 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEP: Warm-Started Visuomotor Policies with Spatiotemporal Consistency Prediction
Feb 09, 2026Diffusion policies have recently emerged as a powerful paradigm for visuomotor control in robotic manipulation due to their ability to model the distribution of action sequences and capture multimodality. However, iterative denoising leads to substantial inference latency, limiting control frequency in real-time closed-loop systems. Existing acceleration methods either reduce sampling steps, bypass diffusion through direct prediction, or reuse past actions, but often struggle to jointly preserve action quality and achieve consistently low latency. In this work, we propose STEP, a lightweight spatiotemporal consistency prediction mechanism to construct high-quality warm-start actions that are both distributionally close to the target action and temporally consistent, without compromising the generative capability of the original diffusion policy. Then, we propose a velocity-aware perturbation injection mechanism that adaptively modulates actuation excitation based on temporal action variation to prevent execution stall especially for real-world tasks. We further provide a theoretical analysis showing that the proposed prediction induces a locally contractive mapping, ensuring convergence of action errors during diffusion refinement. We conduct extensive evaluations on nine simulated benchmarks and two real-world tasks. Notably, STEP with 2 steps can achieve an average 21.6% and 27.5% higher success rate than BRIDGER and DDIM on the RoboMimic benchmark and real-world tasks, respectively. These results demonstrate that STEP consistently advances the Pareto frontier of inference latency and success rate over existing methods.
Peptide2Mol: A Diffusion Model for Generating Small Molecules as Peptide Mimics for Targeted Protein Binding
Nov 07, 2025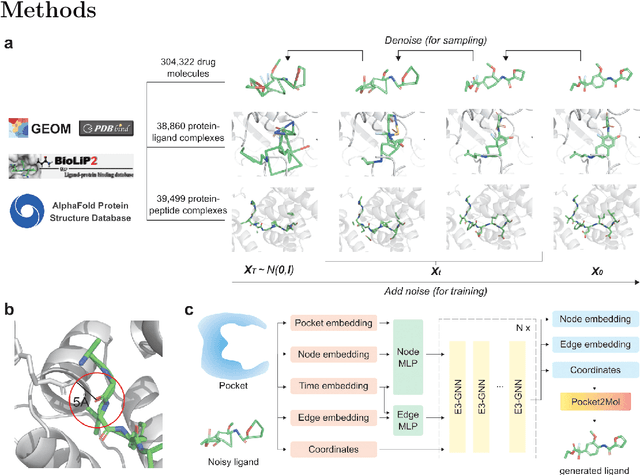
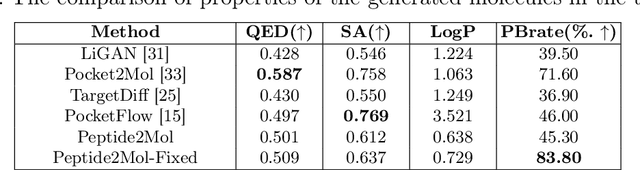
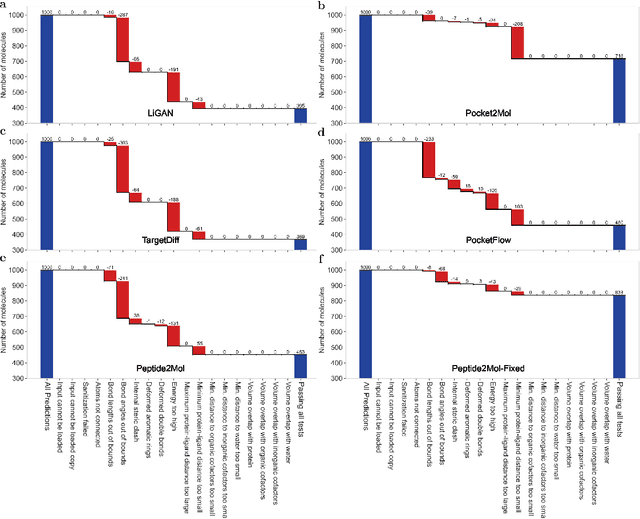
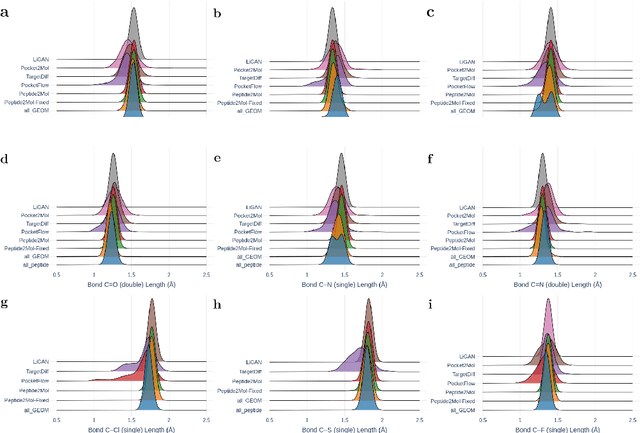
Structure-based drug design has seen significant advancements with the integration of artificial intelligence (AI), particularly in the generation of hit and lead compounds. However, most AI-driven approaches neglect the importance of endogenous protein interactions with peptides, which may result in suboptimal molecule designs. In this work, we present Peptide2Mol, an E(3)-equivariant graph neural network diffusion model that generates small molecules by referencing both the original peptide binders and their surrounding protein pocket environments. Trained on large datasets and leveraging sophisticated modeling techniques, Peptide2Mol not only achieves state-of-the-art performance in non-autoregressive generative tasks, but also produces molecules with similarity to the original peptide binder. Additionally, the model allows for molecule optimization and peptidomimetic design through a partial diffusion process. Our results highlight Peptide2Mol as an effective deep generative model for generating and optimizing bioactive small molecules from protein binding pockets.
CommonVoice-SpeechRE and RPG-MoGe: Advancing Speech Relation Extraction with a New Dataset and Multi-Order Generative Framework
Sep 10, 2025Speech Relation Extraction (SpeechRE) aims to extract relation triplets directly from speech. However, existing benchmark datasets rely heavily on synthetic data, lacking sufficient quantity and diversity of real human speech. Moreover, existing models also suffer from rigid single-order generation templates and weak semantic alignment, substantially limiting their performance. To address these challenges, we introduce CommonVoice-SpeechRE, a large-scale dataset comprising nearly 20,000 real-human speech samples from diverse speakers, establishing a new benchmark for SpeechRE research. Furthermore, we propose the Relation Prompt-Guided Multi-Order Generative Ensemble (RPG-MoGe), a novel framework that features: (1) a multi-order triplet generation ensemble strategy, leveraging data diversity through diverse element orders during both training and inference, and (2) CNN-based latent relation prediction heads that generate explicit relation prompts to guide cross-modal alignment and accurate triplet generation. Experiments show our approach outperforms state-of-the-art methods, providing both a benchmark dataset and an effective solution for real-world SpeechRE. The source code and dataset are publicly available at https://github.com/NingJinzhong/SpeechRE_RPG_MoGe.
ROMA: a Read-Only-Memory-based Accelerator for QLoRA-based On-Device LLM
Mar 17, 2025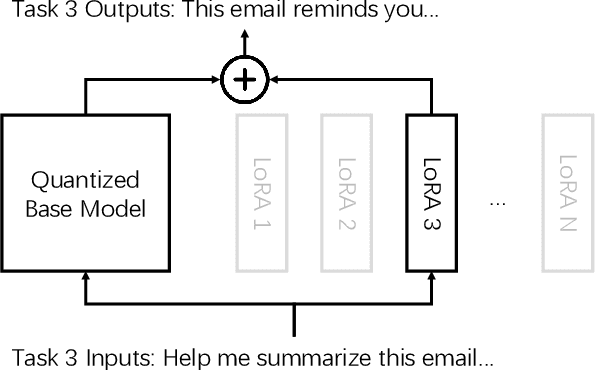
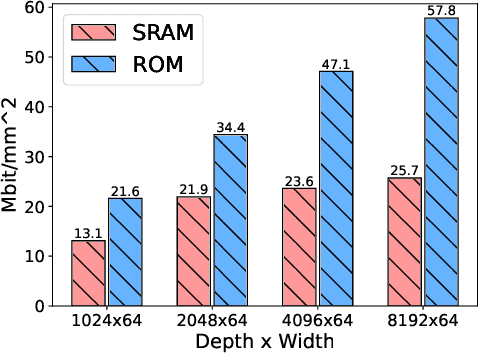
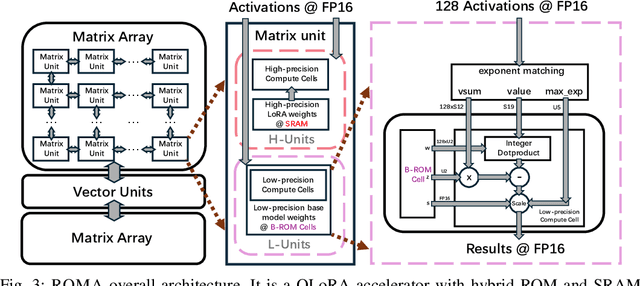
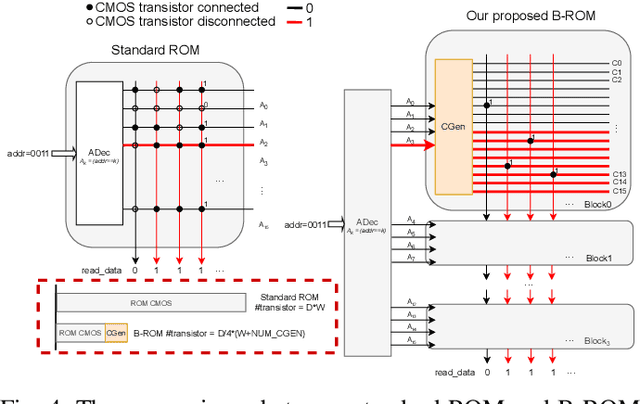
As large language models (LLMs) demonstrate powerful capabilities, deploying them on edge devices has become increasingly crucial, offering advantages in privacy and real-time interaction. QLoRA has emerged as the standard approach for on-device LLMs, leveraging quantized models to reduce memory and computational costs while utilizing LoRA for task-specific adaptability. In this work, we propose ROMA, a QLoRA accelerator with a hybrid storage architecture that uses ROM for quantized base models and SRAM for LoRA weights and KV cache. Our insight is that the quantized base model is stable and converged, making it well-suited for ROM storage. Meanwhile, LoRA modules offer the flexibility to adapt to new data without requiring updates to the base model. To further reduce the area cost of ROM, we introduce a novel B-ROM design and integrate it with the compute unit to form a fused cell for efficient use of chip resources. ROMA can effectively store both a 4-bit 3B and a 2-bit 8B LLaMA model entirely on-chip, achieving a notable generation speed exceeding 20,000 tokens/s without requiring external memory.
RFUAV: A Benchmark Dataset for Unmanned Aerial Vehicle Detection and Identification
Mar 12, 2025



In this paper, we propose RFUAV as a new benchmark dataset for radio-frequency based (RF-based) unmanned aerial vehicle (UAV) identification and address the following challenges: Firstly, many existing datasets feature a restricted variety of drone types and insufficient volumes of raw data, which fail to meet the demands of practical applications. Secondly, existing datasets often lack raw data covering a broad range of signal-to-noise ratios (SNR), or do not provide tools for transforming raw data to different SNR levels. This limitation undermines the validity of model training and evaluation. Lastly, many existing datasets do not offer open-access evaluation tools, leading to a lack of unified evaluation standards in current research within this field. RFUAV comprises approximately 1.3 TB of raw frequency data collected from 37 distinct UAVs using the Universal Software Radio Peripheral (USRP) device in real-world environments. Through in-depth analysis of the RF data in RFUAV, we define a drone feature sequence called RF drone fingerprint, which aids in distinguishing drone signals. In addition to the dataset, RFUAV provides a baseline preprocessing method and model evaluation tools. Rigorous experiments demonstrate that these preprocessing methods achieve state-of-the-art (SOTA) performance using the provided evaluation tools. The RFUAV dataset and baseline implementation are publicly available at https://github.com/kitoweeknd/RFUAV/.
Cognitive-Aligned Document Selection for Retrieval-augmented Generation
Feb 17, 2025Large language models (LLMs) inherently display hallucinations since the precision of generated texts cannot be guaranteed purely by the parametric knowledge they include. Although retrieval-augmented generation (RAG) systems enhance the accuracy and reliability of generative models by incorporating external documents, these retrieved documents often fail to adequately support the model's responses in practical applications. To address this issue, we propose GGatrieval (Fine-\textbf{G}rained \textbf{G}rounded \textbf{A}lignment Re\textbf{trieval} for verifiable generation), which leverages an LLM to dynamically update queries and filter high-quality, reliable retrieval documents. Specifically, we parse the user query into its syntactic components and perform fine-grained grounded alignment with the retrieved documents. For query components that cannot be individually aligned, we propose a dynamic semantic compensation mechanism that iteratively refines and rewrites the query while continuously updating the retrieval results. This iterative process continues until the retrieved documents sufficiently support the query's response. Our approach introduces a novel criterion for filtering retrieved documents, closely emulating human strategies for acquiring targeted information. This ensures that the retrieved content effectively supports and verifies the generated outputs. On the ALCE benchmark, our method significantly surpasses a wide range of baselines, achieving state-of-the-art performance.
STAHGNet: Modeling Hybrid-grained Heterogenous Dependency Efficiently for Traffic Prediction
Dec 23, 2024



Traffic flow prediction plays a critical role in the intelligent transportation system, and it is also a challenging task because of the underlying complex Spatio-temporal patterns and heterogeneities evolving across time. However, most present works mostly concentrate on solely capturing Spatial-temporal dependency or extracting implicit similarity graphs, but the hybrid-granularity evolution is ignored in their modeling process. In this paper, we proposed a novel data-driven end-to-end framework, named Spatio-Temporal Aware Hybrid Graph Network (STAHGNet), to couple the hybrid-grained heterogeneous correlations in series simultaneously through an elaborately Hybrid Graph Attention Module (HGAT) and Coarse-granularity Temporal Graph (CTG) generator. Furthermore, an automotive feature engineering with domain knowledge and a random neighbor sampling strategy is utilized to improve efficiency and reduce computational complexity. The MAE, RMSE, and MAPE are used for evaluation metrics. Tested on four real-life datasets, our proposal outperforms eight classical baselines and four state-of-the-art (SOTA) methods (e.g., MAE 14.82 on PeMSD3; MAE 18.92 on PeMSD4). Besides, extensive experiments and visualizations verify the effectiveness of each component in STAHGNet. In terms of computational cost, STAHGNet saves at least four times the space compared to the previous SOTA models. The proposed model will be beneficial for more efficient TFP as well as intelligent transport system construction.
UMSPU: Universal Multi-Size Phase Unwrapping via Mutual Self-Distillation and Adaptive Boosting Ensemble Segmenters
Dec 07, 2024



Spatial phase unwrapping is a key technique for extracting phase information to obtain 3D morphology and other features. Modern industrial measurement scenarios demand high precision, large image sizes, and high speed. However, conventional methods struggle with noise resistance and processing speed. Current deep learning methods are limited by the receptive field size and sparse semantic information, making them ineffective for large size images. To address this issue, we propose a mutual self-distillation (MSD) mechanism and adaptive boosting ensemble segmenters to construct a universal multi-size phase unwrapping network (UMSPU). MSD performs hierarchical attention refinement and achieves cross-layer collaborative learning through bidirectional distillation, ensuring fine-grained semantic representation across image sizes. The adaptive boosting ensemble segmenters combine weak segmenters with different receptive fields into a strong one, ensuring stable segmentation across spatial frequencies. Experimental results show that UMSPU overcomes image size limitations, achieving high precision across image sizes ranging from 256*256 to 2048*2048 (an 8 times increase). It also outperforms existing methods in speed, robustness, and generalization. Its practicality is further validated in structured light imaging and InSAR. We believe that UMSPU offers a universal solution for phase unwrapping, with broad potential for industrial applications.
Automating Energy-Efficient GPU Kernel Generation: A Fast Search-Based Compilation Approach
Nov 28, 2024



Deep Neural Networks (DNNs) have revolutionized various fields, but their deployment on GPUs often leads to significant energy consumption. Unlike existing methods for reducing GPU energy consumption, which are either hardware-inflexible or limited by workload constraints, this paper addresses the problem at the GPU kernel level. We propose a novel search-based compilation method to generate energy-efficient GPU kernels by incorporating energy efficiency into the search process. To accelerate the energy evaluation process, we develop an accurate energy cost model based on high-level kernel features. Furthermore, we introduce a dynamic updating strategy for the energy cost model, reducing the need for on-device energy measurements and accelerating the search process. Our evaluation demonstrates that the proposed approach can generate GPU kernels with up to 21.69% reduced energy consumption while maintaining low latency.
Reprogramming Pretrained Target-Specific Diffusion Models for Dual-Target Drug Design
Oct 28, 2024


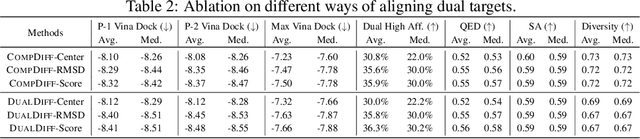
Dual-target therapeutic strategies have become a compelling approach and attracted significant attention due to various benefits, such as their potential in overcoming drug resistance in cancer therapy. Considering the tremendous success that deep generative models have achieved in structure-based drug design in recent years, we formulate dual-target drug design as a generative task and curate a novel dataset of potential target pairs based on synergistic drug combinations. We propose to design dual-target drugs with diffusion models that are trained on single-target protein-ligand complex pairs. Specifically, we align two pockets in 3D space with protein-ligand binding priors and build two complex graphs with shared ligand nodes for SE(3)-equivariant composed message passing, based on which we derive a composed drift in both 3D and categorical probability space in the generative process. Our algorithm can well transfer the knowledge gained in single-target pretraining to dual-target scenarios in a zero-shot manner. We also repurpose linker design methods as strong baselines for this task. Extensive experiments demonstrate the effectiveness of our method compared with various baselines.