 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealLayer: Disentangling Hidden and Visible Layers via Occlusion-Aware Image Decomposition
May 12, 2026Recent diffusion-based approaches have made substantial progress in image layer decomposition. However, accurately decomposing complex natural images remains challenging due to difficulties in occlusion completion, robust layer disentanglement, and precise foreground boundaries. Moreover, the scarcity of high-quality multi-layer natural image datasets limits advancement. To address these challenges, we propose RevealLayer, a diffusion-based framework that decomposes an RGB image into multiple RGBA layers, enabling precise layer separation and reliable recovery of occluded content in natural images. RevealLayer incorporates three key components: (1) a Region-Aware Attention module to disentangle hidden and visible layers; (2) an Occlusion-Guided Adapter to leverage contextual information to enhance overlapping regions; and (3) a composite loss to enforce sharp alpha boundaries and suppress residual artifacts. To support training and evaluation, we introduce RevealLayer-100K, a high-quality multi-layer natural image constructed through a collaboration between automated algorithms and human annotation, and further establish RevealLayerBench for benchmarking layer decomposition in general natural scenes. Extensive experiments demonstrate that RevealLayer consistently outperforms existing approaches in layer decomposition.
RPiAE: A Representation-Pivoted Autoencoder Enhancing Both Image Generation and Editing
Mar 19, 2026Diffusion models have become the dominant paradigm for image generation and editing, with latent diffusion models shifting denoising to a compact latent space for efficiency and scalability. Recent attempts to leverage pretrained visual representation models as tokenizer priors either align diffusion features to representation features or directly reuse representation encoders as frozen tokenizers. Although such approaches can improve generation metrics, they often suffer from limited reconstruction fidelity due to frozen encoders, which in turn degrades editing quality, as well as overly high-dimensional latents that make diffusion modeling difficult. To address these limitations, We propose Representation-Pivoted AutoEncoder, a representation-based tokenizer that improves both generation and editing. We introduce Representation-Pivot Regularization, a training strategy that enables a representation-initialized encoder to be fine-tuned for reconstruction while preserving the semantic structure of the pretrained representation space, followed by a variational bridge which compress latent space into a compact one for better diffusion modeling. We adopt an objective-decoupled stage-wise training strategy that sequentially optimizes generative tractability and reconstruction-fidelity objectives. Together, these components yield a tokenizer that preserves strong semantics, reconstructs faithfully, and produces latents with reduced diffusion modeling complexity. Experiments demonstrate that RPiAE outperforms other visual tokenizers on text-to-image generation and image editing, while delivering the best reconstruction fidelity among representation-based tokenizers.
AMLRIS: Alignment-aware Masked Learning for Referring Image Segmentation
Feb 26, 2026Referring Image Segmentation (RIS) aims to segment an object in an image identified by a natural language expression. The paper introduces Alignment-Aware Masked Learning (AML), a training strategy to enhance RIS by explicitly estimating pixel-level vision-language alignment, filtering out poorly aligned regions during optimization, and focusing on trustworthy cues. This approach results in state-of-the-art performance on RefCOCO datasets and also enhances robustness to diverse descriptions and scenarios
Generation-Augmented Generation: A Plug-and-Play Framework for Private Knowledge Injection in Large Language Models
Jan 13, 2026In domains such as biomedicine, materials, and finance, high-stakes deployment of large language models (LLMs) requires injecting private, domain-specific knowledge that is proprietary, fast-evolving, and under-represented in public pretraining. However, the two dominant paradigms for private knowledge injection each have pronounced drawbacks: fine-tuning is expensive to iterate, and continual updates risk catastrophic forgetting and general-capability regression; retrieval-augmented generation (RAG) keeps the base model intact but is brittle in specialized private corpora due to chunk-induced evidence fragmentation, retrieval drift, and long-context pressure that yields query-dependent prompt inflation. Inspired by how multimodal LLMs align heterogeneous modalities into a shared semantic space, we propose Generation-Augmented Generation (GAG), which treats private expertise as an additional expert modality and injects it via a compact, representation-level interface aligned to the frozen base model, avoiding prompt-time evidence serialization while enabling plug-and-play specialization and scalable multi-domain composition with reliable selective activation. Across two private scientific QA benchmarks (immunology adjuvant and catalytic materials) and mixed-domain evaluations, GAG improves specialist performance over strong RAG baselines by 15.34% and 14.86% on the two benchmarks, respectively, while maintaining performance on six open general benchmarks and enabling near-oracle selective activation for scalable multi-domain deployment.
RzenEmbed: Towards Comprehensive Multimodal Retrieval
Oct 31, 2025The rapid advancement of Multimodal Large Language Models (MLLMs) has extended CLIP-based frameworks to produce powerful, universal embeddings for retrieval tasks. However, existing methods primarily focus on natural images, offering limited support for other crucial visual modalities such as videos and visual documents. To bridge this gap, we introduce RzenEmbed, a unified framework to learn embeddings across a diverse set of modalities, including text, images, videos, and visual documents. We employ a novel two-stage training strategy to learn discriminative representations. The first stage focuses on foundational text and multimodal retrieval. In the second stage, we introduce an improved InfoNCE loss, incorporating two key enhancements. Firstly, a hardness-weighted mechanism guides the model to prioritize challenging samples by assigning them higher weights within each batch. Secondly, we implement an approach to mitigate the impact of false negatives and alleviate data noise. This strategy not only enhances the model's discriminative power but also improves its instruction-following capabilities. We further boost performance with learnable temperature parameter and model souping. RzenEmbed sets a new state-of-the-art on the MMEB benchmark. It not only achieves the best overall score but also outperforms all prior work on the challenging video and visual document retrieval tasks. Our models are available in https://huggingface.co/qihoo360/RzenEmbed.
CTA-Flux: Integrating Chinese Cultural Semantics into High-Quality English Text-to-Image Communities
Aug 20, 2025We proposed the Chinese Text Adapter-Flux (CTA-Flux). An adaptation method fits the Chinese text inputs to Flux, a powerful text-to-image (TTI) generative model initially trained on the English corpus. Despite the notable image generation ability conditioned on English text inputs, Flux performs poorly when processing non-English prompts, particularly due to linguistic and cultural biases inherent in predominantly English-centric training datasets. Existing approaches, such as translating non-English prompts into English or finetuning models for bilingual mappings, inadequately address culturally specific semantics, compromising image authenticity and quality. To address this issue, we introduce a novel method to bridge Chinese semantic understanding with compatibility in English-centric TTI model communities. Existing approaches relying on ControlNet-like architectures typically require a massive parameter scale and lack direct control over Chinese semantics. In comparison, CTA-flux leverages MultiModal Diffusion Transformer (MMDiT) to control the Flux backbone directly, significantly reducing the number of parameters while enhancing the model's understanding of Chinese semantics. This integration significantly improves the generation quality and cultural authenticity without extensive retraining of the entire model, thus maintaining compatibility with existing text-to-image plugins such as LoRA, IP-Adapter, and ControlNet. Empirical evaluations demonstrate that CTA-flux supports Chinese and English prompts and achieves superior image generation quality, visual realism, and faithful depiction of Chinese semantics.
NanoControl: A Lightweight Framework for Precise and Efficient Control in Diffusion Transformer
Aug 14, 2025Diffusion Transformers (DiTs) have demonstrated exceptional capabilities in text-to-image synthesis. However, in the domain of controllable text-to-image generation using DiTs, most existing methods still rely on the ControlNet paradigm originally designed for UNet-based diffusion models. This paradigm introduces significant parameter overhead and increased computational costs. To address these challenges, we propose the Nano Control Diffusion Transformer (NanoControl), which employs Flux as the backbone network. Our model achieves state-of-the-art controllable text-to-image generation performance while incurring only a 0.024\% increase in parameter count and a 0.029\% increase in GFLOPs, thus enabling highly efficient controllable generation. Specifically, rather than duplicating the DiT backbone for control, we design a LoRA-style (low-rank adaptation) control module that directly learns control signals from raw conditioning inputs. Furthermore, we introduce a KV-Context Augmentation mechanism that integrates condition-specific key-value information into the backbone in a simple yet highly effective manner, facilitating deep fusion of conditional features. Extensive benchmark experiments demonstrate that NanoControl significantly reduces computational overhead compared to conventional control approaches, while maintaining superior generation quality and achieving improved controllability.
FLUX-Makeup: High-Fidelity, Identity-Consistent, and Robust Makeup Transfer via Diffusion Transformer
Aug 07, 2025
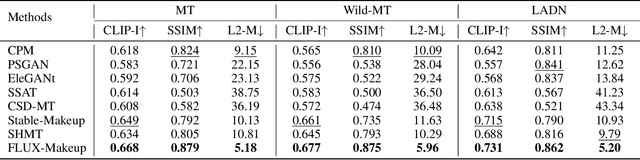
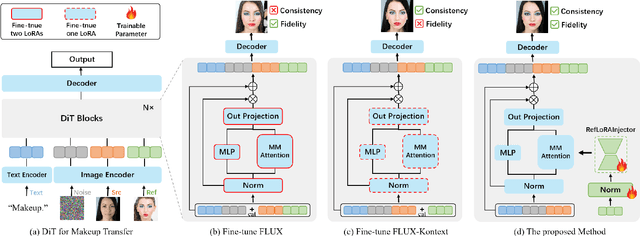
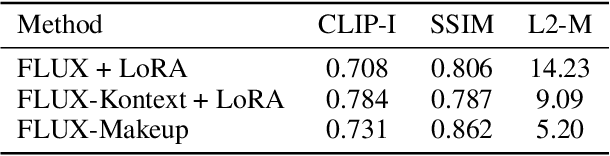
Makeup transfer aims to apply the makeup style from a reference face to a target face and has been increasingly adopted in practical applications. Existing GAN-based approaches typically rely on carefully designed loss functions to balance transfer quality and facial identity consistency, while diffusion-based methods often depend on additional face-control modules or algorithms to preserve identity. However, these auxiliary components tend to introduce extra errors, leading to suboptimal transfer results. To overcome these limitations, we propose FLUX-Makeup, a high-fidelity, identity-consistent, and robust makeup transfer framework that eliminates the need for any auxiliary face-control components. Instead, our method directly leverages source-reference image pairs to achieve superior transfer performance. Specifically, we build our framework upon FLUX-Kontext, using the source image as its native conditional input. Furthermore, we introduce RefLoRAInjector, a lightweight makeup feature injector that decouples the reference pathway from the backbone, enabling efficient and comprehensive extraction of makeup-related information. In parallel, we design a robust and scalable data generation pipeline to provide more accurate supervision during training. The paired makeup datasets produced by this pipeline significantly surpass the quality of all existing datasets. Extensive experiments demonstrate that FLUX-Makeup achieves state-of-the-art performance, exhibiting strong robustness across diverse scenarios.
FG-CLIP: Fine-Grained Visual and Textual Alignment
May 08, 2025



Contrastive Language-Image Pre-training (CLIP) excels in multimodal tasks such as image-text retrieval and zero-shot classification but struggles with fine-grained understanding due to its focus on coarse-grained short captions. To address this, we propose Fine-Grained CLIP (FG-CLIP), which enhances fine-grained understanding through three key innovations. First, we leverage large multimodal models to generate 1.6 billion long caption-image pairs for capturing global-level semantic details. Second, a high-quality dataset is constructed with 12 million images and 40 million region-specific bounding boxes aligned with detailed captions to ensure precise, context-rich representations. Third, 10 million hard fine-grained negative samples are incorporated to improve the model's ability to distinguish subtle semantic differences. Corresponding training methods are meticulously designed for these data. Extensive experiments demonstrate that FG-CLIP outperforms the original CLIP and other state-of-the-art methods across various downstream tasks, including fine-grained understanding, open-vocabulary object detection, image-text retrieval, and general multimodal benchmarks. These results highlight FG-CLIP's effectiveness in capturing fine-grained image details and improving overall model performance. The related data, code, and models are available at https://github.com/360CVGroup/FG-CLIP.
PlanGen: Towards Unified Layout Planning and Image Generation in Auto-Regressive Vision Language Models
Mar 13, 2025In this paper, we propose a unified layout planning and image generation model, PlanGen, which can pre-plan spatial layout conditions before generating images. Unlike previous diffusion-based models that treat layout planning and layout-to-image as two separate models, PlanGen jointly models the two tasks into one autoregressive transformer using only next-token prediction. PlanGen integrates layout conditions into the model as context without requiring specialized encoding of local captions and bounding box coordinates, which provides significant advantages over the previous embed-and-pool operations on layout conditions, particularly when dealing with complex layouts. Unified prompting allows PlanGen to perform multitasking training related to layout, including layout planning, layout-to-image generation, image layout understanding, etc. In addition, PlanGen can be seamlessly expanded to layout-guided image manipulation thanks to the well-designed modeling, with teacher-forcing content manipulation policy and negative layout guidance. Extensive experiments verify the effectiveness of our PlanGen in multiple layoutrelated tasks, showing its great potential. Code is available at: https://360cvgroup.github.io/PlanGen.