 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstantSticker: Realistic Decal Blending via Disentangled Object Reconstruction
Apr 09, 2025



We present InstantSticker, a disentangled reconstruction pipeline based on Image-Based Lighting (IBL), which focuses on highly realistic decal blending, simulates stickers attached to the reconstructed surface, and allows for instant editing and real-time rendering. To achieve stereoscopic impression of the decal, we introduce shadow factor into IBL, which can be adaptively optimized during training. This allows the shadow brightness of surfaces to be accurately decomposed rather than baked into the diffuse color, ensuring that the edited texture exhibits authentic shading. To address the issues of warping and blurriness in previous methods, we apply As-Rigid-As-Possible (ARAP) parameterization to pre-unfold a specified area of the mesh and use the local UV mapping combined with a neural texture map to enhance the ability to express high-frequency details in that area. For instant editing, we utilize the Disney BRDF model, explicitly defining material colors with 3-channel diffuse albedo. This enables instant replacement of albedo RGB values during the editing process, avoiding the prolonged optimization required in previous approaches. In our experiment, we introduce the Ratio Variance Warping (RVW) metric to evaluate the local geometric warping of the decal area. Extensive experimental results demonstrate that our method surpasses previous decal blending methods in terms of editing quality, editing speed and rendering speed, achieving the state-of-the-art.
PLM4NDV: Minimizing Data Access for Number of Distinct Values Estimation with Pre-trained Language Models
Apr 01, 2025



Number of Distinct Values (NDV) estimation of a multiset/column is a basis for many data management tasks, especially within databases. Despite decades of research, most existing methods require either a significant amount of samples through uniform random sampling or access to the entire column to produce estimates, leading to substantial data access costs and potentially ineffective estimations in scenarios with limited data access. In this paper, we propose leveraging semantic information, i.e., schema, to address these challenges. The schema contains rich semantic information that can benefit the NDV estimation. To this end, we propose PLM4NDV, a learned method incorporating Pre-trained Language Models (PLMs) to extract semantic schema information for NDV estimation. Specifically, PLM4NDV leverages the semantics of the target column and the corresponding table to gain a comprehensive understanding of the column's meaning. By using the semantics, PLM4NDV reduces data access costs, provides accurate NDV estimation, and can even operate effectively without any data access. Extensive experiments on a large-scale real-world dataset demonstrate the superiority of PLM4NDV over baseline methods. Our code is available at https://github.com/bytedance/plm4ndv.
RFUAV: A Benchmark Dataset for Unmanned Aerial Vehicle Detection and Identification
Mar 12, 2025



In this paper, we propose RFUAV as a new benchmark dataset for radio-frequency based (RF-based) unmanned aerial vehicle (UAV) identification and address the following challenges: Firstly, many existing datasets feature a restricted variety of drone types and insufficient volumes of raw data, which fail to meet the demands of practical applications. Secondly, existing datasets often lack raw data covering a broad range of signal-to-noise ratios (SNR), or do not provide tools for transforming raw data to different SNR levels. This limitation undermines the validity of model training and evaluation. Lastly, many existing datasets do not offer open-access evaluation tools, leading to a lack of unified evaluation standards in current research within this field. RFUAV comprises approximately 1.3 TB of raw frequency data collected from 37 distinct UAVs using the Universal Software Radio Peripheral (USRP) device in real-world environments. Through in-depth analysis of the RF data in RFUAV, we define a drone feature sequence called RF drone fingerprint, which aids in distinguishing drone signals. In addition to the dataset, RFUAV provides a baseline preprocessing method and model evaluation tools. Rigorous experiments demonstrate that these preprocessing methods achieve state-of-the-art (SOTA) performance using the provided evaluation tools. The RFUAV dataset and baseline implementation are publicly available at https://github.com/kitoweeknd/RFUAV/.
LLMIdxAdvis: Resource-Efficient Index Advisor Utilizing Large Language Model
Mar 10, 2025
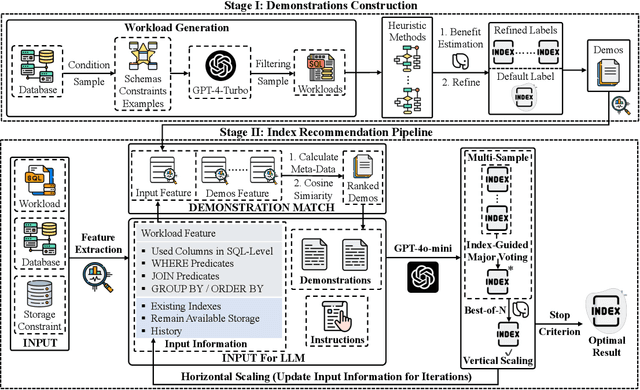


Index recommendation is essential for improving query performance in database management systems (DBMSs) through creating an optimal set of indexes under specific constraints. Traditional methods, such as heuristic and learning-based approaches, are effective but face challenges like lengthy recommendation time, resource-intensive training, and poor generalization across different workloads and database schemas. To address these issues, we propose LLMIdxAdvis, a resource-efficient index advisor that uses large language models (LLMs) without extensive fine-tuning. LLMIdxAdvis frames index recommendation as a sequence-to-sequence task, taking target workload, storage constraint, and corresponding database environment as input, and directly outputting recommended indexes. It constructs a high-quality demonstration pool offline, using GPT-4-Turbo to synthesize diverse SQL queries and applying integrated heuristic methods to collect both default and refined labels. During recommendation, these demonstrations are ranked to inject database expertise via in-context learning. Additionally, LLMIdxAdvis extracts workload features involving specific column statistical information to strengthen LLM's understanding, and introduces a novel inference scaling strategy combining vertical scaling (via ''Index-Guided Major Voting'' and Best-of-N) and horizontal scaling (through iterative ''self-optimization'' with database feedback) to enhance reliability. Experiments on 3 OLAP and 2 real-world benchmarks reveal that LLMIdxAdvis delivers competitive index recommendation with reduced runtime, and generalizes effectively across different workloads and database schemas.
OmniSQL: Synthesizing High-quality Text-to-SQL Data at Scale
Mar 04, 2025Text-to-SQL, the task of translating natural language questions into SQL queries, plays a crucial role in enabling non-experts to interact with databases. While recent advancements in large language models (LLMs) have significantly enhanced text-to-SQL performance, existing approaches face notable limitations in real-world text-to-SQL applications. Prompting-based methods often depend on closed-source LLMs, which are expensive, raise privacy concerns, and lack customization. Fine-tuning-based methods, on the other hand, suffer from poor generalizability due to the limited coverage of publicly available training data. To overcome these challenges, we propose a novel and scalable text-to-SQL data synthesis framework for automatically synthesizing large-scale, high-quality, and diverse datasets without extensive human intervention. Using this framework, we introduce SynSQL-2.5M, the first million-scale text-to-SQL dataset, containing 2.5 million samples spanning over 16,000 synthetic databases. Each sample includes a database, SQL query, natural language question, and chain-of-thought (CoT) solution. Leveraging SynSQL-2.5M, we develop OmniSQL, a powerful open-source text-to-SQL model available in three sizes: 7B, 14B, and 32B. Extensive evaluations across nine datasets demonstrate that OmniSQL achieves state-of-the-art performance, matching or surpassing leading closed-source and open-source LLMs, including GPT-4o and DeepSeek-V3, despite its smaller size. We release all code, datasets, and models to support further research.
Cluster Catch Digraphs with the Nearest Neighbor Distance
Jan 09, 2025We introduce a new method for clustering based on Cluster Catch Digraphs (CCDs). The new method addresses the limitations of RK-CCDs by employing a new variant of spatial randomness test that employs the nearest neighbor distance (NND) instead of the Ripley's K function used by RK-CCDs. We conduct a comprehensive Monte Carlo analysis to assess the performance of our method, considering factors such as dimensionality, data set size, number of clusters, cluster volumes, and inter-cluster distance. Our method is particularly effective for high-dimensional data sets, comparable to or outperforming KS-CCDs and RK-CCDs that rely on a KS-type statistic or the Ripley's K function. We also evaluate our methods using real and complex data sets, comparing them to well-known clustering methods. Again, our methods exhibit competitive performance, producing high-quality clusters with desirable properties. Keywords: Graph-based clustering, Cluster catch digraphs, High-dimensional data, The nearest neighbor distance, Spatial randomness test
Outlyingness Scores with Cluster Catch Digraphs
Jan 09, 2025This paper introduces two novel, outlyingness scores (OSs) based on Cluster Catch Digraphs (CCDs): Outbound Outlyingness Score (OOS) and Inbound Outlyingness Score (IOS). These scores enhance the interpretability of outlier detection results. Both OSs employ graph-, density-, and distribution-based techniques, tailored to high-dimensional data with varying cluster shapes and intensities. OOS evaluates the outlyingness of a point relative to its nearest neighbors, while IOS assesses the total ``influence" a point receives from others within its cluster. Both OSs effectively identify global and local outliers, invariant to data collinearity. Moreover, IOS is robust to the masking problems. With extensive Monte Carlo simulations, we compare the performance of both OSs with CCD-based, traditional, and state-of-the-art outlier detection methods. Both OSs exhibit substantial overall improvements over the CCD-based methods in both artificial and real-world data sets, particularly with IOS, which delivers the best overall performance among all the methods, especially in high-dimensional settings. Keywords: Outlier detection, Outlyingness score, Graph-based clustering, Cluster catch digraphs, High-dimensional data.
TSEML: A task-specific embedding-based method for few-shot classification of cancer molecular subtypes
Dec 17, 2024Molecular subtyping of cancer is recognized as a critical and challenging upstream task for personalized therapy. Existing deep learning methods have achieved significant performance in this domain when abundant data samples are available. However, the acquisition of densely labeled samples for cancer molecular subtypes remains a significant challenge for conventional data-intensive deep learning approaches. In this work, we focus on the few-shot molecular subtype prediction problem in heterogeneous and small cancer datasets, aiming to enhance precise diagnosis and personalized treatment. We first construct a new few-shot dataset for cancer molecular subtype classification and auxiliary cancer classification, named TCGA Few-Shot, from existing publicly available datasets. To effectively leverage the relevant knowledge from both tasks, we introduce a task-specific embedding-based meta-learning framework (TSEML). TSEML leverages the synergistic strengths of a model-agnostic meta-learning (MAML) approach and a prototypical network (ProtoNet) to capture diverse and fine-grained features. Comparative experiments conducted on the TCGA Few-Shot dataset demonstrate that our TSEML framework achieves superior performance in addressing the problem of few-shot molecular subtype classification.
ChatTS: Aligning Time Series with LLMs via Synthetic Data for Enhanced Understanding and Reasoning
Dec 04, 2024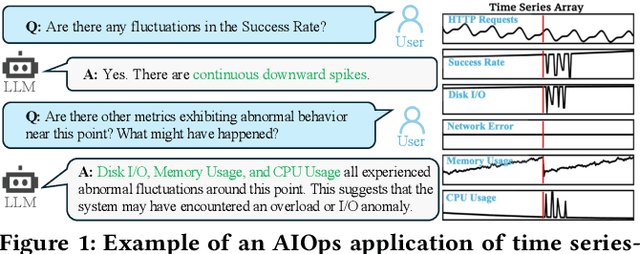
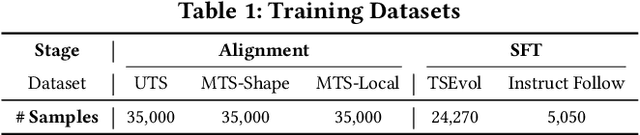
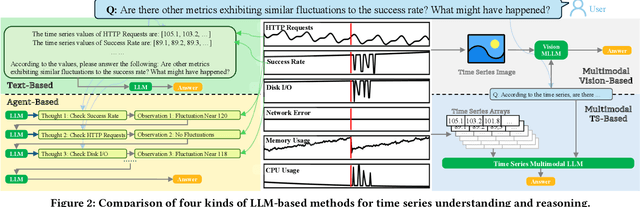
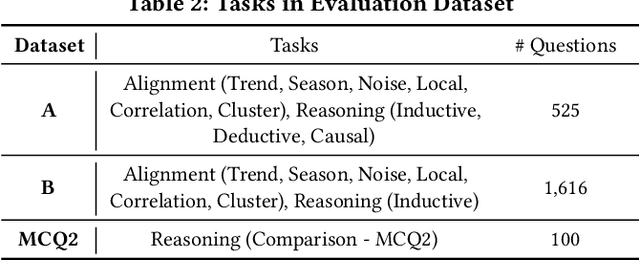
Understanding time series is crucial for its application in real-world scenarios. Recently, large language models (LLMs) have been increasingly applied to time series tasks, leveraging their strong language capabilities to enhance various applications. However, research on multimodal LLMs (MLLMs) for time series understanding and reasoning remains limited, primarily due to the scarcity of high-quality datasets that align time series with textual information. This paper introduces ChatTS, a novel MLLM designed for time series analysis. ChatTS treats time series as a modality, similar to how vision MLLMs process images, enabling it to perform both understanding and reasoning with time series. To address the scarcity of training data, we propose an attribute-based method for generating synthetic time series with detailed attribute descriptions. We further introduce Time Series Evol-Instruct, a novel approach that generates diverse time series Q&As, enhancing the model's reasoning capabilities. To the best of our knowledge, ChatTS is the first MLLM that takes multivariate time series as input, which is fine-tuned exclusively on synthetic datasets. We evaluate its performance using benchmark datasets with real-world data, including six alignment tasks and four reasoning tasks. Our results show that ChatTS significantly outperforms existing vision-based MLLMs (e.g., GPT-4o) and text/agent-based LLMs, achieving a 46.0% improvement in alignment tasks and a 25.8% improvement in reasoning tasks.
Outlier Detection with Cluster Catch Digraphs
Sep 17, 2024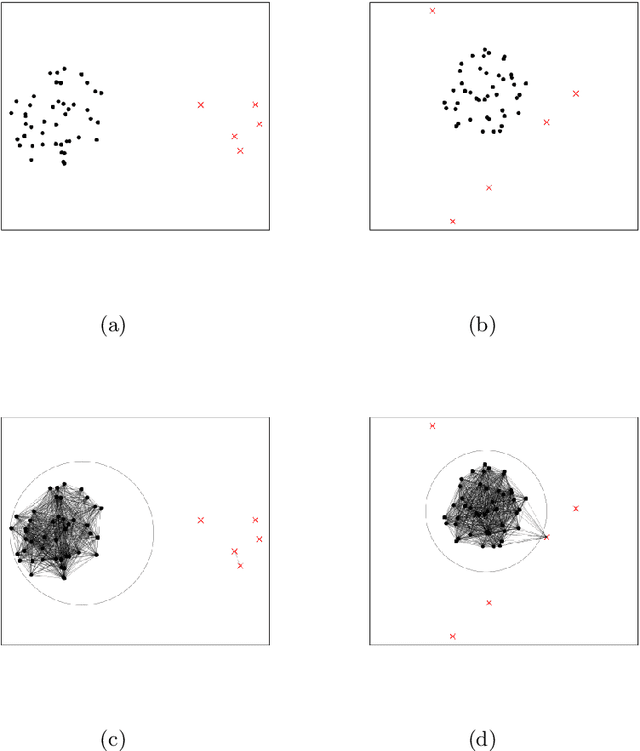

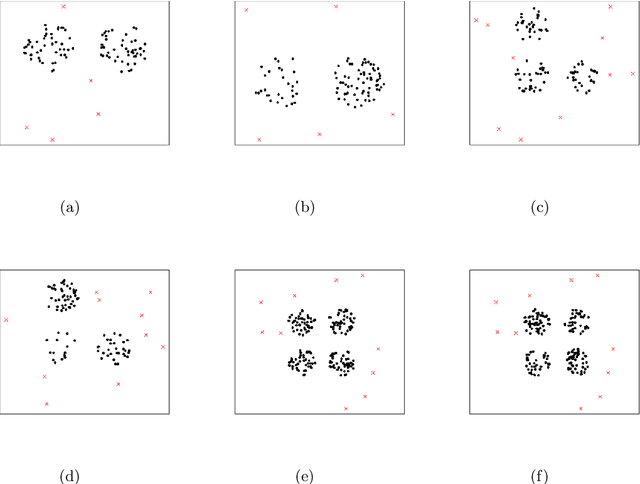
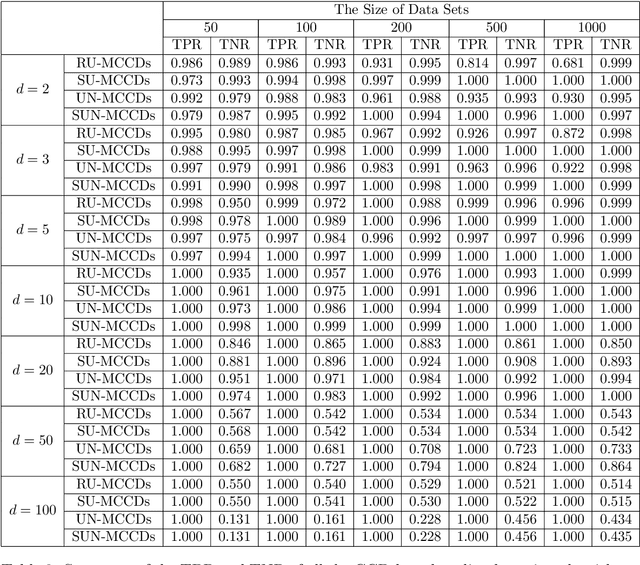
This paper introduces a novel family of outlier detection algorithms based on Cluster Catch Digraphs (CCDs), specifically tailored to address the challenges of high dimensionality and varying cluster shapes, which deteriorate the performance of most traditional outlier detection methods. We propose the Uniformity-Based CCD with Mutual Catch Graph (U-MCCD), the Uniformity- and Neighbor-Based CCD with Mutual Catch Graph (UN-MCCD), and their shape-adaptive variants (SU-MCCD and SUN-MCCD), which are designed to detect outliers in data sets with arbitrary cluster shapes and high dimensions. We present the advantages and shortcomings of these algorithms and provide the motivation or need to define each particular algorithm. Through comprehensive Monte Carlo simulations, we assess their performance and demonstrate the robustness and effectiveness of our algorithms across various settings and contamination levels. We also illustrate the use of our algorithms on various real-life data sets. The U-MCCD algorithm efficiently identifies outliers while maintaining high true negative rates, and the SU-MCCD algorithm shows substantial improvement in handling non-uniform clusters. Additionally, the UN-MCCD and SUN-MCCD algorithms address the limitations of existing methods in high-dimensional spaces by utilizing Nearest Neighbor Distances (NND) for clustering and outlier detection. Our results indicate that these novel algorithms offer substantial advancements in the accuracy and adaptability of outlier detection, providing a valuable tool for various real-world applications. Keyword: Outlier detection, Graph-based clustering, Cluster catch digraphs, $k$-nearest-neighborhood, Mutual catch graphs, Nearest neighbor distance.