 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph of States: Solving Abductive Tasks with Large Language Models
Mar 22, 2026Logical reasoning encompasses deduction, induction, and abduction. However, while Large Language Models (LLMs) have effectively mastered the former two, abductive reasoning remains significantly underexplored. Existing frameworks, predominantly designed for static deductive tasks, fail to generalize to abductive reasoning due to unstructured state representation and lack of explicit state control. Consequently, they are inevitably prone to Evidence Fabrication, Context Drift, Failed Backtracking, and Early Stopping. To bridge this gap, we introduce Graph of States (GoS), a general-purpose neuro-symbolic framework tailored for abductive tasks. GoS grounds multi-agent collaboration in a structured belief states, utilizing a causal graph to explicitly encode logical dependencies and a state machine to govern the valid transitions of the reasoning process. By dynamically aligning the reasoning focus with these symbolic constraints, our approach transforms aimless, unconstrained exploration into a convergent, directed search. Extensive evaluations on two real-world datasets demonstrate that GoS significantly outperforms all baselines, providing a robust solution for complex abductive tasks. Code repo and all prompts: https://anonymous.4open.science/r/Graph-of-States-5B4E.
ChatTS: Aligning Time Series with LLMs via Synthetic Data for Enhanced Understanding and Reasoning
Dec 04, 2024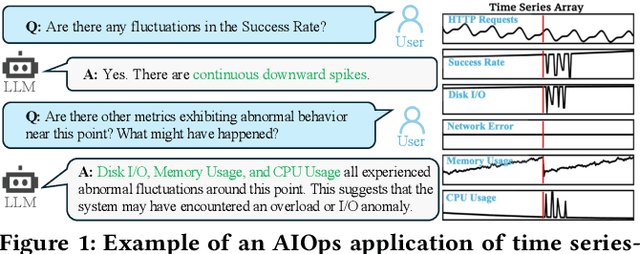
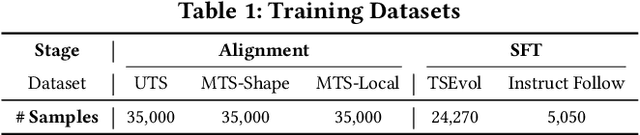
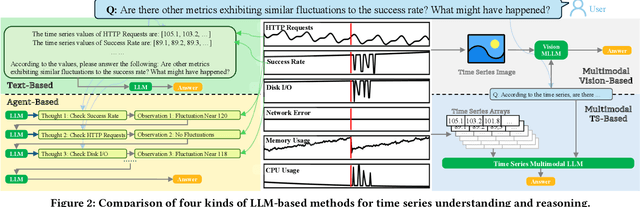
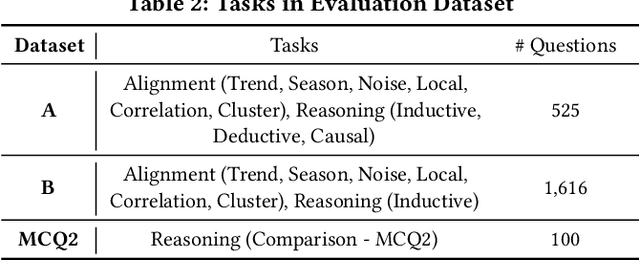
Understanding time series is crucial for its application in real-world scenarios. Recently, large language models (LLMs) have been increasingly applied to time series tasks, leveraging their strong language capabilities to enhance various applications. However, research on multimodal LLMs (MLLMs) for time series understanding and reasoning remains limited, primarily due to the scarcity of high-quality datasets that align time series with textual information. This paper introduces ChatTS, a novel MLLM designed for time series analysis. ChatTS treats time series as a modality, similar to how vision MLLMs process images, enabling it to perform both understanding and reasoning with time series. To address the scarcity of training data, we propose an attribute-based method for generating synthetic time series with detailed attribute descriptions. We further introduce Time Series Evol-Instruct, a novel approach that generates diverse time series Q&As, enhancing the model's reasoning capabilities. To the best of our knowledge, ChatTS is the first MLLM that takes multivariate time series as input, which is fine-tuned exclusively on synthetic datasets. We evaluate its performance using benchmark datasets with real-world data, including six alignment tasks and four reasoning tasks. Our results show that ChatTS significantly outperforms existing vision-based MLLMs (e.g., GPT-4o) and text/agent-based LLMs, achieving a 46.0% improvement in alignment tasks and a 25.8% improvement in reasoning tasks.
OpsEval: A Comprehensive Task-Oriented AIOps Benchmark for Large Language Models
Oct 12, 2023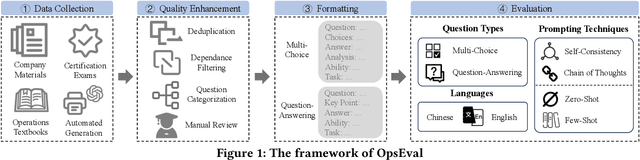
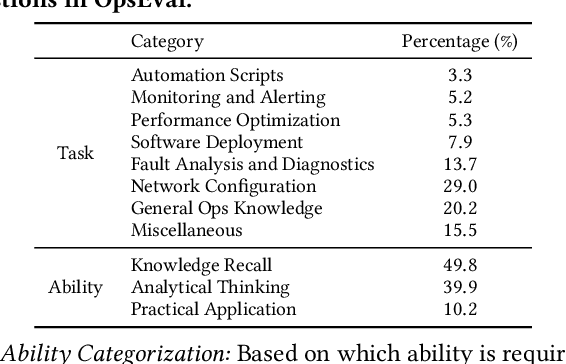

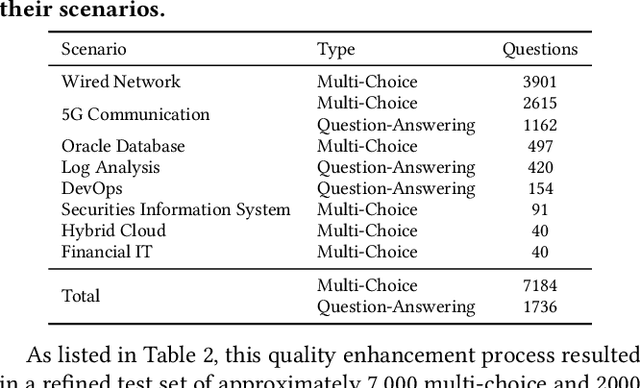
Large language models (LLMs) have exhibited remarkable capabilities in NLP-related tasks such as translation, summarizing, and generation. The application of LLMs in specific areas, notably AIOps (Artificial Intelligence for IT Operations), holds great potential due to their advanced abilities in information summarizing, report analyzing, and ability of API calling. Nevertheless, the performance of current LLMs in AIOps tasks is yet to be determined. Furthermore, a comprehensive benchmark is required to steer the optimization of LLMs tailored for AIOps. Compared with existing benchmarks that focus on evaluating specific fields like network configuration, in this paper, we present \textbf{OpsEval}, a comprehensive task-oriented AIOps benchmark designed for LLMs. For the first time, OpsEval assesses LLMs' proficiency in three crucial scenarios (Wired Network Operation, 5G Communication Operation, and Database Operation) at various ability levels (knowledge recall, analytical thinking, and practical application). The benchmark includes 7,200 questions in both multiple-choice and question-answer (QA) formats, available in English and Chinese. With quantitative and qualitative results, we show how various LLM tricks can affect the performance of AIOps, including zero-shot, chain-of-thought, and few-shot in-context learning. We find that GPT4-score is more consistent with experts than widely used Bleu and Rouge, which can be used to replace automatic metrics for large-scale qualitative evaluations.
Micro- and Macro-Level Churn Analysis of Large-Scale Mobile Games
Jan 14, 2019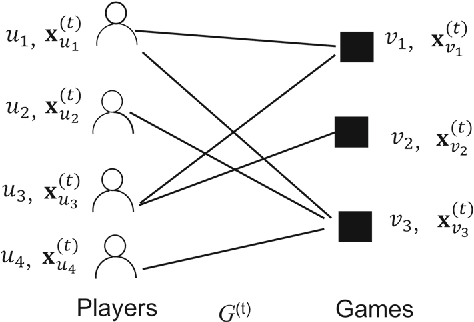

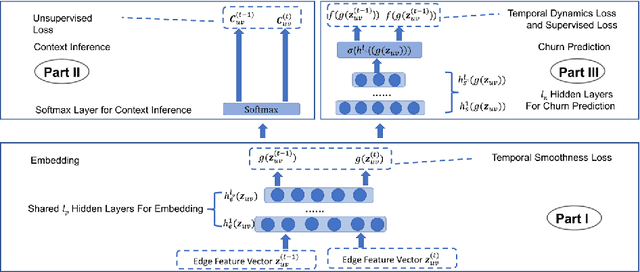
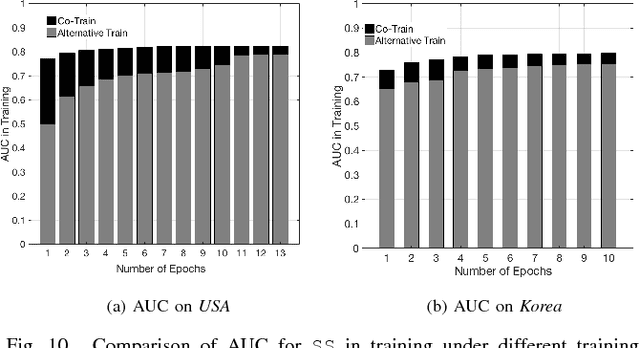
As mobile devices become more and more popular, mobile gaming has emerged as a promising market with billion-dollar revenues. A variety of mobile game platforms and services have been developed around the world. A critical challenge for these platforms and services is to understand the churn behavior in mobile games, which usually involves churn at micro level (between an app and a specific user) and macro level (between an app and all its users). Accurate micro-level churn prediction and macro-level churn ranking will benefit many stakeholders such as game developers, advertisers, and platform operators. In this paper, we present the first large-scale churn analysis for mobile games that supports both micro-level churn prediction and macro-level churn ranking. For micro-level churn prediction, in view of the common limitations of the state-of-the-art methods built upon traditional machine learning models, we devise a novel semi-supervised and inductive embedding model that jointly learns the prediction function and the embedding function for user-app relationships. We model these two functions by deep neural networks with a unique edge embedding technique that is able to capture both contextual information and relationship dynamics. We also design a novel attributed random walk technique that takes into consideration both topological adjacency and attribute similarities. To address macro-level churn ranking, we propose to construct a relationship graph with estimated micro-level churn probabilities as edge weights and adapt link analysis algorithms on the graph. We devise a simple algorithm SimSum and adapt two more advanced algorithms PageRank and HITS. The performance of our solutions for the two-level churn analysis problems is evaluated on real-world data collected from the Samsung Game Launcher platform.
Streaming Network Embedding through Local Actions
Nov 14, 2018
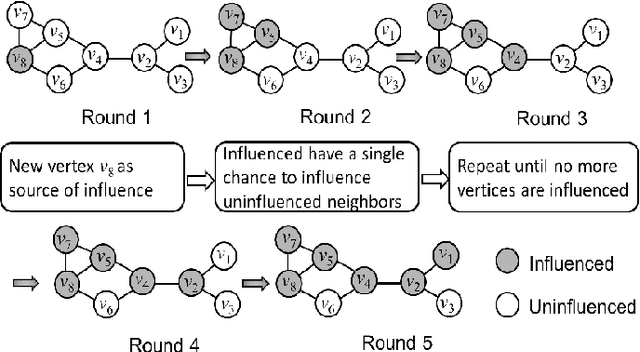
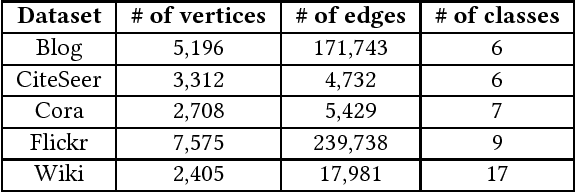
Recently, considerable research attention has been paid to network embedding, a popular approach to construct feature vectors of vertices. Due to the curse of dimensionality and sparsity in graphical datasets, this approach has become indispensable for machine learning tasks over large networks. The majority of existing literature has considered this technique under the assumption that the network is static. However, networks in many applications, nodes and edges accrue to a growing network as a streaming. A small number of very recent results have addressed the problem of embedding for dynamic networks. However, they either rely on knowledge of vertex attributes, suffer high-time complexity or need to be re-trained without closed-form expression. Thus the approach of adapting the existing methods to the streaming environment faces non-trivial technical challenges. These challenges motivate developing new approaches to the problems of streaming network embedding. In this paper, We propose a new framework that is able to generate latent features for new vertices with high efficiency and low complexity under specified iteration rounds. We formulate a constrained optimization problem for the modification of the representation resulting from a stream arrival. We show this problem has no closed-form solution and instead develop an online approximation solution. Our solution follows three steps: (1) identify vertices affected by new vertices, (2) generate latent features for new vertices, and (3) update the latent features of the most affected vertices. The generated representations are provably feasible and not far from the optimal ones in terms of expectation. Multi-class classification and clustering on five real-world networks demonstrate that our model can efficiently update vertex representations and simultaneously achieve comparable or even better performance.
A Semi-Supervised and Inductive Embedding Model for Churn Prediction of Large-Scale Mobile Games
Oct 10, 2018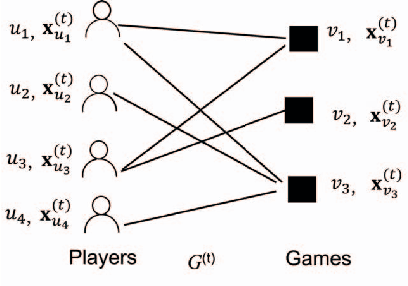
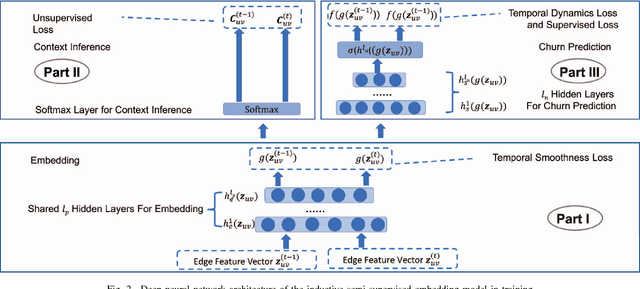
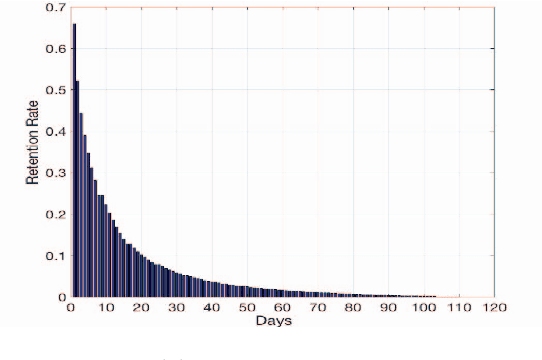
Mobile gaming has emerged as a promising market with billion-dollar revenues. A variety of mobile game platforms and services have been developed around the world. One critical challenge for these platforms and services is to understand user churn behavior in mobile games. Accurate churn prediction will benefit many stakeholders such as game developers, advertisers, and platform operators. In this paper, we present the first large-scale churn prediction solution for mobile games. In view of the common limitations of the state-of-the-art methods built upon traditional machine learning models, we devise a novel semi-supervised and inductive embedding model that jointly learns the prediction function and the embedding function for user-app relationships. We model these two functions by deep neural networks with a unique edge embedding technique that is able to capture both contextual information and relationship dynamics. We also design a novel attributed random walk technique that takes into consideration both topological adjacency and attribute similarities. To evaluate the performance of our solution, we collect real-world data from the Samsung Game Launcher platform that includes tens of thousands of games and hundreds of millions of user-app interactions. The experimental results with this data demonstrate the superiority of our proposed model against existing state-of-the-art methods.