 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlzheimer's Dementia Detection Using Perplexity from Paired Large Language Models
Jun 11, 2025Alzheimer's dementia (AD) is a neurodegenerative disorder with cognitive decline that commonly impacts language ability. This work extends the paired perplexity approach to detecting AD by using a recent large language model (LLM), the instruction-following version of Mistral-7B. We improve accuracy by an average of 3.33% over the best current paired perplexity method and by 6.35% over the top-ranked method from the ADReSS 2020 challenge benchmark. Our further analysis demonstrates that the proposed approach can effectively detect AD with a clear and interpretable decision boundary in contrast to other methods that suffer from opaque decision-making processes. Finally, by prompting the fine-tuned LLMs and comparing the model-generated responses to human responses, we illustrate that the LLMs have learned the special language patterns of AD speakers, which opens up possibilities for novel methods of model interpretation and data augmentation.
Exploring Gender Disparities in Automatic Speech Recognition Technology
Feb 25, 2025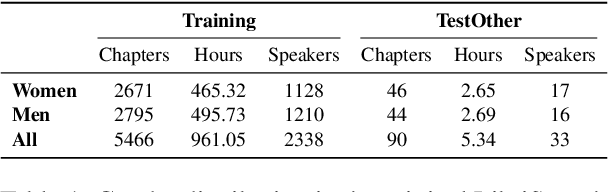
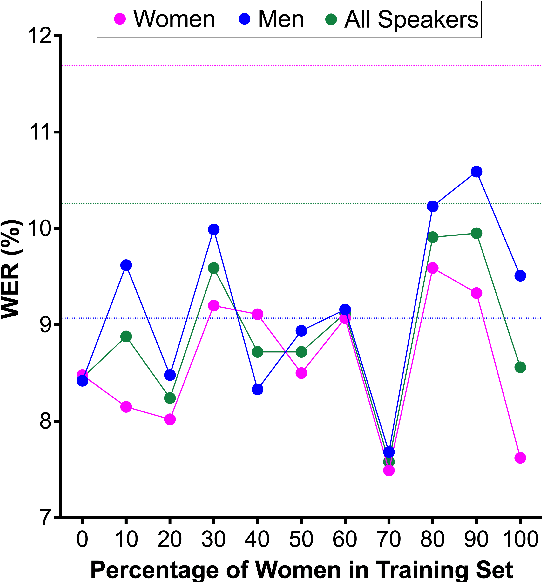
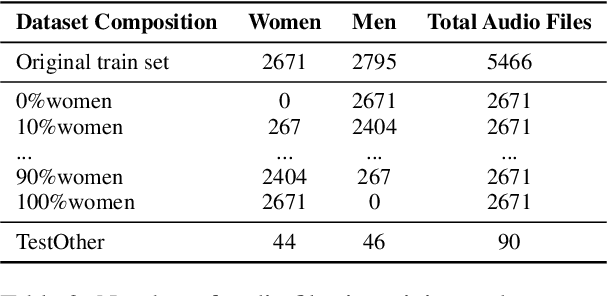
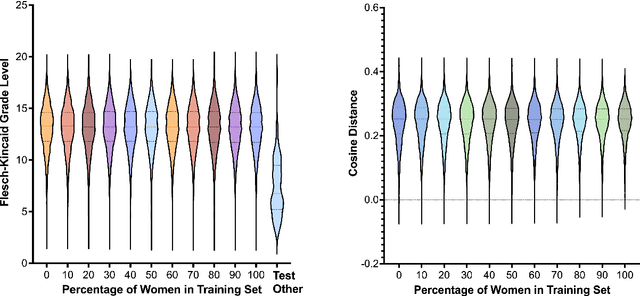
This study investigates factors influencing Automatic Speech Recognition (ASR) systems' fairness and performance across genders, beyond the conventional examination of demographics. Using the LibriSpeech dataset and the Whisper small model, we analyze how performance varies across different gender representations in training data. Our findings suggest a complex interplay between the gender ratio in training data and ASR performance. Optimal fairness occurs at specific gender distributions rather than a simple 50-50 split. Furthermore, our findings suggest that factors like pitch variability can significantly affect ASR accuracy. This research contributes to a deeper understanding of biases in ASR systems, highlighting the importance of carefully curated training data in mitigating gender bias.
CognoSpeak: an automatic, remote assessment of early cognitive decline in real-world conversational speech
Jan 10, 2025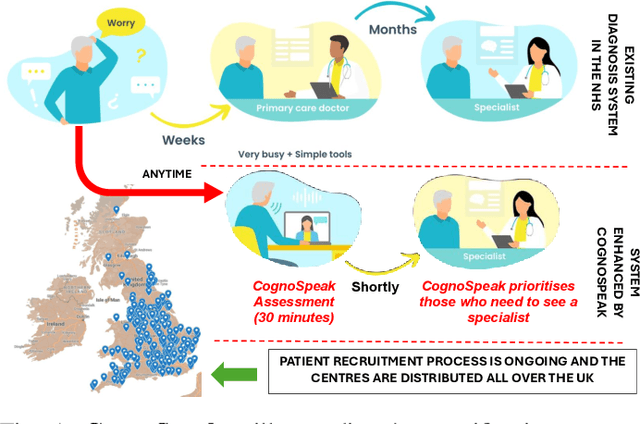
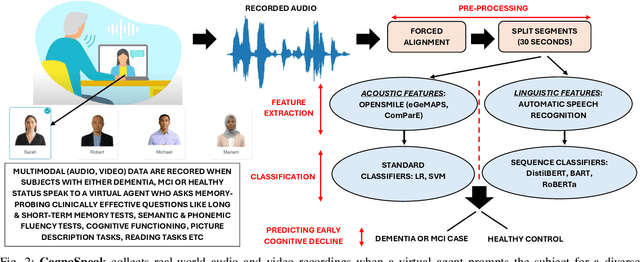
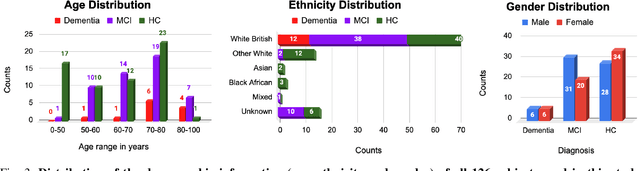
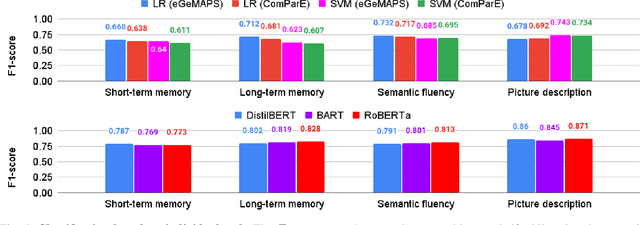
The early signs of cognitive decline are often noticeable in conversational speech, and identifying those signs is crucial in dealing with later and more serious stages of neurodegenerative diseases. Clinical detection is costly and time-consuming and although there has been recent progress in the automatic detection of speech-based cues, those systems are trained on relatively small databases, lacking detailed metadata and demographic information. This paper presents CognoSpeak and its associated data collection efforts. CognoSpeak asks memory-probing long and short-term questions and administers standard cognitive tasks such as verbal and semantic fluency and picture description using a virtual agent on a mobile or web platform. In addition, it collects multimodal data such as audio and video along with a rich set of metadata from primary and secondary care, memory clinics and remote settings like people's homes. Here, we present results from 126 subjects whose audio was manually transcribed. Several classic classifiers, as well as large language model-based classifiers, have been investigated and evaluated across the different types of prompts. We demonstrate a high level of performance; in particular, we achieved an F1-score of 0.873 using a DistilBERT model to discriminate people with cognitive impairment (dementia and people with mild cognitive impairment (MCI)) from healthy volunteers using the memory responses, fluency tasks and cookie theft picture description. CognoSpeak is an automatic, remote, low-cost, repeatable, non-invasive and less stressful alternative to existing clinical cognitive assessments.
Automatic Detection of Expressed Emotion from Five-Minute Speech Samples: Challenges and Opportunities
Mar 30, 2022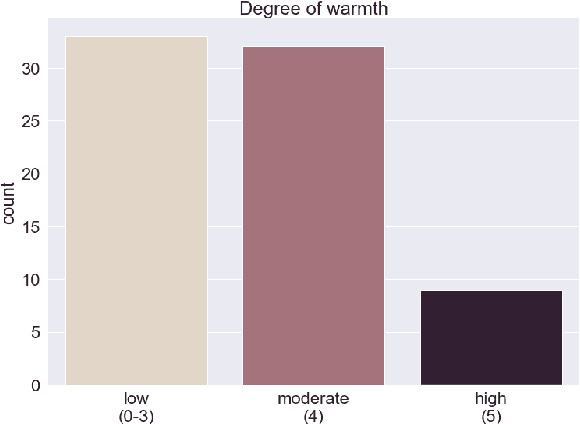
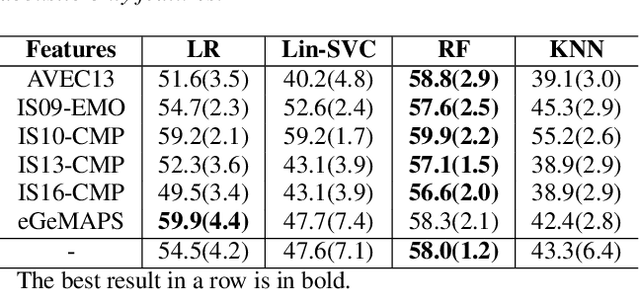
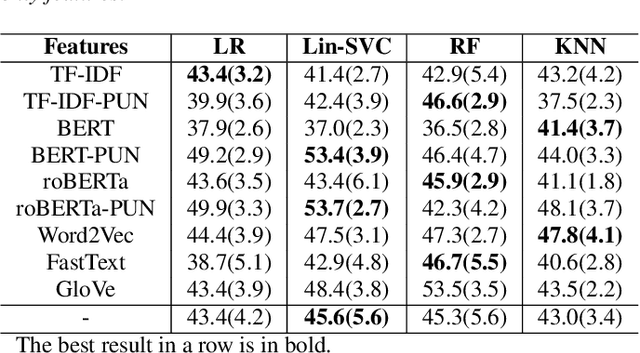
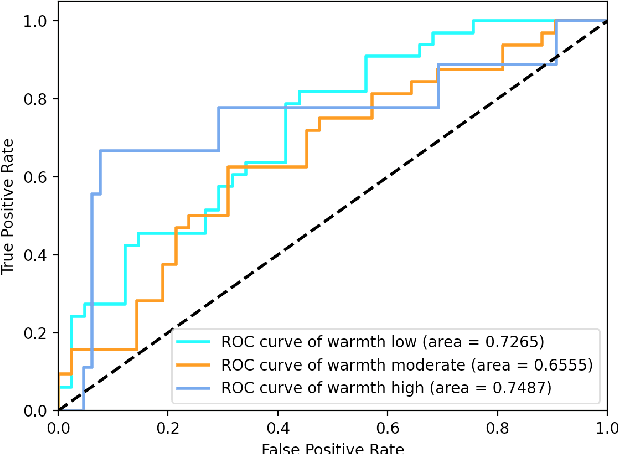
We present a novel feasibility study on the automatic recognition of Expressed Emotion (EE), a family environment concept based on caregivers speaking freely about their relative/family member. We describe an automated approach for determining the \textit{degree of warmth}, a key component of EE, from acoustic and text features acquired from a sample of 37 recorded interviews. These recordings, collected over 20 years ago, are derived from a nationally representative birth cohort of 2,232 British twin children and were manually coded for EE. We outline the core steps of extracting usable information from recordings with highly variable audio quality and assess the efficacy of four machine learning approaches trained with different combinations of acoustic and text features. Despite the challenges of working with this legacy data, we demonstrated that the degree of warmth can be predicted with an $F_{1}$-score of \textbf{61.5\%}. In this paper, we summarise our learning and provide recommendations for future work using real-world speech samples.
Data augmentation using generative networks to identify dementia
Apr 13, 2020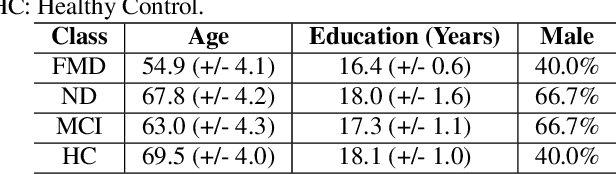
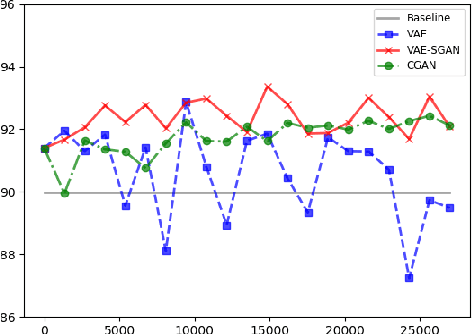

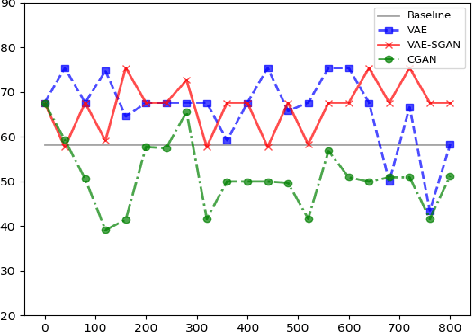
Data limitation is one of the most common issues in training machine learning classifiers for medical applications. Due to ethical concerns and data privacy, the number of people that can be recruited to such experiments is generally smaller than the number of participants contributing to non-healthcare datasets. Recent research showed that generative models can be used as an effective approach for data augmentation, which can ultimately help to train more robust classifiers sparse data domains. A number of studies proved that this data augmentation technique works for image and audio data sets. In this paper, we investigate the application of a similar approach to different types of speech and audio-based features extracted from interactions recorded with our automatic dementia detection system. Using two generative models we show how the generated synthesized samples can improve the performance of a DNN based classifier. The variational autoencoder increased the F-score of a four-way classifier distinguishing the typical patient groups seen in memory clinics from 58% to around 74%, a 16% improvement
Detecting Alzheimer's Disease by estimating attention and elicitation path through the alignment of spoken picture descriptions with the picture prompt
Oct 01, 2019



Cognitive decline is a sign of Alzheimer's disease (AD), and there is evidence that tracking a person's eye movement, using eye tracking devices, can be used for the automatic identification of early signs of cognitive decline. However, such devices are expensive and may not be easy-to-use for people with cognitive problems. In this paper, we present a new way of capturing similar visual features, by using the speech of people describing the Cookie Theft picture - a common cognitive testing task - to identify regions in the picture prompt that will have caught the speaker's attention and elicited their speech. After aligning the automatically recognised words with different regions of the picture prompt, we extract information inspired by eye tracking metrics such as coordinates of the area of interests (AOI)s, time spent in AOI, time to reach the AOI, and the number of AOI visits. Using the DementiaBank dataset we train a binary classifier (AD vs. healthy control) using 10-fold cross-validation and achieve an 80% F1-score using the timing information from the forced alignments of the automatic speech recogniser (ASR); this achieved around 72% using the timing information from the ASR outputs.