 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKairosVL: Orchestrating Time Series and Semantics for Unified Reasoning
Feb 24, 2026Driven by the increasingly complex and decision-oriented demands of time series analysis, we introduce the Semantic-Conditional Time Series Reasoning task, which extends conventional time series analysis beyond purely numerical modeling to incorporate contextual and semantic understanding. To further enhance the mode's reasoning capabilities on complex time series problems, we propose a two-round reinforcement learning framework: the first round strengthens the mode's perception of fundamental temporal primitives, while the second focuses on semantic-conditioned reasoning. The resulting model, KairosVL, achieves competitive performance across both synthetic and real-world tasks. Extensive experiments and ablation studies demonstrate that our framework not only boosts performance but also preserves intrinsic reasoning ability and significantly improves generalization to unseen scenarios. To summarize, our work highlights the potential of combining semantic reasoning with temporal modeling and provides a practical framework for real-world time series intelligence, which is in urgent demand.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
DockSmith: Scaling Reliable Coding Environments via an Agentic Docker Builder
Jan 31, 2026Reliable Docker-based environment construction is a dominant bottleneck for scaling execution-grounded training and evaluation of software engineering agents. We introduce DockSmith, a specialized agentic Docker builder designed to address this challenge. DockSmith treats environment construction not only as a preprocessing step, but as a core agentic capability that exercises long-horizon tool use, dependency reasoning, and failure recovery, yielding supervision that transfers beyond Docker building itself. DockSmith is trained on large-scale, execution-grounded Docker-building trajectories produced by a SWE-Factory-style pipeline augmented with a loop-detection controller and a cross-task success memory. Training a 30B-A3B model on these trajectories achieves open-source state-of-the-art performance on Multi-Docker-Eval, with 39.72% Fail-to-Pass and 58.28% Commit Rate. Moreover, DockSmith improves out-of-distribution performance on SWE-bench Verified, SWE-bench Multilingual, and Terminal-Bench 2.0, demonstrating broader agentic benefits of environment construction.
STEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
TimeSense:Making Large Language Models Proficient in Time-Series Analysis
Nov 09, 2025In the time-series domain, an increasing number of works combine text with temporal data to leverage the reasoning capabilities of large language models (LLMs) for various downstream time-series understanding tasks. This enables a single model to flexibly perform tasks that previously required specialized models for each domain. However, these methods typically rely on text labels for supervision during training, biasing the model toward textual cues while potentially neglecting the full temporal features. Such a bias can lead to outputs that contradict the underlying time-series context. To address this issue, we construct the EvalTS benchmark, comprising 10 tasks across three difficulty levels, from fundamental temporal pattern recognition to complex real-world reasoning, to evaluate models under more challenging and realistic scenarios. We also propose TimeSense, a multimodal framework that makes LLMs proficient in time-series analysis by balancing textual reasoning with a preserved temporal sense. TimeSense incorporates a Temporal Sense module that reconstructs the input time-series within the model's context, ensuring that textual reasoning is grounded in the time-series dynamics. Moreover, to enhance spatial understanding of time-series data, we explicitly incorporate coordinate-based positional embeddings, which provide each time point with spatial context and enable the model to capture structural dependencies more effectively. Experimental results demonstrate that TimeSense achieves state-of-the-art performance across multiple tasks, and it particularly outperforms existing methods on complex multi-dimensional time-series reasoning tasks.
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Feb 18, 2025Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.
ChatTS: Aligning Time Series with LLMs via Synthetic Data for Enhanced Understanding and Reasoning
Dec 04, 2024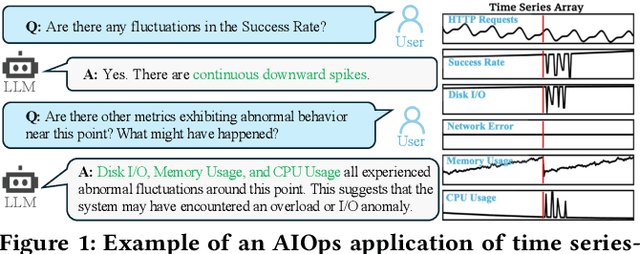
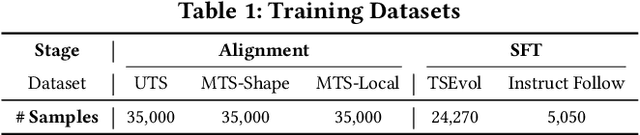
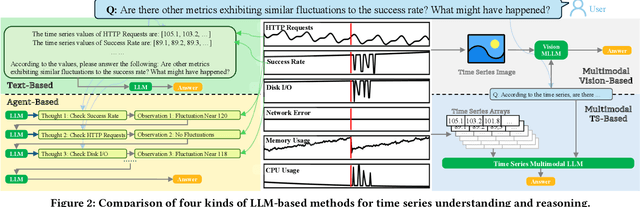
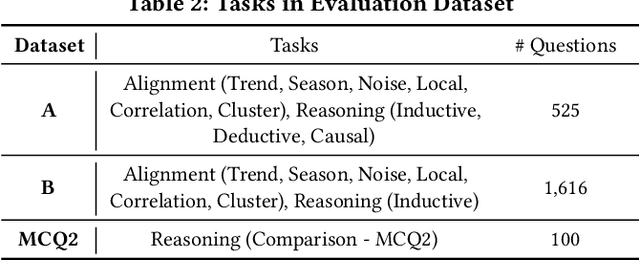
Understanding time series is crucial for its application in real-world scenarios. Recently, large language models (LLMs) have been increasingly applied to time series tasks, leveraging their strong language capabilities to enhance various applications. However, research on multimodal LLMs (MLLMs) for time series understanding and reasoning remains limited, primarily due to the scarcity of high-quality datasets that align time series with textual information. This paper introduces ChatTS, a novel MLLM designed for time series analysis. ChatTS treats time series as a modality, similar to how vision MLLMs process images, enabling it to perform both understanding and reasoning with time series. To address the scarcity of training data, we propose an attribute-based method for generating synthetic time series with detailed attribute descriptions. We further introduce Time Series Evol-Instruct, a novel approach that generates diverse time series Q&As, enhancing the model's reasoning capabilities. To the best of our knowledge, ChatTS is the first MLLM that takes multivariate time series as input, which is fine-tuned exclusively on synthetic datasets. We evaluate its performance using benchmark datasets with real-world data, including six alignment tasks and four reasoning tasks. Our results show that ChatTS significantly outperforms existing vision-based MLLMs (e.g., GPT-4o) and text/agent-based LLMs, achieving a 46.0% improvement in alignment tasks and a 25.8% improvement in reasoning tasks.
A Dynamic Linear Bias Incorporation Scheme for Nonnegative Latent Factor Analysis
Sep 19, 2023
High-Dimensional and Incomplete (HDI) data is commonly encountered in big data-related applications like social network services systems, which are concerning the limited interactions among numerous nodes. Knowledge acquisition from HDI data is a vital issue in the domain of data science due to their embedded rich patterns like node behaviors, where the fundamental task is to perform HDI data representation learning. Nonnegative Latent Factor Analysis (NLFA) models have proven to possess the superiority to address this issue, where a linear bias incorporation (LBI) scheme is important in present the training overshooting and fluctuation, as well as preventing the model from premature convergence. However, existing LBI schemes are all statistic ones where the linear biases are fixed, which significantly restricts the scalability of the resultant NLFA model and results in loss of representation learning ability to HDI data. Motivated by the above discoveries, this paper innovatively presents the dynamic linear bias incorporation (DLBI) scheme. It firstly extends the linear bias vectors into matrices, and then builds a binary weight matrix to switch the active/inactive states of the linear biases. The weight matrix's each entry switches between the binary states dynamically corresponding to the linear bias value variation, thereby establishing the dynamic linear biases for an NLFA model. Empirical studies on three HDI datasets from real applications demonstrate that the proposed DLBI-based NLFA model obtains higher representation accuracy several than state-of-the-art models do, as well as highly-competitive computational efficiency.
Space-Air-Ground Integrated Network : A Survey
Jul 27, 2023

Since existing mobile communication networks may not be able to meet the low latency and high-efficiency requirements of emerging technologies and applications, novel network architectures need to be investigated to support these new requirements. As a new network architecture that integrates satellite systems, air networks and ground communication, Space-Air-Ground Integrated Network (SAGIN) has attracted extensive attention in recent years. This paper summarizes the recent research work on SAGIN from several aspects, with the basic information of SAGIN first introduced, followed by the physical characteristics. Then the drive and prospects of the current SAGIN architecture in supporting new requirements are deeply analyzed. On this basis, the requirements and challenges are analyzed. Finally, it summarizes the existing solutions and prospects the future research directions.
Multi-constrained Symmetric Nonnegative Latent Factor Analysis for Accurately Representing Large-scale Undirected Weighted Networks
Jun 06, 2023An Undirected Weighted Network (UWN) is frequently encountered in a big-data-related application concerning the complex interactions among numerous nodes, e.g., a protein interaction network from a bioinformatics application. A Symmetric High-Dimensional and Incomplete (SHDI) matrix can smoothly illustrate such an UWN, which contains rich knowledge like node interaction behaviors and local complexes. To extract desired knowledge from an SHDI matrix, an analysis model should carefully consider its symmetric-topology for describing an UWN's intrinsic symmetry. Representation learning to an UWN borrows the success of a pyramid of symmetry-aware models like a Symmetric Nonnegative Matrix Factorization (SNMF) model whose objective function utilizes a sole Latent Factor (LF) matrix for representing SHDI's symmetry rigorously. However, they suffer from the following drawbacks: 1) their computational complexity is high; and 2) their modeling strategy narrows their representation features, making them suffer from low learning ability. Aiming at addressing above critical issues, this paper proposes a Multi-constrained Symmetric Nonnegative Latent-factor-analysis (MSNL) model with two-fold ideas: 1) introducing multi-constraints composed of multiple LF matrices, i.e., inequality and equality ones into a data-density-oriented objective function for precisely representing the intrinsic symmetry of an SHDI matrix with broadened feature space; and 2) implementing an Alternating Direction Method of Multipliers (ADMM)-incorporated learning scheme for precisely solving such a multi-constrained model. Empirical studies on three SHDI matrices from a real bioinformatics or industrial application demonstrate that the proposed MSNL model achieves stronger representation learning ability to an SHDI matrix than state-of-the-art models do.