 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning universal approximations for partial differential equations with Physics-Informed Broad Learning System
Jun 18, 2026Partial differential equations (PDEs) play a central role in modeling complex physical, biological, and engineering systems. While traditional numerical solvers are robust, they often incur prohibitive computational costs due to mesh dependencies, whereas recent Physics-Informed Neural Networks (PINNs) offer a mesh-free alternative but frequently suffer from slow convergence and optimization instability. To bridge this gap, this article proposes the Physics-Informed Broad Learning System (PIBLS), a novel backpropagation-free framework that reformulates PDE solving as a direct least-squares optimization. We improved an algorithm within this framework to handle nonlinear PDEs efficiently and provide a rigorous mathematical proof establishing the universal approximation property of PIBLS for these equations. Experiments on linear and nonlinear PDEs demonstrate that PIBLS is one to three orders of magnitude faster than conventional PINNs while achieving significantly higher solution accuracy. This framework provides a computationally efficient paradigm for scientific machine learning, offering a practical, high-speed alternative for real-time simulation and design optimization tasks.
LoopVLA: Learning Sufficiency in Recurrent Refinement for Vision-Language-Action Models
May 11, 2026Current Vision-Language-Action (VLA) models typically treat the deepest representation of a vision-language backbone as universally optimal for action prediction. However, robotic manipulation is composed of many frequent closed-loop spatial adjustments, for which excessive abstraction may waste computation and weaken low-level geometric cues essential for precise control. Existing early-exit strategies attempt to reduce computation by stopping at predefined layers or applying heuristic rules such as action consistency, but they do not directly answer when a representation is actually sufficient for action. In this paper, we present LoopVLA, a recurrent VLA architecture that jointly learns representation refinement, action prediction, and sufficiency estimation. LoopVLA iteratively applies a shared Transformer block to refine multimodal tokens, and at each iteration produces both a candidate action and a sufficiency score that estimates whether further refinement is necessary. By sharing parameters across iterations, LoopVLA decouples refinement from absolute layer indices and grounds sufficiency estimation in the evolving representation itself. Since sufficiency has no direct supervision, we introduce a self-supervised distribution alignment objective, where intermediate confidence scores are trained to match the relative action quality across refinement steps, thereby linking sufficiency learning to policy optimization signals. Experiments on LIBERO, LIBERO-Plus, and VLA-Arena show that LoopVLA pushes the efficiency-performance frontier of VLA policies, reducing parameters by 45% and improving inference throughput by up to 1.7 times while matching or outperforming strong baselines in task success.
FIA-Edit: Frequency-Interactive Attention for Efficient and High-Fidelity Inversion-Free Text-Guided Image Editing
Nov 15, 2025Text-guided image editing has advanced rapidly with the rise of diffusion models. While flow-based inversion-free methods offer high efficiency by avoiding latent inversion, they often fail to effectively integrate source information, leading to poor background preservation, spatial inconsistencies, and over-editing due to the lack of effective integration of source information. In this paper, we present FIA-Edit, a novel inversion-free framework that achieves high-fidelity and semantically precise edits through a Frequency-Interactive Attention. Specifically, we design two key components: (1) a Frequency Representation Interaction (FRI) module that enhances cross-domain alignment by exchanging frequency components between source and target features within self-attention, and (2) a Feature Injection (FIJ) module that explicitly incorporates source-side queries, keys, values, and text embeddings into the target branch's cross-attention to preserve structure and semantics. Comprehensive and extensive experiments demonstrate that FIA-Edit supports high-fidelity editing at low computational cost (~6s per 512 * 512 image on an RTX 4090) and consistently outperforms existing methods across diverse tasks in visual quality, background fidelity, and controllability. Furthermore, we are the first to extend text-guided image editing to clinical applications. By synthesizing anatomically coherent hemorrhage variations in surgical images, FIA-Edit opens new opportunities for medical data augmentation and delivers significant gains in downstream bleeding classification. Our project is available at: https://github.com/kk42yy/FIA-Edit.
Bidirectional Mammogram View Translation with Column-Aware and Implicit 3D Conditional Diffusion
Oct 06, 2025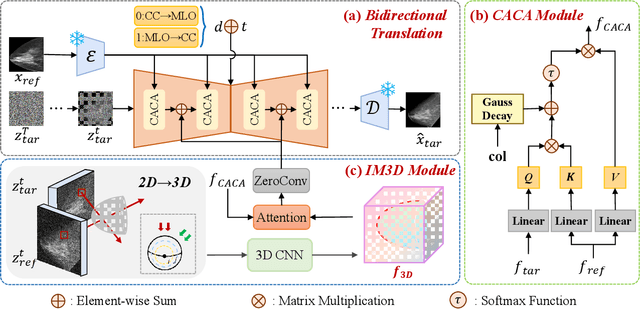
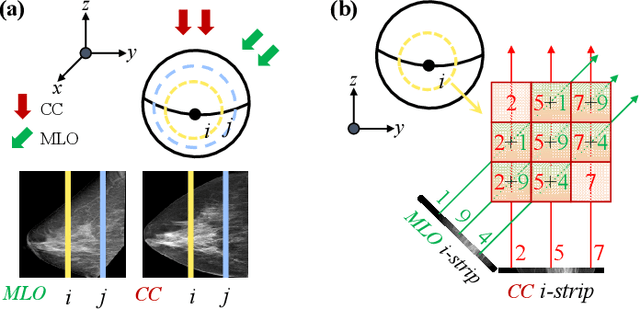
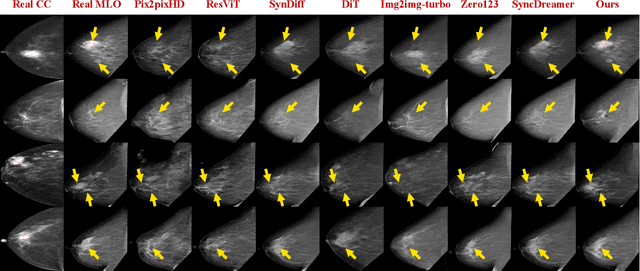
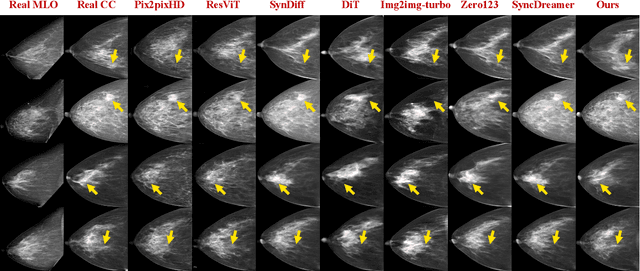
Dual-view mammography, including craniocaudal (CC) and mediolateral oblique (MLO) projections, offers complementary anatomical views crucial for breast cancer diagnosis. However, in real-world clinical workflows, one view may be missing, corrupted, or degraded due to acquisition errors or compression artifacts, limiting the effectiveness of downstream analysis. View-to-view translation can help recover missing views and improve lesion alignment. Unlike natural images, this task in mammography is highly challenging due to large non-rigid deformations and severe tissue overlap in X-ray projections, which obscure pixel-level correspondences. In this paper, we propose Column-Aware and Implicit 3D Diffusion (CA3D-Diff), a novel bidirectional mammogram view translation framework based on conditional diffusion model. To address cross-view structural misalignment, we first design a column-aware cross-attention mechanism that leverages the geometric property that anatomically corresponding regions tend to lie in similar column positions across views. A Gaussian-decayed bias is applied to emphasize local column-wise correlations while suppressing distant mismatches. Furthermore, we introduce an implicit 3D structure reconstruction module that back-projects noisy 2D latents into a coarse 3D feature volume based on breast-view projection geometry. The reconstructed 3D structure is refined and injected into the denoising UNet to guide cross-view generation with enhanced anatomical awareness. Extensive experiments demonstrate that CA3D-Diff achieves superior performance in bidirectional tasks, outperforming state-of-the-art methods in visual fidelity and structural consistency. Furthermore, the synthesized views effectively improve single-view malignancy classification in screening settings, demonstrating the practical value of our method in real-world diagnostics.
AdaFusion: Prompt-Guided Inference with Adaptive Fusion of Pathology Foundation Models
Aug 07, 2025Pathology foundation models (PFMs) have demonstrated strong representational capabilities through self-supervised pre-training on large-scale, unannotated histopathology image datasets. However, their diverse yet opaque pretraining contexts, shaped by both data-related and structural/training factors, introduce latent biases that hinder generalisability and transparency in downstream applications. In this paper, we propose AdaFusion, a novel prompt-guided inference framework that, to our knowledge, is among the very first to dynamically integrate complementary knowledge from multiple PFMs. Our method compresses and aligns tile-level features from diverse models and employs a lightweight attention mechanism to adaptively fuse them based on tissue phenotype context. We evaluate AdaFusion on three real-world benchmarks spanning treatment response prediction, tumour grading, and spatial gene expression inference. Our approach consistently surpasses individual PFMs across both classification and regression tasks, while offering interpretable insights into each model's biosemantic specialisation. These results highlight AdaFusion's ability to bridge heterogeneous PFMs, achieving both enhanced performance and interpretability of model-specific inductive biases.
RoHyDR: Robust Hybrid Diffusion Recovery for Incomplete Multimodal Emotion Recognition
May 23, 2025Multimodal emotion recognition analyzes emotions by combining data from multiple sources. However, real-world noise or sensor failures often cause missing or corrupted data, creating the Incomplete Multimodal Emotion Recognition (IMER) challenge. In this paper, we propose Robust Hybrid Diffusion Recovery (RoHyDR), a novel framework that performs missing-modality recovery at unimodal, multimodal, feature, and semantic levels. For unimodal representation recovery of missing modalities, RoHyDR exploits a diffusion-based generator to generate distribution-consistent and semantically aligned representations from Gaussian noise, using available modalities as conditioning. For multimodal fusion recovery, we introduce adversarial learning to produce a realistic fused multimodal representation and recover missing semantic content. We further propose a multi-stage optimization strategy that enhances training stability and efficiency. In contrast to previous work, the hybrid diffusion and adversarial learning-based recovery mechanism in RoHyDR allows recovery of missing information in both unimodal representation and multimodal fusion, at both feature and semantic levels, effectively mitigating performance degradation caused by suboptimal optimization. Comprehensive experiments conducted on two widely used multimodal emotion recognition benchmarks demonstrate that our proposed method outperforms state-of-the-art IMER methods, achieving robust recognition performance under various missing-modality scenarios. Our code will be made publicly available upon acceptance.
CoStoDet-DDPM: Collaborative Training of Stochastic and Deterministic Models Improves Surgical Workflow Anticipation and Recognition
Mar 13, 2025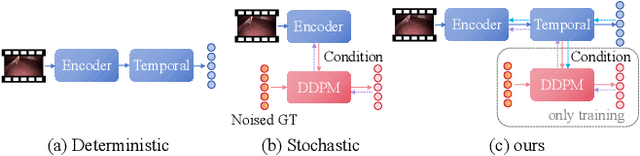
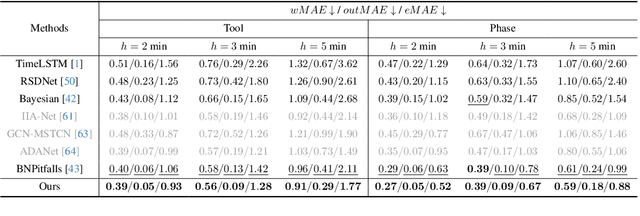
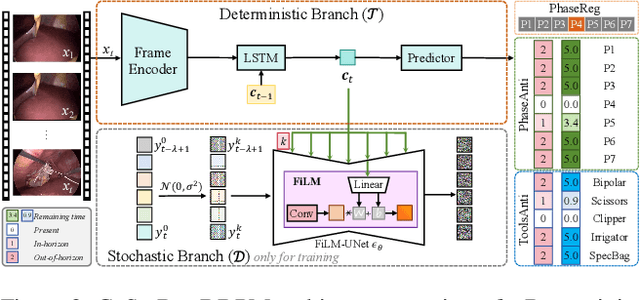
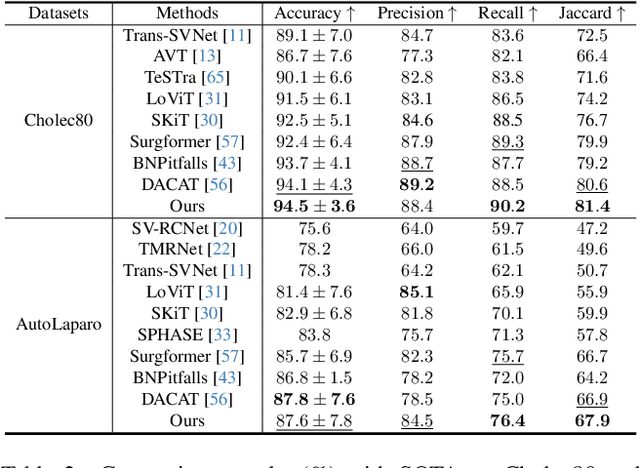
Anticipating and recognizing surgical workflows are critical for intelligent surgical assistance systems. However, existing methods rely on deterministic decision-making, struggling to generalize across the large anatomical and procedural variations inherent in real-world surgeries.In this paper, we introduce an innovative framework that incorporates stochastic modeling through a denoising diffusion probabilistic model (DDPM) into conventional deterministic learning for surgical workflow analysis. At the heart of our approach is a collaborative co-training paradigm: the DDPM branch captures procedural uncertainties to enrich feature representations, while the task branch focuses on predicting surgical phases and instrument usage.Theoretically, we demonstrate that this mutual refinement mechanism benefits both branches: the DDPM reduces prediction errors in uncertain scenarios, and the task branch directs the DDPM toward clinically meaningful representations. Notably, the DDPM branch is discarded during inference, enabling real-time predictions without sacrificing accuracy.Experiments on the Cholec80 dataset show that for the anticipation task, our method achieves a 16% reduction in eMAE compared to state-of-the-art approaches, and for phase recognition, it improves the Jaccard score by 1.0%. Additionally, on the AutoLaparo dataset, our method achieves a 1.5% improvement in the Jaccard score for phase recognition, while also exhibiting robust generalization to patient-specific variations. Our code and weight are available at https://github.com/kk42yy/CoStoDet-DDPM.
Multi-Class Segmentation of Aortic Branches and Zones in Computed Tomography Angiography: The AortaSeg24 Challenge
Feb 07, 2025



Multi-class segmentation of the aorta in computed tomography angiography (CTA) scans is essential for diagnosing and planning complex endovascular treatments for patients with aortic dissections. However, existing methods reduce aortic segmentation to a binary problem, limiting their ability to measure diameters across different branches and zones. Furthermore, no open-source dataset is currently available to support the development of multi-class aortic segmentation methods. To address this gap, we organized the AortaSeg24 MICCAI Challenge, introducing the first dataset of 100 CTA volumes annotated for 23 clinically relevant aortic branches and zones. This dataset was designed to facilitate both model development and validation. The challenge attracted 121 teams worldwide, with participants leveraging state-of-the-art frameworks such as nnU-Net and exploring novel techniques, including cascaded models, data augmentation strategies, and custom loss functions. We evaluated the submitted algorithms using the Dice Similarity Coefficient (DSC) and Normalized Surface Distance (NSD), highlighting the approaches adopted by the top five performing teams. This paper presents the challenge design, dataset details, evaluation metrics, and an in-depth analysis of the top-performing algorithms. The annotated dataset, evaluation code, and implementations of the leading methods are publicly available to support further research. All resources can be accessed at https://aortaseg24.grand-challenge.org.
A New Perspective on Time Series Anomaly Detection: Faster Patch-based Broad Learning System
Dec 07, 2024



Time series anomaly detection (TSAD) has been a research hotspot in both academia and industry in recent years. Deep learning methods have become the mainstream research direction due to their excellent performance. However, new viewpoints have emerged in recent TSAD research. Deep learning is not required for TSAD due to limitations such as slow deep learning speed. The Broad Learning System (BLS) is a shallow network framework that benefits from its ease of optimization and speed. It has been shown to outperform machine learning approaches while remaining competitive with deep learning. Based on the current situation of TSAD, we propose the Contrastive Patch-based Broad Learning System (CPatchBLS). This is a new exploration of patching technique and BLS, providing a new perspective for TSAD. We construct Dual-PatchBLS as a base through patching and Simple Kernel Perturbation (SKP) and utilize contrastive learning to capture the differences between normal and abnormal data under different representations. To compensate for the temporal semantic loss caused by various patching, we propose CPatchBLS with model level integration, which takes advantage of BLS's fast feature to build model-level integration and improve model detection. Using five real-world series anomaly detection datasets, we confirmed the method's efficacy, outperforming previous deep learning and machine learning methods while retaining a high level of computing efficiency.
DACAT: Dual-stream Adaptive Clip-aware Time Modeling for Robust Online Surgical Phase Recognition
Sep 10, 2024Surgical phase recognition has become a crucial requirement in laparoscopic surgery, enabling various clinical applications like surgical risk forecasting. Current methods typically identify the surgical phase using individual frame-wise embeddings as the fundamental unit for time modeling. However, this approach is overly sensitive to current observations, often resulting in discontinuous and erroneous predictions within a complete surgical phase. In this paper, we propose DACAT, a novel dual-stream model that adaptively learns clip-aware context information to enhance the temporal relationship. In one stream, DACAT pretrains a frame encoder, caching all historical frame-wise features. In the other stream, DACAT fine-tunes a new frame encoder to extract the frame-wise feature at the current moment. Additionally, a max clip-response read-out (Max-R) module is introduced to bridge the two streams by using the current frame-wise feature to adaptively fetch the most relevant past clip from the feature cache. The clip-aware context feature is then encoded via cross-attention between the current frame and its fetched adaptive clip, and further utilized to enhance the time modeling for accurate online surgical phase recognition. The benchmark results on three public datasets, i.e., Cholec80, M2CAI16, and AutoLaparo, demonstrate the superiority of our proposed DACAT over existing state-of-the-art methods, with improvements in Jaccard scores of at least 4.5%, 4.6%, and 2.7%, respectively. Our code and models have been released at https://github.com/kk42yy/DACAT.