 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre LLM-Enhanced Graph Neural Networks Robust against Poisoning Attacks?
Mar 27, 2026Large Language Models (LLMs) have advanced Graph Neural Networks (GNNs) by enriching node representations with semantic features, giving rise to LLM-enhanced GNNs that achieve notable performance gains. However, the robustness of these models against poisoning attacks, which manipulate both graph structures and textual attributes during training, remains unexplored. To bridge this gap, we propose a robustness assessment framework that systematically evaluates LLM-enhanced GNNs under poisoning attacks. Our framework enables comprehensive evaluation across multiple dimensions. Specifically, we assess 24 victim models by combining eight LLM- or Language Model (LM)-based feature enhancers with three representative GNN backbones. To ensure diversity in attack coverage, we incorporate six structural poisoning attacks (both targeted and non-targeted) and three textual poisoning attacks operating at the character, word, and sentence levels. Furthermore, we employ four real-world datasets, including one released after the emergence of LLMs, to avoid potential ground truth leakage during LLM pretraining, thereby ensuring fair evaluation. Extensive experiments show that LLM-enhanced GNNs exhibit significantly higher accuracy and lower Relative Drop in Accuracy (RDA) than a shallow embedding-based baseline across various attack settings. Our in-depth analysis identifies key factors that contribute to this robustness, such as the effective encoding of structural and label information in node representations. Based on these insights, we outline future research directions from both offensive and defensive perspectives, and propose a new combined attack along with a graph purification defense. To support future research, we release the source code of our framework at~\url{https://github.com/CyberAlSec/LLMEGNNRP}.
RPiAE: A Representation-Pivoted Autoencoder Enhancing Both Image Generation and Editing
Mar 19, 2026Diffusion models have become the dominant paradigm for image generation and editing, with latent diffusion models shifting denoising to a compact latent space for efficiency and scalability. Recent attempts to leverage pretrained visual representation models as tokenizer priors either align diffusion features to representation features or directly reuse representation encoders as frozen tokenizers. Although such approaches can improve generation metrics, they often suffer from limited reconstruction fidelity due to frozen encoders, which in turn degrades editing quality, as well as overly high-dimensional latents that make diffusion modeling difficult. To address these limitations, We propose Representation-Pivoted AutoEncoder, a representation-based tokenizer that improves both generation and editing. We introduce Representation-Pivot Regularization, a training strategy that enables a representation-initialized encoder to be fine-tuned for reconstruction while preserving the semantic structure of the pretrained representation space, followed by a variational bridge which compress latent space into a compact one for better diffusion modeling. We adopt an objective-decoupled stage-wise training strategy that sequentially optimizes generative tractability and reconstruction-fidelity objectives. Together, these components yield a tokenizer that preserves strong semantics, reconstructs faithfully, and produces latents with reduced diffusion modeling complexity. Experiments demonstrate that RPiAE outperforms other visual tokenizers on text-to-image generation and image editing, while delivering the best reconstruction fidelity among representation-based tokenizers.
Vector Quantized-Aided XL-MIMO CSI Feedback with Channel Adaptive Transmission
Jan 12, 2026Efficient channel state information (CSI) feedback is critical for 6G extremely large-scale multiple-input multiple-output (XL-MIMO) systems to mitigate channel interference. However, the massive antenna scale imposes a severe burden on feedback overhead. Meanwhile, existing quantized feedback methods face dual challenges of limited quantization precision and insufficient channel robustness when compressing high-dimensional channel features into discrete symbols. To reduce these gaps, guided by the deep joint source-channel coding (DJSCC) framework, we propose a vector quantized (VQ)-aided scheme for CSI feedback in XL-MIMO systems considering the near-field effect, named VQ-DJSCC-F. Firstly, taking advantage of the sparsity of near-field channels in the polar-delay domain, we extract energy-concentrated features to reduce dimensionality. Then, we simultaneously design the Transformer and CNN (convolutional neural network) architectures as the backbones to hierarchically extract CSI features, followed by VQ modules projecting features into a discrete latent space. The entropy loss regularization in synergy with an exponential moving average (EMA) update strategy is introduced to maximize quantization precision. Furthermore, we develop an attention mechanism-driven channel adaptation module to mitigate the impact of wireless channel fading on the transmission of index sequences. Simulation results demonstrate that the proposed scheme achieves superior CSI reconstruction accuracy with lower feedback overheads under varying channel conditions.
Flow matching-based generative models for MIMO channel estimation
Nov 14, 2025Diffusion model (DM)-based channel estimation, which generates channel samples via a posteriori sampling stepwise with denoising process, has shown potential in high-precision channel state information (CSI) acquisition. However, slow sampling speed is an essential challenge for recent developed DM-based schemes. To alleviate this problem, we propose a novel flow matching (FM)-based generative model for multiple-input multiple-output (MIMO) channel estimation. We first formulate the channel estimation problem within FM framework, where the conditional probability path is constructed from the noisy channel distribution to the true channel distribution. In this case, the path evolves along the straight-line trajectory at a constant speed. Then, guided by this, we derive the velocity field that depends solely on the noise statistics to guide generative models training. Furthermore, during the sampling phase, we utilize the trained velocity field as prior information for channel estimation, which allows for quick and reliable noise channel enhancement via ordinary differential equation (ODE) Euler solver. Finally, numerical results demonstrate that the proposed FM-based channel estimation scheme can significantly reduce the sampling overhead compared to other popular DM-based schemes, such as the score matching (SM)-based scheme. Meanwhile, it achieves superior channel estimation accuracy under different channel conditions.
CTA-Flux: Integrating Chinese Cultural Semantics into High-Quality English Text-to-Image Communities
Aug 20, 2025We proposed the Chinese Text Adapter-Flux (CTA-Flux). An adaptation method fits the Chinese text inputs to Flux, a powerful text-to-image (TTI) generative model initially trained on the English corpus. Despite the notable image generation ability conditioned on English text inputs, Flux performs poorly when processing non-English prompts, particularly due to linguistic and cultural biases inherent in predominantly English-centric training datasets. Existing approaches, such as translating non-English prompts into English or finetuning models for bilingual mappings, inadequately address culturally specific semantics, compromising image authenticity and quality. To address this issue, we introduce a novel method to bridge Chinese semantic understanding with compatibility in English-centric TTI model communities. Existing approaches relying on ControlNet-like architectures typically require a massive parameter scale and lack direct control over Chinese semantics. In comparison, CTA-flux leverages MultiModal Diffusion Transformer (MMDiT) to control the Flux backbone directly, significantly reducing the number of parameters while enhancing the model's understanding of Chinese semantics. This integration significantly improves the generation quality and cultural authenticity without extensive retraining of the entire model, thus maintaining compatibility with existing text-to-image plugins such as LoRA, IP-Adapter, and ControlNet. Empirical evaluations demonstrate that CTA-flux supports Chinese and English prompts and achieves superior image generation quality, visual realism, and faithful depiction of Chinese semantics.
NanoControl: A Lightweight Framework for Precise and Efficient Control in Diffusion Transformer
Aug 14, 2025Diffusion Transformers (DiTs) have demonstrated exceptional capabilities in text-to-image synthesis. However, in the domain of controllable text-to-image generation using DiTs, most existing methods still rely on the ControlNet paradigm originally designed for UNet-based diffusion models. This paradigm introduces significant parameter overhead and increased computational costs. To address these challenges, we propose the Nano Control Diffusion Transformer (NanoControl), which employs Flux as the backbone network. Our model achieves state-of-the-art controllable text-to-image generation performance while incurring only a 0.024\% increase in parameter count and a 0.029\% increase in GFLOPs, thus enabling highly efficient controllable generation. Specifically, rather than duplicating the DiT backbone for control, we design a LoRA-style (low-rank adaptation) control module that directly learns control signals from raw conditioning inputs. Furthermore, we introduce a KV-Context Augmentation mechanism that integrates condition-specific key-value information into the backbone in a simple yet highly effective manner, facilitating deep fusion of conditional features. Extensive benchmark experiments demonstrate that NanoControl significantly reduces computational overhead compared to conventional control approaches, while maintaining superior generation quality and achieving improved controllability.
FLUX-Makeup: High-Fidelity, Identity-Consistent, and Robust Makeup Transfer via Diffusion Transformer
Aug 07, 2025
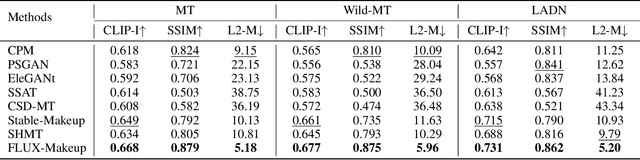
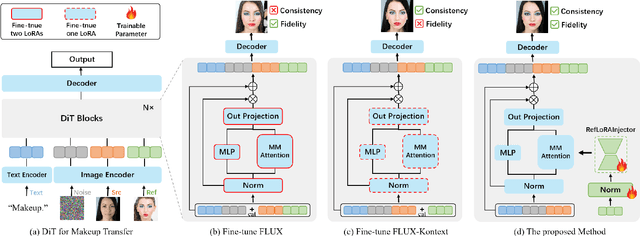
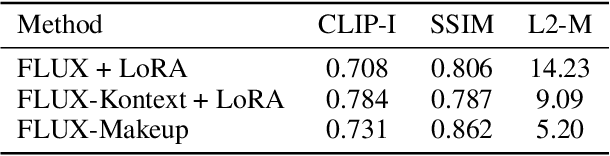
Makeup transfer aims to apply the makeup style from a reference face to a target face and has been increasingly adopted in practical applications. Existing GAN-based approaches typically rely on carefully designed loss functions to balance transfer quality and facial identity consistency, while diffusion-based methods often depend on additional face-control modules or algorithms to preserve identity. However, these auxiliary components tend to introduce extra errors, leading to suboptimal transfer results. To overcome these limitations, we propose FLUX-Makeup, a high-fidelity, identity-consistent, and robust makeup transfer framework that eliminates the need for any auxiliary face-control components. Instead, our method directly leverages source-reference image pairs to achieve superior transfer performance. Specifically, we build our framework upon FLUX-Kontext, using the source image as its native conditional input. Furthermore, we introduce RefLoRAInjector, a lightweight makeup feature injector that decouples the reference pathway from the backbone, enabling efficient and comprehensive extraction of makeup-related information. In parallel, we design a robust and scalable data generation pipeline to provide more accurate supervision during training. The paired makeup datasets produced by this pipeline significantly surpass the quality of all existing datasets. Extensive experiments demonstrate that FLUX-Makeup achieves state-of-the-art performance, exhibiting strong robustness across diverse scenarios.
A Robust Real-Time Lane Detection Method with Fog-Enhanced Feature Fusion for Foggy Conditions
Apr 08, 2025Lane detection is a critical component of Advanced Driver Assistance Systems (ADAS). Existing lane detection algorithms generally perform well under favorable weather conditions. However, their performance degrades significantly in adverse conditions, such as fog, which increases the risk of traffic accidents. This challenge is compounded by the lack of specialized datasets and methods designed for foggy environments. To address this, we introduce the FoggyLane dataset, captured in real-world foggy scenarios, and synthesize two additional datasets, FoggyCULane and FoggyTusimple, from existing popular lane detection datasets. Furthermore, we propose a robust Fog-Enhanced Network for lane detection, incorporating a Global Feature Fusion Module (GFFM) to capture global relationships in foggy images, a Kernel Feature Fusion Module (KFFM) to model the structural and positional relationships of lane instances, and a Low-level Edge Enhanced Module (LEEM) to address missing edge details in foggy conditions. Comprehensive experiments demonstrate that our method achieves state-of-the-art performance, with F1-scores of 95.04 on FoggyLane, 79.85 on FoggyCULane, and 96.95 on FoggyTusimple. Additionally, with TensorRT acceleration, the method reaches a processing speed of 38.4 FPS on the NVIDIA Jetson AGX Orin, confirming its real-time capabilities and robustness in foggy environments.
YOLO-LLTS: Real-Time Low-Light Traffic Sign Detection via Prior-Guided Enhancement and Multi-Branch Feature Interaction
Mar 18, 2025Detecting traffic signs effectively under low-light conditions remains a significant challenge. To address this issue, we propose YOLO-LLTS, an end-to-end real-time traffic sign detection algorithm specifically designed for low-light environments. Firstly, we introduce the High-Resolution Feature Map for Small Object Detection (HRFM-TOD) module to address indistinct small-object features in low-light scenarios. By leveraging high-resolution feature maps, HRFM-TOD effectively mitigates the feature dilution problem encountered in conventional PANet frameworks, thereby enhancing both detection accuracy and inference speed. Secondly, we develop the Multi-branch Feature Interaction Attention (MFIA) module, which facilitates deep feature interaction across multiple receptive fields in both channel and spatial dimensions, significantly improving the model's information extraction capabilities. Finally, we propose the Prior-Guided Enhancement Module (PGFE) to tackle common image quality challenges in low-light environments, such as noise, low contrast, and blurriness. This module employs prior knowledge to enrich image details and enhance visibility, substantially boosting detection performance. To support this research, we construct a novel dataset, the Chinese Nighttime Traffic Sign Sample Set (CNTSSS), covering diverse nighttime scenarios, including urban, highway, and rural environments under varying weather conditions. Experimental evaluations demonstrate that YOLO-LLTS achieves state-of-the-art performance, outperforming the previous best methods by 2.7% mAP50 and 1.6% mAP50:95 on TT100K-night, 1.3% mAP50 and 1.9% mAP50:95 on CNTSSS, and achieving superior results on the CCTSDB2021 dataset. Moreover, deployment experiments on edge devices confirm the real-time applicability and effectiveness of our proposed approach.
PlanGen: Towards Unified Layout Planning and Image Generation in Auto-Regressive Vision Language Models
Mar 13, 2025In this paper, we propose a unified layout planning and image generation model, PlanGen, which can pre-plan spatial layout conditions before generating images. Unlike previous diffusion-based models that treat layout planning and layout-to-image as two separate models, PlanGen jointly models the two tasks into one autoregressive transformer using only next-token prediction. PlanGen integrates layout conditions into the model as context without requiring specialized encoding of local captions and bounding box coordinates, which provides significant advantages over the previous embed-and-pool operations on layout conditions, particularly when dealing with complex layouts. Unified prompting allows PlanGen to perform multitasking training related to layout, including layout planning, layout-to-image generation, image layout understanding, etc. In addition, PlanGen can be seamlessly expanded to layout-guided image manipulation thanks to the well-designed modeling, with teacher-forcing content manipulation policy and negative layout guidance. Extensive experiments verify the effectiveness of our PlanGen in multiple layoutrelated tasks, showing its great potential. Code is available at: https://360cvgroup.github.io/PlanGen.