 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStorynizor: Consistent Story Generation via Inter-Frame Synchronized and Shuffled ID Injection
Sep 29, 2024

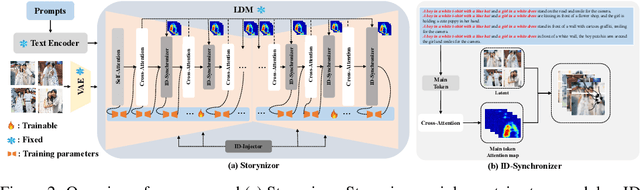
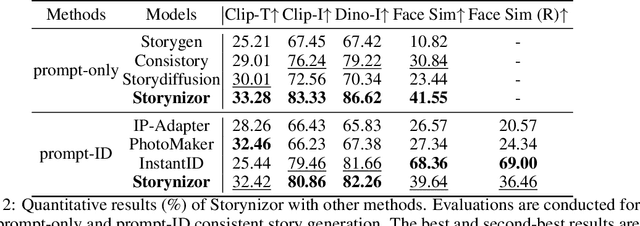
Recent advances in text-to-image diffusion models have spurred significant interest in continuous story image generation. In this paper, we introduce Storynizor, a model capable of generating coherent stories with strong inter-frame character consistency, effective foreground-background separation, and diverse pose variation. The core innovation of Storynizor lies in its key modules: ID-Synchronizer and ID-Injector. The ID-Synchronizer employs an auto-mask self-attention module and a mask perceptual loss across inter-frame images to improve the consistency of character generation, vividly representing their postures and backgrounds. The ID-Injector utilize a Shuffling Reference Strategy (SRS) to integrate ID features into specific locations, enhancing ID-based consistent character generation. Additionally, to facilitate the training of Storynizor, we have curated a novel dataset called StoryDB comprising 100, 000 images. This dataset contains single and multiple-character sets in diverse environments, layouts, and gestures with detailed descriptions. Experimental results indicate that Storynizor demonstrates superior coherent story generation with high-fidelity character consistency, flexible postures, and vivid backgrounds compared to other character-specific methods.
LLM4GEN: Leveraging Semantic Representation of LLMs for Text-to-Image Generation
Jun 30, 2024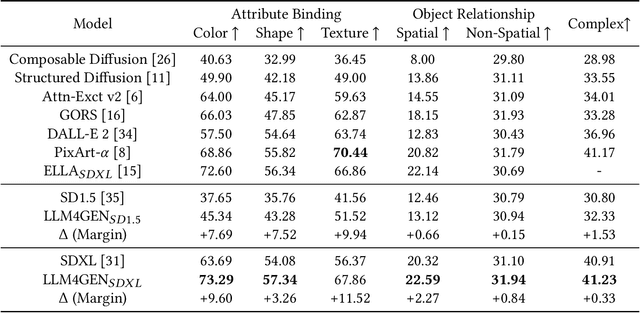
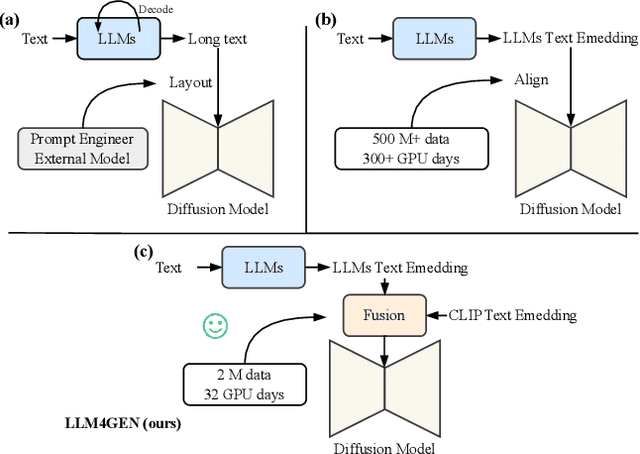


Diffusion Models have exhibited substantial success in text-to-image generation. However, they often encounter challenges when dealing with complex and dense prompts that involve multiple objects, attribute binding, and long descriptions. This paper proposes a framework called \textbf{LLM4GEN}, which enhances the semantic understanding ability of text-to-image diffusion models by leveraging the semantic representation of Large Language Models (LLMs). Through a specially designed Cross-Adapter Module (CAM) that combines the original text features of text-to-image models with LLM features, LLM4GEN can be easily incorporated into various diffusion models as a plug-and-play component and enhances text-to-image generation. Additionally, to facilitate the complex and dense prompts semantic understanding, we develop a LAION-refined dataset, consisting of 1 million (M) text-image pairs with improved image descriptions. We also introduce DensePrompts which contains 7,000 dense prompts to provide a comprehensive evaluation for the text-to-image generation task. With just 10\% of the training data required by recent ELLA, LLM4GEN significantly improves the semantic alignment of SD1.5 and SDXL, demonstrating increases of 7.69\% and 9.60\% in color on T2I-CompBench, respectively. The extensive experiments on DensePrompts also demonstrate that LLM4GEN surpasses existing state-of-the-art models in terms of sample quality, image-text alignment, and human evaluation. The project website is at: \textcolor{magenta}{\url{https://xiaobul.github.io/LLM4GEN/}}
Character-Adapter: Prompt-Guided Region Control for High-Fidelity Character Customization
Jun 24, 2024



Customized image generation, which seeks to synthesize images with consistent characters, holds significant relevance for applications such as storytelling, portrait generation, and character design. However, previous approaches have encountered challenges in preserving characters with high-fidelity consistency due to inadequate feature extraction and concept confusion of reference characters. Therefore, we propose Character-Adapter, a plug-and-play framework designed to generate images that preserve the details of reference characters, ensuring high-fidelity consistency. Character-Adapter employs prompt-guided segmentation to ensure fine-grained regional features of reference characters and dynamic region-level adapters to mitigate concept confusion. Extensive experiments are conducted to validate the effectiveness of Character-Adapter. Both quantitative and qualitative results demonstrate that Character-Adapter achieves the state-of-the-art performance of consistent character generation, with an improvement of 24.8% compared with other methods
Let Storytelling Tell Vivid Stories: An Expressive and Fluent Multimodal Storyteller
Mar 12, 2024



Storytelling aims to generate reasonable and vivid narratives based on an ordered image stream. The fidelity to the image story theme and the divergence of story plots attract readers to keep reading. Previous works iteratively improved the alignment of multiple modalities but ultimately resulted in the generation of simplistic storylines for image streams. In this work, we propose a new pipeline, termed LLaMS, to generate multimodal human-level stories that are embodied in expressiveness and consistency. Specifically, by fully exploiting the commonsense knowledge within the LLM, we first employ a sequence data auto-enhancement strategy to enhance factual content expression and leverage a textual reasoning architecture for expressive story generation and prediction. Secondly, we propose SQ-Adatpter module for story illustration generation which can maintain sequence consistency. Numerical results are conducted through human evaluation to verify the superiority of proposed LLaMS. Evaluations show that LLaMS achieves state-of-the-art storytelling performance and 86% correlation and 100% consistency win rate as compared with previous SOTA methods. Furthermore, ablation experiments are conducted to verify the effectiveness of proposed sequence data enhancement and SQ-Adapter.
EfficientDreamer: High-Fidelity and Robust 3D Creation via Orthogonal-view Diffusion Prior
Aug 25, 2023



While the image diffusion model has made significant strides in text-driven 3D content creation, it often falls short in accurately capturing the intended meaning of the text prompt, particularly with respect to direction information. This shortcoming gives rise to the Janus problem, where multi-faced 3D models are produced with the guidance of such diffusion models. In this paper, we present a robust pipeline for generating high-fidelity 3D content with orthogonal-view image guidance. Specifically, we introduce a novel 2D diffusion model that generates an image consisting of four orthogonal-view sub-images for the given text prompt. The 3D content is then created with this diffusion model, which enhances 3D consistency and provides strong structured semantic priors. This addresses the infamous Janus problem and significantly promotes generation efficiency. Additionally, we employ a progressive 3D synthesis strategy that results in substantial improvement in the quality of the created 3D contents. Both quantitative and qualitative evaluations show that our method demonstrates a significant improvement over previous text-to-3D techniques.
Structure-CLIP: Enhance Multi-modal Language Representations with Structure Knowledge
May 06, 2023Large-scale vision-language pre-training has shown promising advances on various downstream tasks and achieved significant performance in multi-modal understanding and generation tasks. However, existing methods often perform poorly on image-text matching tasks that require a detailed semantics understanding of the text. Although there have been some works on this problem, they do not sufficiently exploit the structural knowledge present in sentences to enhance multi-modal language representations, which leads to poor performance. In this paper, we present an end-to-end framework Structure-CLIP, which integrates latent detailed semantics from the text to enhance fine-grained semantic representations. Specifically, (1) we use scene graphs in order to pay more attention to the detailed semantic learning in the text and fully explore structured knowledge between fine-grained semantics, and (2) we utilize the knowledge-enhanced framework with the help of the scene graph to make full use of representations of structured knowledge. To verify the effectiveness of our proposed method, we pre-trained our models with the aforementioned approach and conduct experiments on different downstream tasks. Numerical results show that Structure-CLIP can often achieve state-of-the-art performance on both VG-Attribution and VG-Relation datasets. Extensive experiments show its components are effective and its predictions are interpretable, which proves that our proposed method can enhance detailed semantic representation well.
Facial Action Unit Detection and Intensity Estimation from Self-supervised Representation
Oct 28, 2022



As a fine-grained and local expression behavior measurement, facial action unit (FAU) analysis (e.g., detection and intensity estimation) has been documented for its time-consuming, labor-intensive, and error-prone annotation. Thus a long-standing challenge of FAU analysis arises from the data scarcity of manual annotations, limiting the generalization ability of trained models to a large extent. Amounts of previous works have made efforts to alleviate this issue via semi/weakly supervised methods and extra auxiliary information. However, these methods still require domain knowledge and have not yet avoided the high dependency on data annotation. This paper introduces a robust facial representation model MAE-Face for AU analysis. Using masked autoencoding as the self-supervised pre-training approach, MAE-Face first learns a high-capacity model from a feasible collection of face images without additional data annotations. Then after being fine-tuned on AU datasets, MAE-Face exhibits convincing performance for both AU detection and AU intensity estimation, achieving a new state-of-the-art on nearly all the evaluation results. Further investigation shows that MAE-Face achieves decent performance even when fine-tuned on only 1\% of the AU training set, strongly proving its robustness and generalization performance.
Easy and Efficient Transformer : Scalable Inference Solution For large NLP mode
Apr 26, 2021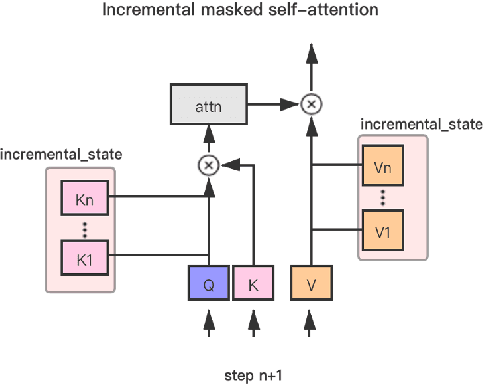
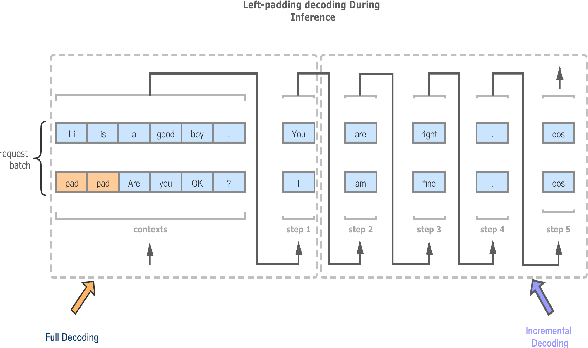

The ultra-large-scale pre-training model can effectively improve the effect of a variety of tasks, and it also brings a heavy computational burden to inference. This paper introduces a series of ultra-large-scale pre-training model optimization methods that combine algorithm characteristics and GPU processor hardware characteristics, and on this basis, propose an inference engine -- Easy and Efficient Transformer (EET), Which has a significant performance improvement over the existing schemes. We firstly introduce a pre-padding decoding mechanism that improves token parallelism for generation tasks. Then we design high optimized kernels to remove sequence masks and achieve cost-free calculation for padding tokens, as well as support long sequence and long embedding sizes. Thirdly a user-friendly inference system with an easy service pipeline was introduced which greatly reduces the difficulty of engineering deployment with high throughput. Compared to Faster Transformer's implementation for GPT-2 on A100, EET achieves a 1.5-15x state-of-art speedup varying with context length.EET is available https://github.com/NetEase-FuXi/EET.
A Note on Graph-Based Nearest Neighbor Search
Dec 21, 2020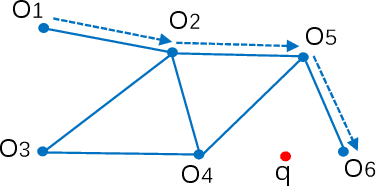
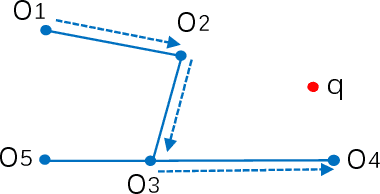
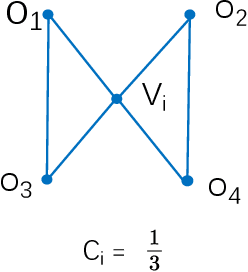
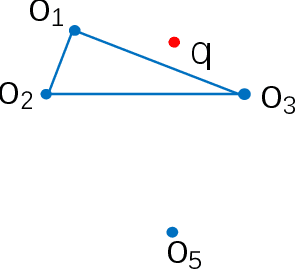
Nearest neighbor search has found numerous applications in machine learning, data mining and massive data processing systems. The past few years have witnessed the popularity of the graph-based nearest neighbor search paradigm because of its superiority over the space-partitioning algorithms. While a lot of empirical studies demonstrate the efficiency of graph-based algorithms, not much attention has been paid to a more fundamental question: why graph-based algorithms work so well in practice? And which data property affects the efficiency and how? In this paper, we try to answer these questions. Our insight is that "the probability that the neighbors of a point o tends to be neighbors in the KNN graph" is a crucial data property for query efficiency. For a given dataset, such a property can be qualitatively measured by clustering coefficient of the KNN graph. To show how clustering coefficient affects the performance, we identify that, instead of the global connectivity, the local connectivity around some given query q has more direct impact on recall. Specifically, we observed that high clustering coefficient makes most of the k nearest neighbors of q sit in a maximum strongly connected component (SCC) in the graph. From the algorithmic point of view, we show that the search procedure is actually composed of two phases - the one outside the maximum SCC and the other one in it, which is different from the widely accepted single or multiple paths search models. We proved that the commonly used graph-based search algorithm is guaranteed to traverse the maximum SCC once visiting any point in it. Our analysis reveals that high clustering coefficient leads to large size of the maximum SCC, and thus provides good answer quality with the help of the two-phase search procedure. Extensive empirical results over a comprehensive collection of datasets validate our findings.