 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Constraint from Two Direction in Evolutionary Constrained Multi-objective Optimization
Dec 30, 2025Real-world Constrained Multi-objective Optimization Problems (CMOPs) often contain multiple constraints, and understanding and utilizing the coupling between these constraints is crucial for solving CMOPs. However, existing Constrained Multi-objective Evolutionary Algorithms (CMOEAs) typically ignore these couplings and treat all constraints as a single aggregate, which lacks interpretability regarding the specific geometric roles of constraints. To address this limitation, we first analyze how different constraints interact and show that the final Constrained Pareto Front (CPF) depends not only on the Pareto fronts of individual constraints but also on the boundaries of infeasible regions. This insight implies that CMOPs with different coupling types must be solved from different search directions. Accordingly, we propose a novel algorithm named Decoupling Constraint from Two Directions (DCF2D). This method periodically detects constraint couplings and spawns an auxiliary population for each relevant constraint with an appropriate search direction. Extensive experiments on seven challenging CMOP benchmark suites and on a collection of real-world CMOPs demonstrate that DCF2D outperforms five state-of-the-art CMOEAs, including existing decoupling-based methods.
WarmServe: Enabling One-for-Many GPU Prewarming for Multi-LLM Serving
Dec 10, 2025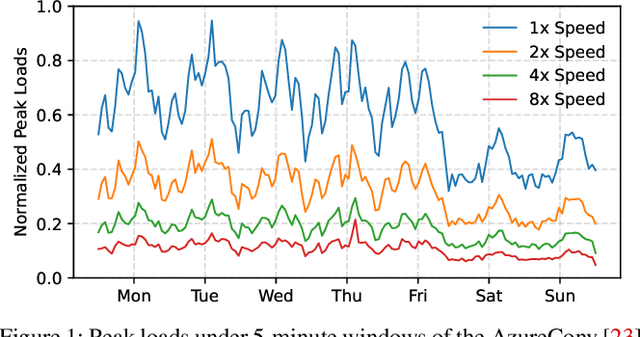
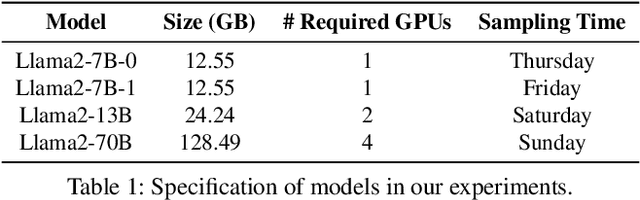
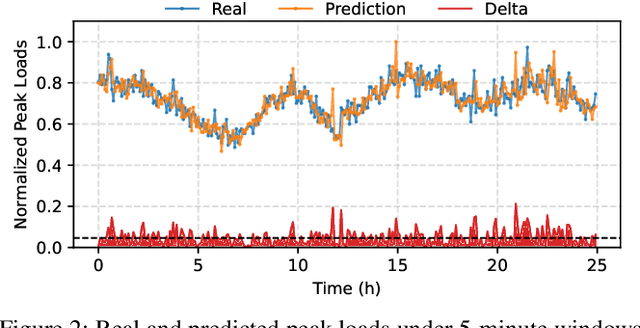
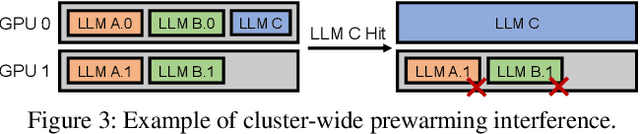
Deploying multiple models within shared GPU clusters is promising for improving resource efficiency in large language model (LLM) serving. Existing multi-LLM serving systems optimize GPU utilization at the cost of worse inference performance, especially time-to-first-token (TTFT). We identify the root cause of such compromise as their unawareness of future workload characteristics. In contrast, recent analysis on real-world traces has shown the high periodicity and long-term predictability of LLM serving workloads. We propose universal GPU workers to enable one-for-many GPU prewarming that loads models with knowledge of future workloads. Based on universal GPU workers, we design and build WarmServe, a multi-LLM serving system that (1) mitigates cluster-wide prewarming interference by adopting an evict-aware model placement strategy, (2) prepares universal GPU workers in advance by proactive prewarming, and (3) manages GPU memory with a zero-overhead memory switching mechanism. Evaluation under real-world datasets shows that WarmServe improves TTFT by up to 50.8$\times$ compared to the state-of-the-art autoscaling-based system, while being capable of serving up to 2.5$\times$ more requests compared to the GPU-sharing system.
Evolutionary Algorithm with Detection Region Method for Constrained Multi-Objective Problems with Binary Constraints
Nov 13, 2024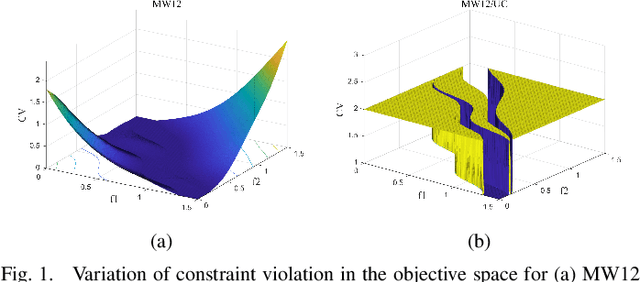
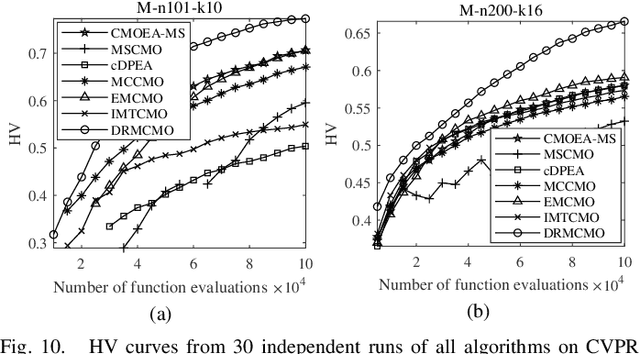
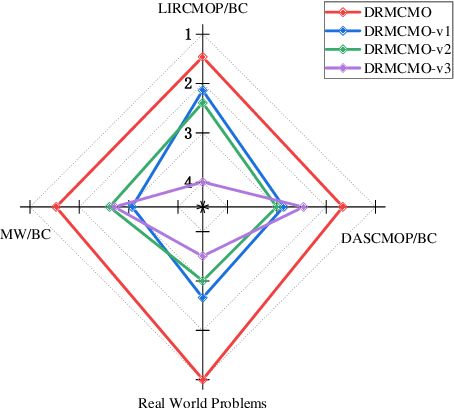
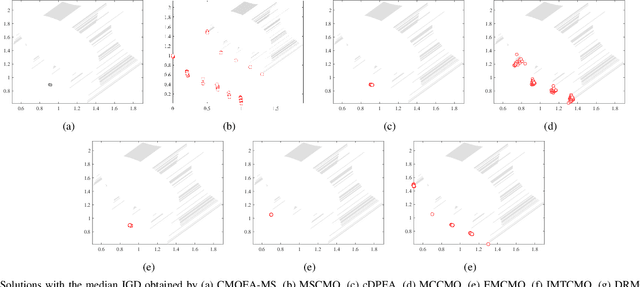
Solving constrained multi-objective optimization problems (CMOPs) is a challenging task. While many practical algorithms have been developed to tackle CMOPs, real-world scenarios often present cases where the constraint functions are unknown or unquantifiable, resulting in only binary outcomes (feasible or infeasible). This limitation reduces the effectiveness of constraint violation guidance, which can negatively impact the performance of existing algorithms that rely on this approach. Such challenges are particularly detrimental for algorithms employing the epsilon-based method, as they hinder effective relaxation of the feasible region. To address these challenges, this paper proposes a novel algorithm called DRMCMO based on the detection region method. In DRMCMO, detection regions dynamic monitor feasible solutions to enhance convergence, helping the population escape local optima. Additionally, these regions collaborate with the neighbor pairing strategy to improve population diversity within narrow feasible areas. We have modified three existing test suites to serve as benchmark test problems for CMOPs with binary constraints(CMOP/BC) and conducted comprehensive comparative experiments with state-of-the-art algorithms on these test suites and real-world problems. The results demonstrate the strong competitiveness of DRMCMO against state-of-the-art algorithms. Given the limited research on CMOP/BC, our study offers a new perspective for advancing this field.
ShortcutsBench: A Large-Scale Real-world Benchmark for API-based Agents
Jun 28, 2024Recent advancements in integrating large language models (LLMs) with application programming interfaces (APIs) have gained significant interest in both academia and industry. These API-based agents, leveraging the strong autonomy and planning capabilities of LLMs, can efficiently solve problems requiring multi-step actions. However, their ability to handle multi-dimensional difficulty levels, diverse task types, and real-world demands through APIs remains unknown. In this paper, we introduce \textsc{ShortcutsBench}, a large-scale benchmark for the comprehensive evaluation of API-based agents in solving tasks with varying levels of difficulty, diverse task types, and real-world demands. \textsc{ShortcutsBench} includes a wealth of real APIs from Apple Inc.'s operating systems, refined user queries from shortcuts, human-annotated high-quality action sequences from shortcut developers, and accurate parameter filling values about primitive parameter types, enum parameter types, outputs from previous actions, and parameters that need to request necessary information from the system or user. Our extensive evaluation of agents built with $5$ leading open-source (size >= 57B) and $4$ closed-source LLMs (e.g. Gemini-1.5-Pro and GPT-3.5) reveals significant limitations in handling complex queries related to API selection, parameter filling, and requesting necessary information from systems and users. These findings highlight the challenges that API-based agents face in effectively fulfilling real and complex user queries. All datasets, code, and experimental results will be available at \url{https://github.com/eachsheep/shortcutsbench}.
When Large Language Model Meets Optimization
May 16, 2024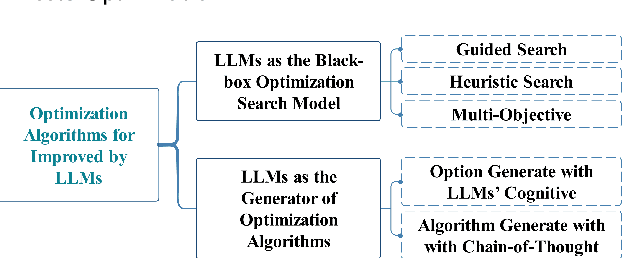
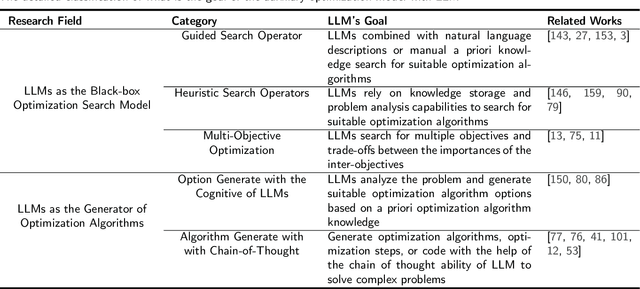
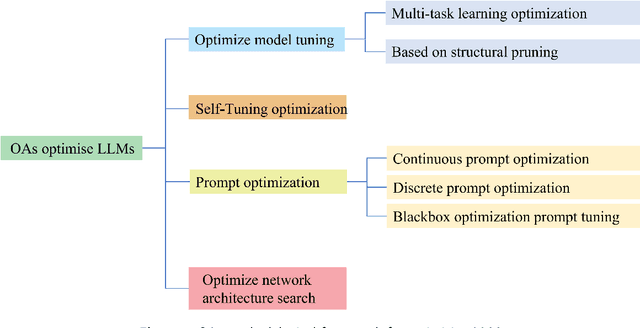

Optimization algorithms and large language models (LLMs) enhance decision-making in dynamic environments by integrating artificial intelligence with traditional techniques. LLMs, with extensive domain knowledge, facilitate intelligent modeling and strategic decision-making in optimization, while optimization algorithms refine LLM architectures and output quality. This synergy offers novel approaches for advancing general AI, addressing both the computational challenges of complex problems and the application of LLMs in practical scenarios. This review outlines the progress and potential of combining LLMs with optimization algorithms, providing insights for future research directions.