 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Locality Sensitive Hashing with Theoretical Guarantee
Sep 27, 2023



Locality-sensitive hashing (LSH) is an effective randomized technique widely used in many machine learning tasks. The cost of hashing is proportional to data dimensions, and thus often the performance bottleneck when dimensionality is high and the number of hash functions involved is large. Surprisingly, however, little work has been done to improve the efficiency of LSH computation. In this paper, we design a simple yet efficient LSH scheme, named FastLSH, under l2 norm. By combining random sampling and random projection, FastLSH reduces the time complexity from O(n) to O(m) (m<n), where n is the data dimensionality and m is the number of sampled dimensions. Moreover, FastLSH has provable LSH property, which distinguishes it from the non-LSH fast sketches. We conduct comprehensive experiments over a collection of real and synthetic datasets for the nearest neighbor search task. Experimental results demonstrate that FastLSH is on par with the state-of-the-arts in terms of answer quality, space occupation and query efficiency, while enjoying up to 80x speedup in hash function evaluation. We believe that FastLSH is a promising alternative to the classic LSH scheme.
Tao: A Learning Framework for Adaptive Nearest Neighbor Search using Static Features Only
Oct 02, 2021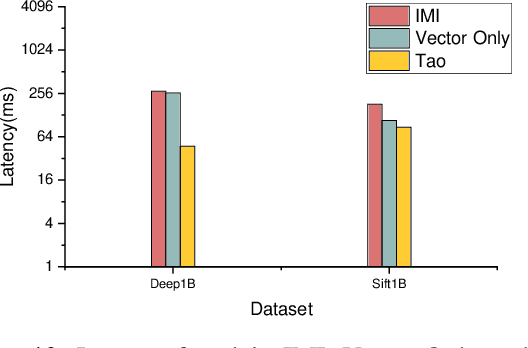
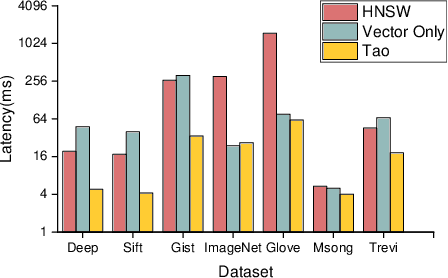
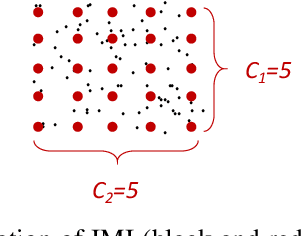
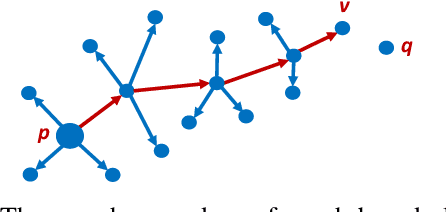
Approximate nearest neighbor (ANN) search is a fundamental problem in areas such as data management,information retrieval and machine learning. Recently, Li et al. proposed a learned approach named AdaptNN to support adaptive ANN query processing. In the middle of query execution, AdaptNN collects a number of runtime features and predicts termination condition for each individual query, by which better end-to-end latency is attained. Despite its efficiency, using runtime features complicates the learning process and leads to performance degradation. Radically different from AdaptNN, we argue that it is promising to predict termination condition before query exetution. Particularly, we developed Tao, a general learning framework for Terminating ANN queries Adaptively using Only static features. Upon the arrival of a query, Tao first maps the query to a local intrinsic dimension (LID) number, and then predicts the termination condition using LID instead of runtime features. By decoupling prediction procedure from query execution, Tao eliminates the laborious feature selection process involved in AdaptNN. Besides, two design principles are formulated to guide the application of Tao and improve the explainability of the prediction model. We integrate two state-of-the-art indexing approaches, i.e., IMI and HNSW, into Tao, and evaluate the performance over several million to billion-scale datasets. Experimental results show that, in addition to its simplicity and generality , Tao achieves up to 2.69x speedup even compared to its counterpart, at the same high accuracy targets.
A Note on Graph-Based Nearest Neighbor Search
Dec 21, 2020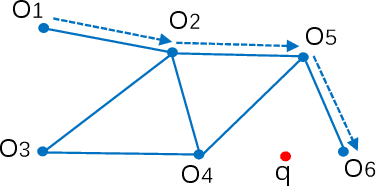
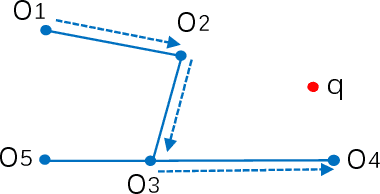
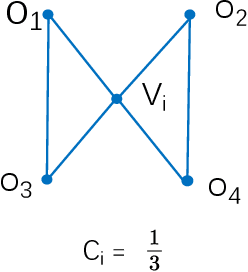
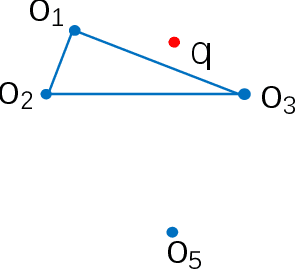
Nearest neighbor search has found numerous applications in machine learning, data mining and massive data processing systems. The past few years have witnessed the popularity of the graph-based nearest neighbor search paradigm because of its superiority over the space-partitioning algorithms. While a lot of empirical studies demonstrate the efficiency of graph-based algorithms, not much attention has been paid to a more fundamental question: why graph-based algorithms work so well in practice? And which data property affects the efficiency and how? In this paper, we try to answer these questions. Our insight is that "the probability that the neighbors of a point o tends to be neighbors in the KNN graph" is a crucial data property for query efficiency. For a given dataset, such a property can be qualitatively measured by clustering coefficient of the KNN graph. To show how clustering coefficient affects the performance, we identify that, instead of the global connectivity, the local connectivity around some given query q has more direct impact on recall. Specifically, we observed that high clustering coefficient makes most of the k nearest neighbors of q sit in a maximum strongly connected component (SCC) in the graph. From the algorithmic point of view, we show that the search procedure is actually composed of two phases - the one outside the maximum SCC and the other one in it, which is different from the widely accepted single or multiple paths search models. We proved that the commonly used graph-based search algorithm is guaranteed to traverse the maximum SCC once visiting any point in it. Our analysis reveals that high clustering coefficient leads to large size of the maximum SCC, and thus provides good answer quality with the help of the two-phase search procedure. Extensive empirical results over a comprehensive collection of datasets validate our findings.