 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Gender Disparities in Automatic Speech Recognition Technology
Feb 25, 2025
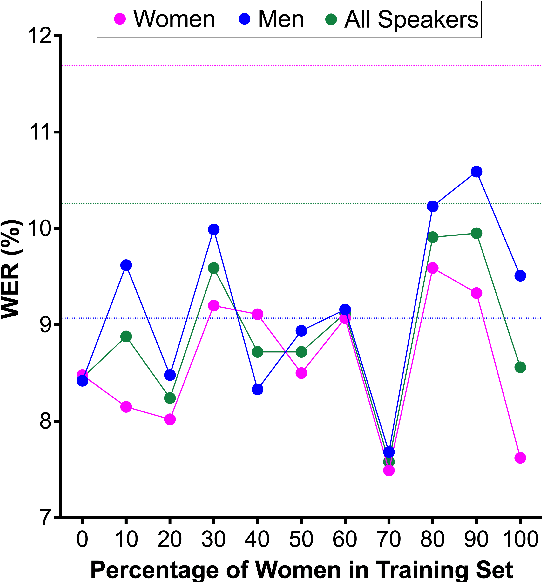
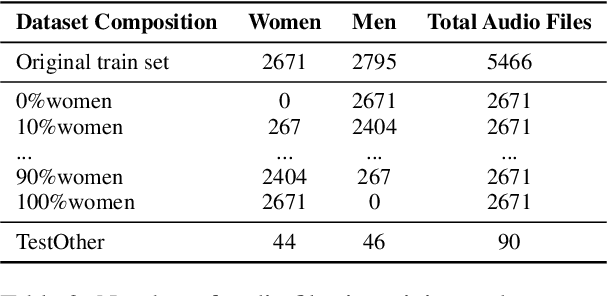
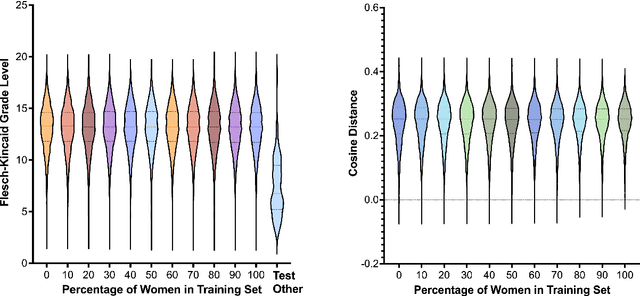
This study investigates factors influencing Automatic Speech Recognition (ASR) systems' fairness and performance across genders, beyond the conventional examination of demographics. Using the LibriSpeech dataset and the Whisper small model, we analyze how performance varies across different gender representations in training data. Our findings suggest a complex interplay between the gender ratio in training data and ASR performance. Optimal fairness occurs at specific gender distributions rather than a simple 50-50 split. Furthermore, our findings suggest that factors like pitch variability can significantly affect ASR accuracy. This research contributes to a deeper understanding of biases in ASR systems, highlighting the importance of carefully curated training data in mitigating gender bias.
Objective and subjective evaluation of speech enhancement methods in the UDASE task of the 7th CHiME challenge
Feb 02, 2024



Supervised models for speech enhancement are trained using artificially generated mixtures of clean speech and noise signals. However, the synthetic training conditions may not accurately reflect real-world conditions encountered during testing. This discrepancy can result in poor performance when the test domain significantly differs from the synthetic training domain. To tackle this issue, the UDASE task of the 7th CHiME challenge aimed to leverage real-world noisy speech recordings from the test domain for unsupervised domain adaptation of speech enhancement models. Specifically, this test domain corresponds to the CHiME-5 dataset, characterized by real multi-speaker and conversational speech recordings made in noisy and reverberant domestic environments, for which ground-truth clean speech signals are not available. In this paper, we present the objective and subjective evaluations of the systems that were submitted to the CHiME-7 UDASE task, and we provide an analysis of the results. This analysis reveals a limited correlation between subjective ratings and several supervised nonintrusive performance metrics recently proposed for speech enhancement. Conversely, the results suggest that more traditional intrusive objective metrics can be used for in-domain performance evaluation using the reverberant LibriCHiME-5 dataset developed for the challenge. The subjective evaluation indicates that all systems successfully reduced the background noise, but always at the expense of increased distortion. Out of the four speech enhancement methods evaluated subjectively, only one demonstrated an improvement in overall quality compared to the unprocessed noisy speech, highlighting the difficulty of the task. The tools and audio material created for the CHiME-7 UDASE task are shared with the community.