 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStorynizor: Consistent Story Generation via Inter-Frame Synchronized and Shuffled ID Injection
Sep 29, 2024

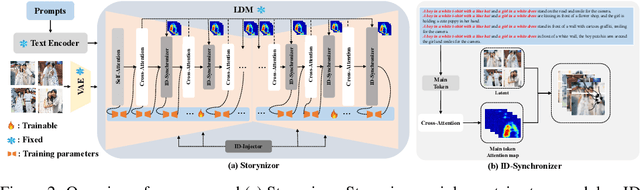
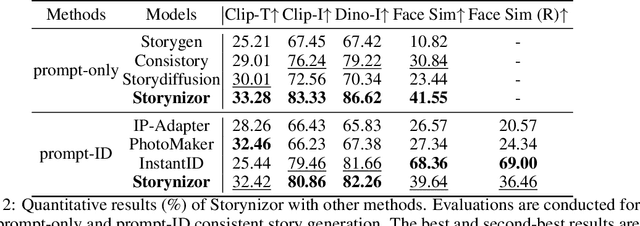
Recent advances in text-to-image diffusion models have spurred significant interest in continuous story image generation. In this paper, we introduce Storynizor, a model capable of generating coherent stories with strong inter-frame character consistency, effective foreground-background separation, and diverse pose variation. The core innovation of Storynizor lies in its key modules: ID-Synchronizer and ID-Injector. The ID-Synchronizer employs an auto-mask self-attention module and a mask perceptual loss across inter-frame images to improve the consistency of character generation, vividly representing their postures and backgrounds. The ID-Injector utilize a Shuffling Reference Strategy (SRS) to integrate ID features into specific locations, enhancing ID-based consistent character generation. Additionally, to facilitate the training of Storynizor, we have curated a novel dataset called StoryDB comprising 100, 000 images. This dataset contains single and multiple-character sets in diverse environments, layouts, and gestures with detailed descriptions. Experimental results indicate that Storynizor demonstrates superior coherent story generation with high-fidelity character consistency, flexible postures, and vivid backgrounds compared to other character-specific methods.
Towards Efficient Diffusion-Based Image Editing with Instant Attention Masks
Jan 23, 2024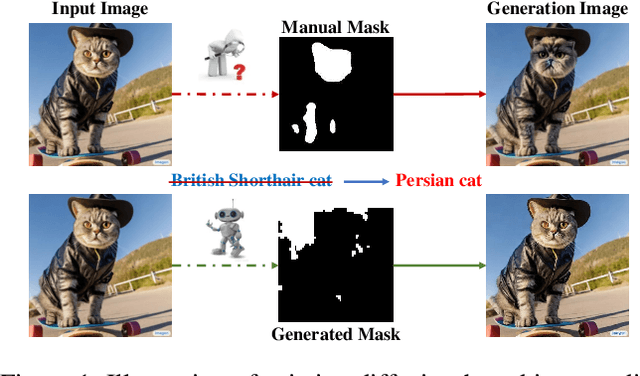
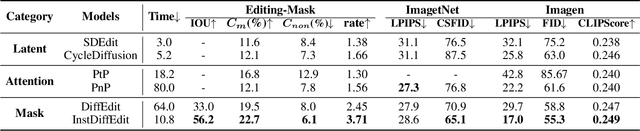

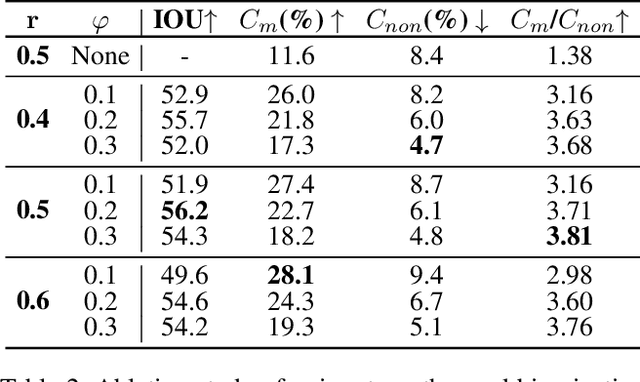
Diffusion-based Image Editing (DIE) is an emerging research hot-spot, which often applies a semantic mask to control the target area for diffusion-based editing. However, most existing solutions obtain these masks via manual operations or off-line processing, greatly reducing their efficiency. In this paper, we propose a novel and efficient image editing method for Text-to-Image (T2I) diffusion models, termed Instant Diffusion Editing(InstDiffEdit). In particular, InstDiffEdit aims to employ the cross-modal attention ability of existing diffusion models to achieve instant mask guidance during the diffusion steps. To reduce the noise of attention maps and realize the full automatics, we equip InstDiffEdit with a training-free refinement scheme to adaptively aggregate the attention distributions for the automatic yet accurate mask generation. Meanwhile, to supplement the existing evaluations of DIE, we propose a new benchmark called Editing-Mask to examine the mask accuracy and local editing ability of existing methods. To validate InstDiffEdit, we also conduct extensive experiments on ImageNet and Imagen, and compare it with a bunch of the SOTA methods. The experimental results show that InstDiffEdit not only outperforms the SOTA methods in both image quality and editing results, but also has a much faster inference speed, i.e., +5 to +6 times.
EfficientDreamer: High-Fidelity and Robust 3D Creation via Orthogonal-view Diffusion Prior
Aug 25, 2023



While the image diffusion model has made significant strides in text-driven 3D content creation, it often falls short in accurately capturing the intended meaning of the text prompt, particularly with respect to direction information. This shortcoming gives rise to the Janus problem, where multi-faced 3D models are produced with the guidance of such diffusion models. In this paper, we present a robust pipeline for generating high-fidelity 3D content with orthogonal-view image guidance. Specifically, we introduce a novel 2D diffusion model that generates an image consisting of four orthogonal-view sub-images for the given text prompt. The 3D content is then created with this diffusion model, which enhances 3D consistency and provides strong structured semantic priors. This addresses the infamous Janus problem and significantly promotes generation efficiency. Additionally, we employ a progressive 3D synthesis strategy that results in substantial improvement in the quality of the created 3D contents. Both quantitative and qualitative evaluations show that our method demonstrates a significant improvement over previous text-to-3D techniques.
On Consistency of Signatures Using Lasso
May 24, 2023Signature transforms are iterated path integrals of continuous and discrete-time time series data, and their universal nonlinearity linearizes the problem of feature selection. This paper revisits the consistency issue of Lasso regression for the signature transform, both theoretically and numerically. Our study shows that, for processes and time series that are closer to Brownian motion or random walk with weaker inter-dimensional correlations, the Lasso regression is more consistent for their signatures defined by It\^o integrals; for mean reverting processes and time series, their signatures defined by Stratonovich integrals have more consistency in the Lasso regression. Our findings highlight the importance of choosing appropriate definitions of signatures and stochastic models in statistical inference and machine learning.
The Success of AdaBoost and Its Application in Portfolio Management
Mar 23, 2021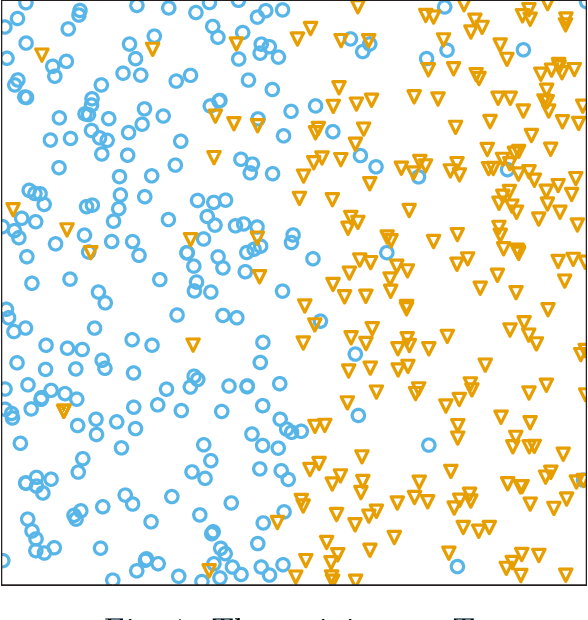



We develop a novel approach to explain why AdaBoost is a successful classifier. By introducing a measure of the influence of the noise points (ION) in the training data for the binary classification problem, we prove that there is a strong connection between the ION and the test error. We further identify that the ION of AdaBoost decreases as the iteration number or the complexity of the base learners increases. We confirm that it is impossible to obtain a consistent classifier without deep trees as the base learners of AdaBoost in some complicated situations. We apply AdaBoost in portfolio management via empirical studies in the Chinese market, which corroborates our theoretical propositions.