 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwin-BERT: A Feature Fusion System designed for Speech-based Alzheimer's Dementia Detection
Oct 09, 2024



Speech is usually used for constructing an automatic Alzheimer's dementia (AD) detection system, as the acoustic and linguistic abilities show a decline in people living with AD at the early stages. However, speech includes not only AD-related local and global information but also other information unrelated to cognitive status, such as age and gender. In this paper, we propose a speech-based system named Swin-BERT for automatic dementia detection. For the acoustic part, the shifted windows multi-head attention that proposed to extract local and global information from images, is used for designing our acoustic-based system. To decouple the effect of age and gender on acoustic feature extraction, they are used as an extra input of the designed acoustic system. For the linguistic part, the rhythm-related information, which varies significantly between people living with and without AD, is removed while transcribing the audio recordings into transcripts. To compensate for the removed rhythm-related information, the character-level transcripts are proposed to be used as the extra input of a word-level BERT-style system. Finally, the Swin-BERT combines the acoustic features learned from our proposed acoustic-based system with our linguistic-based system. The experiments are based on the two datasets provided by the international dementia detection challenges: the ADReSS and ADReSSo. The results show that both the proposed acoustic and linguistic systems can be better or comparable with previous research on the two datasets. Superior results are achieved by the proposed Swin-BERT system on the ADReSS and ADReSSo datasets, which are 85.58\% F-score and 87.32\% F-score respectively.
Data augmentation using generative networks to identify dementia
Apr 13, 2020
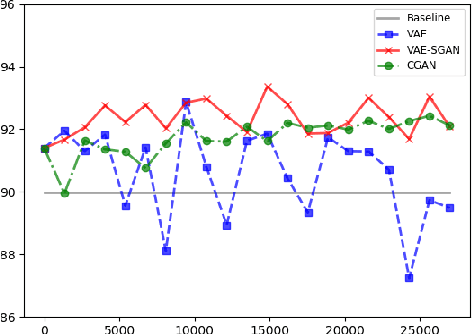

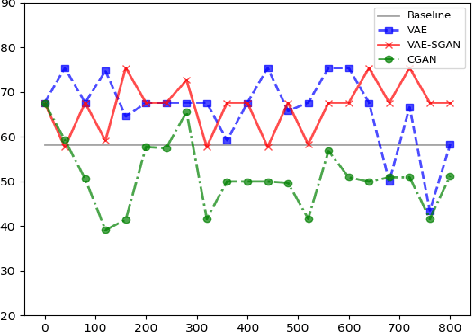
Data limitation is one of the most common issues in training machine learning classifiers for medical applications. Due to ethical concerns and data privacy, the number of people that can be recruited to such experiments is generally smaller than the number of participants contributing to non-healthcare datasets. Recent research showed that generative models can be used as an effective approach for data augmentation, which can ultimately help to train more robust classifiers sparse data domains. A number of studies proved that this data augmentation technique works for image and audio data sets. In this paper, we investigate the application of a similar approach to different types of speech and audio-based features extracted from interactions recorded with our automatic dementia detection system. Using two generative models we show how the generated synthesized samples can improve the performance of a DNN based classifier. The variational autoencoder increased the F-score of a four-way classifier distinguishing the typical patient groups seen in memory clinics from 58% to around 74%, a 16% improvement
Detecting Alzheimer's Disease by estimating attention and elicitation path through the alignment of spoken picture descriptions with the picture prompt
Oct 01, 2019



Cognitive decline is a sign of Alzheimer's disease (AD), and there is evidence that tracking a person's eye movement, using eye tracking devices, can be used for the automatic identification of early signs of cognitive decline. However, such devices are expensive and may not be easy-to-use for people with cognitive problems. In this paper, we present a new way of capturing similar visual features, by using the speech of people describing the Cookie Theft picture - a common cognitive testing task - to identify regions in the picture prompt that will have caught the speaker's attention and elicited their speech. After aligning the automatically recognised words with different regions of the picture prompt, we extract information inspired by eye tracking metrics such as coordinates of the area of interests (AOI)s, time spent in AOI, time to reach the AOI, and the number of AOI visits. Using the DementiaBank dataset we train a binary classifier (AD vs. healthy control) using 10-fold cross-validation and achieve an 80% F1-score using the timing information from the forced alignments of the automatic speech recogniser (ASR); this achieved around 72% using the timing information from the ASR outputs.