced by parametric methods. This highlights the significant potential of the classification approach for HPSE.
Motion-DVAE: Unsupervised learning for fast human motion denoising
Jun 09, 2023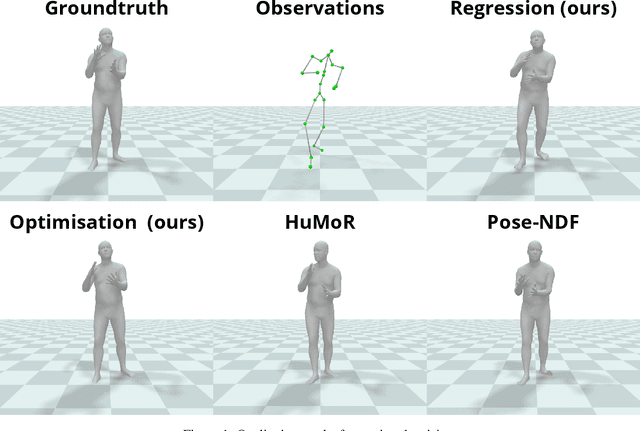



Pose and motion priors are crucial for recovering realistic and accurate human motion from noisy observations. Substantial progress has been made on pose and shape estimation from images, and recent works showed impressive results using priors to refine frame-wise predictions. However, a lot of motion priors only model transitions between consecutive poses and are used in time-consuming optimization procedures, which is problematic for many applications requiring real-time motion capture. We introduce Motion-DVAE, a motion prior to capture the short-term dependencies of human motion. As part of the dynamical variational autoencoder (DVAE) models family, Motion-DVAE combines the generative capability of VAE models and the temporal modeling of recurrent architectures. Together with Motion-DVAE, we introduce an unsupervised learned denoising method unifying regression- and optimization-based approaches in a single framework for real-time 3D human pose estimation. Experiments show that the proposed approach reaches competitive performance with state-of-the-art methods while being much faster.