 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLay2Story: Extending Diffusion Transformers for Layout-Togglable Story Generation
Aug 12, 2025Storytelling tasks involving generating consistent subjects have gained significant attention recently. However, existing methods, whether training-free or training-based, continue to face challenges in maintaining subject consistency due to the lack of fine-grained guidance and inter-frame interaction. Additionally, the scarcity of high-quality data in this field makes it difficult to precisely control storytelling tasks, including the subject's position, appearance, clothing, expression, and posture, thereby hindering further advancements. In this paper, we demonstrate that layout conditions, such as the subject's position and detailed attributes, effectively facilitate fine-grained interactions between frames. This not only strengthens the consistency of the generated frame sequence but also allows for precise control over the subject's position, appearance, and other key details. Building on this, we introduce an advanced storytelling task: Layout-Togglable Storytelling, which enables precise subject control by incorporating layout conditions. To address the lack of high-quality datasets with layout annotations for this task, we develop Lay2Story-1M, which contains over 1 million 720p and higher-resolution images, processed from approximately 11,300 hours of cartoon videos. Building on Lay2Story-1M, we create Lay2Story-Bench, a benchmark with 3,000 prompts designed to evaluate the performance of different methods on this task. Furthermore, we propose Lay2Story, a robust framework based on the Diffusion Transformers (DiTs) architecture for Layout-Togglable Storytelling tasks. Through both qualitative and quantitative experiments, we find that our method outperforms the previous state-of-the-art (SOTA) techniques, achieving the best results in terms of consistency, semantic correlation, and aesthetic quality.
WISA: World Simulator Assistant for Physics-Aware Text-to-Video Generation
Mar 11, 2025Recent rapid advancements in text-to-video (T2V) generation, such as SoRA and Kling, have shown great potential for building world simulators. However, current T2V models struggle to grasp abstract physical principles and generate videos that adhere to physical laws. This challenge arises primarily from a lack of clear guidance on physical information due to a significant gap between abstract physical principles and generation models. To this end, we introduce the World Simulator Assistant (WISA), an effective framework for decomposing and incorporating physical principles into T2V models. Specifically, WISA decomposes physical principles into textual physical descriptions, qualitative physical categories, and quantitative physical properties. To effectively embed these physical attributes into the generation process, WISA incorporates several key designs, including Mixture-of-Physical-Experts Attention (MoPA) and a Physical Classifier, enhancing the model's physics awareness. Furthermore, most existing datasets feature videos where physical phenomena are either weakly represented or entangled with multiple co-occurring processes, limiting their suitability as dedicated resources for learning explicit physical principles. We propose a novel video dataset, WISA-32K, collected based on qualitative physical categories. It consists of 32,000 videos, representing 17 physical laws across three domains of physics: dynamics, thermodynamics, and optics. Experimental results demonstrate that WISA can effectively enhance the compatibility of T2V models with real-world physical laws, achieving a considerable improvement on the VideoPhy benchmark. The visual exhibitions of WISA and WISA-32K are available in the https://360cvgroup.github.io/WISA/.
RelaCtrl: Relevance-Guided Efficient Control for Diffusion Transformers
Feb 21, 2025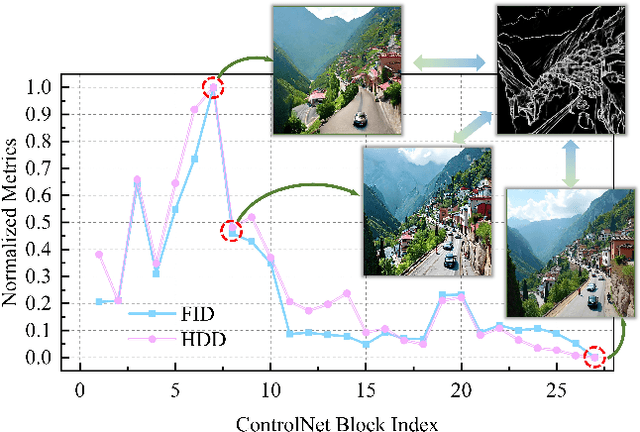
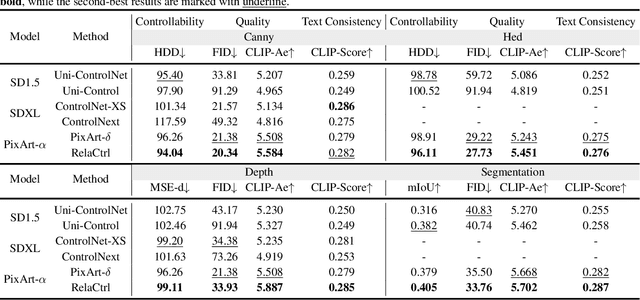
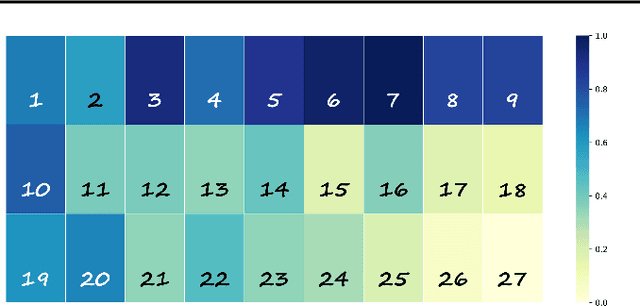
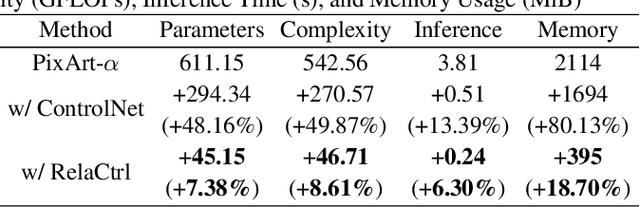
The Diffusion Transformer plays a pivotal role in advancing text-to-image and text-to-video generation, owing primarily to its inherent scalability. However, existing controlled diffusion transformer methods incur significant parameter and computational overheads and suffer from inefficient resource allocation due to their failure to account for the varying relevance of control information across different transformer layers. To address this, we propose the Relevance-Guided Efficient Controllable Generation framework, RelaCtrl, enabling efficient and resource-optimized integration of control signals into the Diffusion Transformer. First, we evaluate the relevance of each layer in the Diffusion Transformer to the control information by assessing the "ControlNet Relevance Score"-i.e., the impact of skipping each control layer on both the quality of generation and the control effectiveness during inference. Based on the strength of the relevance, we then tailor the positioning, parameter scale, and modeling capacity of the control layers to reduce unnecessary parameters and redundant computations. Additionally, to further improve efficiency, we replace the self-attention and FFN in the commonly used copy block with the carefully designed Two-Dimensional Shuffle Mixer (TDSM), enabling efficient implementation of both the token mixer and channel mixer. Both qualitative and quantitative experimental results demonstrate that our approach achieves superior performance with only 15% of the parameters and computational complexity compared to PixArt-delta.
Qihoo-T2X: An Efficiency-Focused Diffusion Transformer via Proxy Tokens for Text-to-Any-Task
Sep 06, 2024The global self-attention mechanism in diffusion transformers involves redundant computation due to the sparse and redundant nature of visual information, and the attention map of tokens within a spatial window shows significant similarity. To address this redundancy, we propose the Proxy Token Diffusion Transformer (PT-DiT), which employs sparse representative token attention (where the number of representative tokens is much smaller than the total number of tokens) to model global visual information efficiently. Specifically, in each transformer block, we randomly sample one token from each spatial-temporal window to serve as a proxy token for that region. The global semantics are captured through the self-attention of these proxy tokens and then injected into all latent tokens via cross-attention. Simultaneously, we introduce window and shift window attention to address the limitations in detail modeling caused by the sparse attention mechanism. Building on the well-designed PT-DiT, we further develop the Qihoo-T2X family, which includes a variety of models for T2I, T2V, and T2MV tasks. Experimental results show that PT-DiT achieves competitive performance while reducing the computational complexity in both image and video generation tasks (e.g., a 48% reduction compared to DiT and a 35% reduction compared to Pixart-alpha). Our source code is available at https://github.com/360CVGroup/Qihoo-T2X.
Ensemble Predicate Decoding for Unbiased Scene Graph Generation
Aug 26, 2024Scene Graph Generation (SGG) aims to generate a comprehensive graphical representation that accurately captures the semantic information of a given scenario. However, the SGG model's performance in predicting more fine-grained predicates is hindered by a significant predicate bias. According to existing works, the long-tail distribution of predicates in training data results in the biased scene graph. However, the semantic overlap between predicate categories makes predicate prediction difficult, and there is a significant difference in the sample size of semantically similar predicates, making the predicate prediction more difficult. Therefore, higher requirements are placed on the discriminative ability of the model. In order to address this problem, this paper proposes Ensemble Predicate Decoding (EPD), which employs multiple decoders to attain unbiased scene graph generation. Two auxiliary decoders trained on lower-frequency predicates are used to improve the discriminative ability of the model. Extensive experiments are conducted on the VG, and the experiment results show that EPD enhances the model's representation capability for predicates. In addition, we find that our approach ensures a relatively superior predictive capability for more frequent predicates compared to previous unbiased SGG methods.
FancyVideo: Towards Dynamic and Consistent Video Generation via Cross-frame Textual Guidance
Aug 15, 2024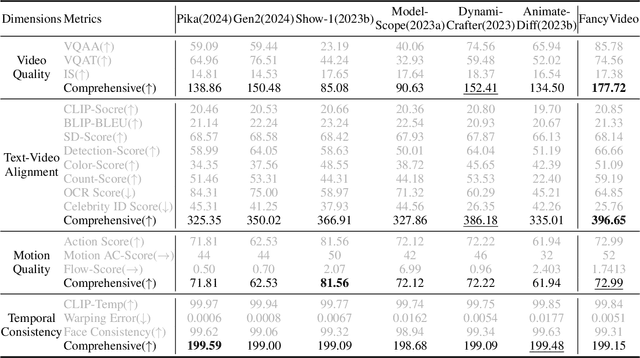



Synthesizing motion-rich and temporally consistent videos remains a challenge in artificial intelligence, especially when dealing with extended durations. Existing text-to-video (T2V) models commonly employ spatial cross-attention for text control, equivalently guiding different frame generations without frame-specific textual guidance. Thus, the model's capacity to comprehend the temporal logic conveyed in prompts and generate videos with coherent motion is restricted. To tackle this limitation, we introduce FancyVideo, an innovative video generator that improves the existing text-control mechanism with the well-designed Cross-frame Textual Guidance Module (CTGM). Specifically, CTGM incorporates the Temporal Information Injector (TII), Temporal Affinity Refiner (TAR), and Temporal Feature Booster (TFB) at the beginning, middle, and end of cross-attention, respectively, to achieve frame-specific textual guidance. Firstly, TII injects frame-specific information from latent features into text conditions, thereby obtaining cross-frame textual conditions. Then, TAR refines the correlation matrix between cross-frame textual conditions and latent features along the time dimension. Lastly, TFB boosts the temporal consistency of latent features. Extensive experiments comprising both quantitative and qualitative evaluations demonstrate the effectiveness of FancyVideo. Our approach achieves state-of-the-art T2V generation results on the EvalCrafter benchmark and facilitates the synthesis of dynamic and consistent videos. The video show results can be available at https://fancyvideo.github.io/, and we will make our code and model weights publicly available.