 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTA-Flux: Integrating Chinese Cultural Semantics into High-Quality English Text-to-Image Communities
Aug 20, 2025We proposed the Chinese Text Adapter-Flux (CTA-Flux). An adaptation method fits the Chinese text inputs to Flux, a powerful text-to-image (TTI) generative model initially trained on the English corpus. Despite the notable image generation ability conditioned on English text inputs, Flux performs poorly when processing non-English prompts, particularly due to linguistic and cultural biases inherent in predominantly English-centric training datasets. Existing approaches, such as translating non-English prompts into English or finetuning models for bilingual mappings, inadequately address culturally specific semantics, compromising image authenticity and quality. To address this issue, we introduce a novel method to bridge Chinese semantic understanding with compatibility in English-centric TTI model communities. Existing approaches relying on ControlNet-like architectures typically require a massive parameter scale and lack direct control over Chinese semantics. In comparison, CTA-flux leverages MultiModal Diffusion Transformer (MMDiT) to control the Flux backbone directly, significantly reducing the number of parameters while enhancing the model's understanding of Chinese semantics. This integration significantly improves the generation quality and cultural authenticity without extensive retraining of the entire model, thus maintaining compatibility with existing text-to-image plugins such as LoRA, IP-Adapter, and ControlNet. Empirical evaluations demonstrate that CTA-flux supports Chinese and English prompts and achieves superior image generation quality, visual realism, and faithful depiction of Chinese semantics.
NanoControl: A Lightweight Framework for Precise and Efficient Control in Diffusion Transformer
Aug 14, 2025Diffusion Transformers (DiTs) have demonstrated exceptional capabilities in text-to-image synthesis. However, in the domain of controllable text-to-image generation using DiTs, most existing methods still rely on the ControlNet paradigm originally designed for UNet-based diffusion models. This paradigm introduces significant parameter overhead and increased computational costs. To address these challenges, we propose the Nano Control Diffusion Transformer (NanoControl), which employs Flux as the backbone network. Our model achieves state-of-the-art controllable text-to-image generation performance while incurring only a 0.024\% increase in parameter count and a 0.029\% increase in GFLOPs, thus enabling highly efficient controllable generation. Specifically, rather than duplicating the DiT backbone for control, we design a LoRA-style (low-rank adaptation) control module that directly learns control signals from raw conditioning inputs. Furthermore, we introduce a KV-Context Augmentation mechanism that integrates condition-specific key-value information into the backbone in a simple yet highly effective manner, facilitating deep fusion of conditional features. Extensive benchmark experiments demonstrate that NanoControl significantly reduces computational overhead compared to conventional control approaches, while maintaining superior generation quality and achieving improved controllability.
FLUX-Makeup: High-Fidelity, Identity-Consistent, and Robust Makeup Transfer via Diffusion Transformer
Aug 07, 2025
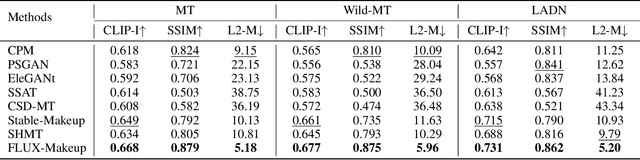
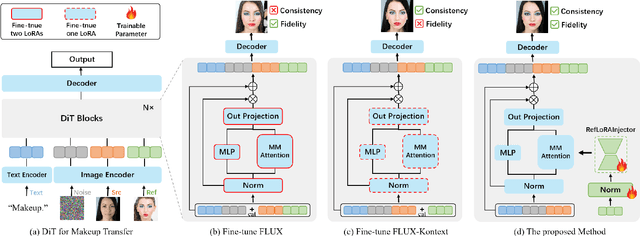
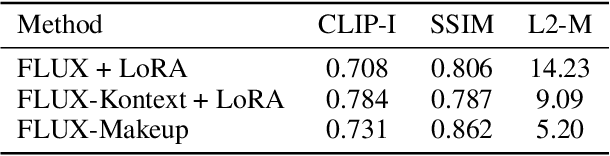
Makeup transfer aims to apply the makeup style from a reference face to a target face and has been increasingly adopted in practical applications. Existing GAN-based approaches typically rely on carefully designed loss functions to balance transfer quality and facial identity consistency, while diffusion-based methods often depend on additional face-control modules or algorithms to preserve identity. However, these auxiliary components tend to introduce extra errors, leading to suboptimal transfer results. To overcome these limitations, we propose FLUX-Makeup, a high-fidelity, identity-consistent, and robust makeup transfer framework that eliminates the need for any auxiliary face-control components. Instead, our method directly leverages source-reference image pairs to achieve superior transfer performance. Specifically, we build our framework upon FLUX-Kontext, using the source image as its native conditional input. Furthermore, we introduce RefLoRAInjector, a lightweight makeup feature injector that decouples the reference pathway from the backbone, enabling efficient and comprehensive extraction of makeup-related information. In parallel, we design a robust and scalable data generation pipeline to provide more accurate supervision during training. The paired makeup datasets produced by this pipeline significantly surpass the quality of all existing datasets. Extensive experiments demonstrate that FLUX-Makeup achieves state-of-the-art performance, exhibiting strong robustness across diverse scenarios.
PlanGen: Towards Unified Layout Planning and Image Generation in Auto-Regressive Vision Language Models
Mar 13, 2025In this paper, we propose a unified layout planning and image generation model, PlanGen, which can pre-plan spatial layout conditions before generating images. Unlike previous diffusion-based models that treat layout planning and layout-to-image as two separate models, PlanGen jointly models the two tasks into one autoregressive transformer using only next-token prediction. PlanGen integrates layout conditions into the model as context without requiring specialized encoding of local captions and bounding box coordinates, which provides significant advantages over the previous embed-and-pool operations on layout conditions, particularly when dealing with complex layouts. Unified prompting allows PlanGen to perform multitasking training related to layout, including layout planning, layout-to-image generation, image layout understanding, etc. In addition, PlanGen can be seamlessly expanded to layout-guided image manipulation thanks to the well-designed modeling, with teacher-forcing content manipulation policy and negative layout guidance. Extensive experiments verify the effectiveness of our PlanGen in multiple layoutrelated tasks, showing its great potential. Code is available at: https://360cvgroup.github.io/PlanGen.
NAMI: Efficient Image Generation via Progressive Rectified Flow Transformers
Mar 12, 2025Flow-based transformer models for image generation have achieved state-of-the-art performance with larger model parameters, but their inference deployment cost remains high. To enhance inference performance while maintaining generation quality, we propose progressive rectified flow transformers. We divide the rectified flow into different stages according to resolution, using fewer transformer layers at the low-resolution stages to generate image layouts and concept contours, and progressively adding more layers as the resolution increases. Experiments demonstrate that our approach achieves fast convergence and reduces inference time while ensuring generation quality. The main contributions of this paper are summarized as follows: (1) We introduce progressive rectified flow transformers that enable multi-resolution training, accelerating model convergence; (2) NAMI leverages piecewise flow and spatial cascading of Diffusion Transformer (DiT) to rapidly generate images, reducing inference time by 40% to generate a 1024 resolution image; (3) We propose NAMI-1K benchmark to evaluate human preference performance, aiming to mitigate distributional bias and prevent data leakage from open-source benchmarks. The results show that our model is competitive with state-of-the-art models.
WISA: World Simulator Assistant for Physics-Aware Text-to-Video Generation
Mar 11, 2025Recent rapid advancements in text-to-video (T2V) generation, such as SoRA and Kling, have shown great potential for building world simulators. However, current T2V models struggle to grasp abstract physical principles and generate videos that adhere to physical laws. This challenge arises primarily from a lack of clear guidance on physical information due to a significant gap between abstract physical principles and generation models. To this end, we introduce the World Simulator Assistant (WISA), an effective framework for decomposing and incorporating physical principles into T2V models. Specifically, WISA decomposes physical principles into textual physical descriptions, qualitative physical categories, and quantitative physical properties. To effectively embed these physical attributes into the generation process, WISA incorporates several key designs, including Mixture-of-Physical-Experts Attention (MoPA) and a Physical Classifier, enhancing the model's physics awareness. Furthermore, most existing datasets feature videos where physical phenomena are either weakly represented or entangled with multiple co-occurring processes, limiting their suitability as dedicated resources for learning explicit physical principles. We propose a novel video dataset, WISA-32K, collected based on qualitative physical categories. It consists of 32,000 videos, representing 17 physical laws across three domains of physics: dynamics, thermodynamics, and optics. Experimental results demonstrate that WISA can effectively enhance the compatibility of T2V models with real-world physical laws, achieving a considerable improvement on the VideoPhy benchmark. The visual exhibitions of WISA and WISA-32K are available in the https://360cvgroup.github.io/WISA/.
U-StyDiT: Ultra-high Quality Artistic Style Transfer Using Diffusion Transformers
Mar 11, 2025Ultra-high quality artistic style transfer refers to repainting an ultra-high quality content image using the style information learned from the style image. Existing artistic style transfer methods can be categorized into style reconstruction-based and content-style disentanglement-based style transfer approaches. Although these methods can generate some artistic stylized images, they still exhibit obvious artifacts and disharmonious patterns, which hinder their ability to produce ultra-high quality artistic stylized images. To address these issues, we propose a novel artistic image style transfer method, U-StyDiT, which is built on transformer-based diffusion (DiT) and learns content-style disentanglement, generating ultra-high quality artistic stylized images. Specifically, we first design a Multi-view Style Modulator (MSM) to learn style information from a style image from local and global perspectives, conditioning U-StyDiT to generate stylized images with the learned style information. Then, we introduce a StyDiT Block to learn content and style conditions simultaneously from a style image. Additionally, we propose an ultra-high quality artistic image dataset, Aes4M, comprising 10 categories, each containing 400,000 style images. This dataset effectively solves the problem that the existing style transfer methods cannot produce high-quality artistic stylized images due to the size of the dataset and the quality of the images in the dataset. Finally, the extensive qualitative and quantitative experiments validate that our U-StyDiT can create higher quality stylized images compared to state-of-the-art artistic style transfer methods. To our knowledge, our proposed method is the first to address the generation of ultra-high quality stylized images using transformer-based diffusion.
RelaCtrl: Relevance-Guided Efficient Control for Diffusion Transformers
Feb 21, 2025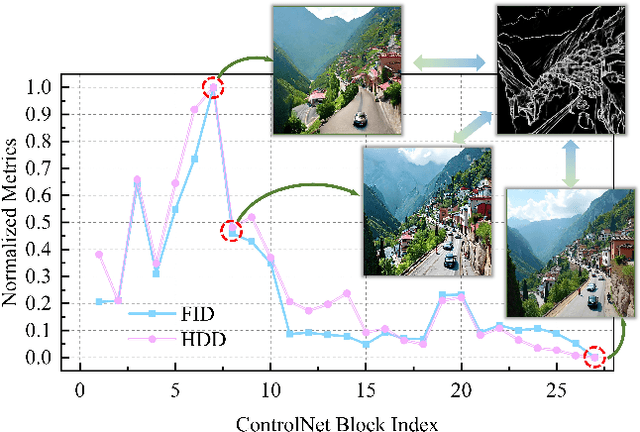
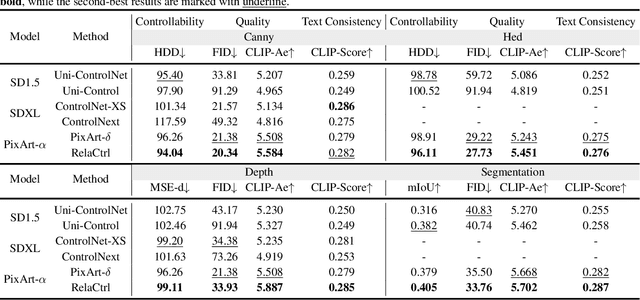
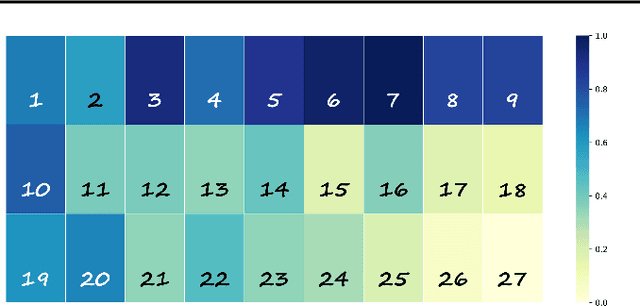
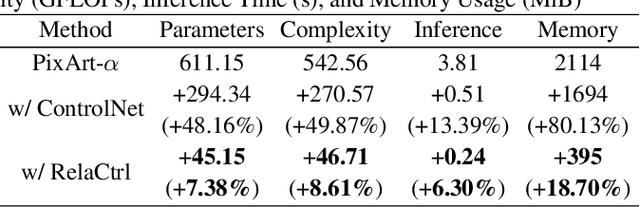
The Diffusion Transformer plays a pivotal role in advancing text-to-image and text-to-video generation, owing primarily to its inherent scalability. However, existing controlled diffusion transformer methods incur significant parameter and computational overheads and suffer from inefficient resource allocation due to their failure to account for the varying relevance of control information across different transformer layers. To address this, we propose the Relevance-Guided Efficient Controllable Generation framework, RelaCtrl, enabling efficient and resource-optimized integration of control signals into the Diffusion Transformer. First, we evaluate the relevance of each layer in the Diffusion Transformer to the control information by assessing the "ControlNet Relevance Score"-i.e., the impact of skipping each control layer on both the quality of generation and the control effectiveness during inference. Based on the strength of the relevance, we then tailor the positioning, parameter scale, and modeling capacity of the control layers to reduce unnecessary parameters and redundant computations. Additionally, to further improve efficiency, we replace the self-attention and FFN in the commonly used copy block with the carefully designed Two-Dimensional Shuffle Mixer (TDSM), enabling efficient implementation of both the token mixer and channel mixer. Both qualitative and quantitative experimental results demonstrate that our approach achieves superior performance with only 15% of the parameters and computational complexity compared to PixArt-delta.
HiCo: Hierarchical Controllable Diffusion Model for Layout-to-image Generation
Oct 18, 2024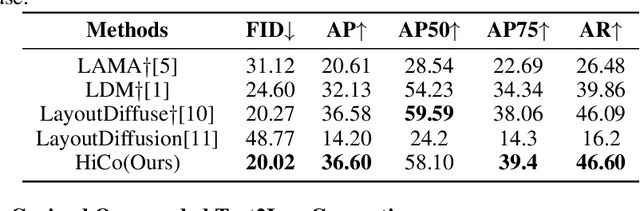

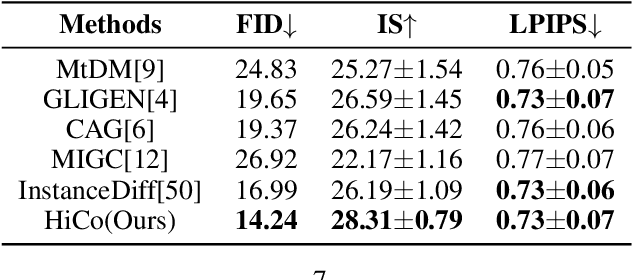
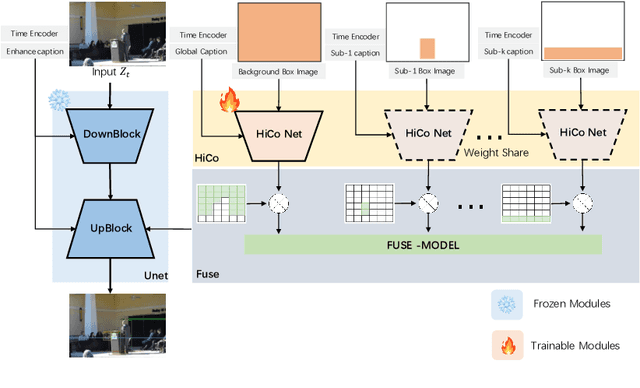
The task of layout-to-image generation involves synthesizing images based on the captions of objects and their spatial positions. Existing methods still struggle in complex layout generation, where common bad cases include object missing, inconsistent lighting, conflicting view angles, etc. To effectively address these issues, we propose a \textbf{Hi}erarchical \textbf{Co}ntrollable (HiCo) diffusion model for layout-to-image generation, featuring object seperable conditioning branch structure. Our key insight is to achieve spatial disentanglement through hierarchical modeling of layouts. We use a multi branch structure to represent hierarchy and aggregate them in fusion module. To evaluate the performance of multi-objective controllable layout generation in natural scenes, we introduce the HiCo-7K benchmark, derived from the GRIT-20M dataset and manually cleaned. https://github.com/360CVGroup/HiCo_T2I.
Bridge Diffusion Model: bridge non-English language-native text-to-image diffusion model with English communities
Sep 02, 2023Text-to-Image generation (TTI) technologies are advancing rapidly, especially in the English language communities. However, English-native TTI models inherently carry biases from English world centric training data, which creates a dilemma for development of other language-native TTI models. One common choice is fine-tuning the English-native TTI model with translated samples from non-English communities. It falls short of fully addressing the model bias problem. Alternatively, training non-English language native models from scratch can effectively resolve the English world bias, but diverges from the English TTI communities, thus not able to utilize the strides continuously gaining in the English TTI communities any more. To build non-English language native TTI model meanwhile keep compatability with the English TTI communities, we propose a novel model structure referred as "Bridge Diffusion Model" (BDM). The proposed BDM employs a backbone-branch network structure to learn the non-English language semantics while keep the latent space compatible with the English-native TTI backbone, in an end-to-end manner. The unique advantages of the proposed BDM are that it's not only adept at generating images that precisely depict non-English language semantics, but also compatible with various English-native TTI plugins, such as different checkpoints, LoRA, ControlNet, Dreambooth, and Textual Inversion, etc. Moreover, BDM can concurrently generate content seamlessly combining both non-English native and English-native semantics within a single image, fostering cultural interaction. We verify our method by applying BDM to build a Chinese-native TTI model, whereas the method is generic and applicable to any other language.