 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParetoPilot: Zero-Surrogate Offline Multi-Objective Optimization via Infer-Perturb-Guide Diffusion
Jun 03, 2026Offline multi-objective optimization (Offline MOO) aims to discover novel Pareto-optimal designs based on static datasets without expensive environment interactions. While recent generative methods have achieved notable success, they predominantly rely on external surrogate models. This dependency introduces significant computational overhead, suffers from deceptive evaluations, and deviates from the prevailing paradigm of jointly training mainstream generative models with conditions. To address these bottlenecks, we propose ParetoPilot, a novel zero-surrogate diffusion framework for offline MOO. ParetoPilot fully leverages the conditional priors inherently embedded within pre-trained diffusion models. At its core, the framework introduces the Infer-Perturb-Guide (IPG) engine, which is seamlessly interleaved within the unconditional denoising steps of the reverse generation process. First, it implicitly infers the instantaneous objective direction by matching conditional and unconditional noise predictions. Next, it mathematically orthogonalizes a parallel gravity field for strict convergence and an edgeness-aware repulsive force for mutual diversity, creating a dynamically annealed perturbation vector. Finally, this perturbed target seamlessly steers the generation process via standard Classifier-Free Guidance (CFG). Extensive experiments across 51 tasks demonstrate that ParetoPilot outperforms 14 state-of-the-art surrogate-based and inverse generative baselines. By eliminating auxiliary proxy training, our approach preserves data privacy while achieving hypervolume improvement and robust Pareto front coverage.
Beyond Scores: Diagnostic LLM Evaluation via Fine-Grained Abilities
Apr 14, 2026Current evaluations of large language models aggregate performance across diverse tasks into single scores. This obscures fine-grained ability variation, limiting targeted model improvement and ability-guided selection for specific tasks. Motivated by this gap, we propose a cognitive diagnostic framework that estimates model abilities across multiple fine-grained dimensions. For mathematics, we construct a 35-dimensional ability taxonomy grounded in cognitive theory and domain knowledge. The framework employs multidimensional Item Response Theory with an item-ability association matrix to estimate fine-grained ability levels, which in turn enable prediction of performance on unseen items (questions of benchmark). Evaluated on 41 models, our approach demonstrates strong criterion validity, consistent ability estimates across benchmarks, and accurate prediction of unseen items with AUC ranging from 0.80 to 0.89 within benchmarks and from 0.77 to 0.86 across benchmarks, substantially exceeding trivial baselines. The framework generalizes across scientific domains, producing consistent diagnostic performance in physics (27 dimensions), chemistry (58 dimensions), and computer science (12 dimensions). This work establishes a principled framework for fine-grained assessment of abilities, with potential applications in targeted training, ability-guided model selection, and ability-aware benchmark design.
Ranking Constraints via Topological Dual-Directional Search in Evolutionary Multi-Objective Optimization
Apr 06, 2026Existing evolutionary algorithms for Constrained Multi-objective Optimization Problems (CMOPs) typically treat all constraints uniformly, overlooking their distinct geometric relationships with the true Constrained Pareto Front (CPF). In reality, constraints play different roles: some directly shape the final CPF, some create infeasible obstacles, while others are irrelevant. To exploit this insight, we propose a novel algorithm named RCCMO, which sequentially performs unconstrained exploration, single-constraint exploitation, and full-constraint refinement. The core innovation of RCCMO lies in a constraint prioritization method derived from these geometric insights, seamlessly coupled with a unique dual-directional search mechanism. Specifically, RCCMO first prioritizes constraints that constitute the final CPF, approaching them from the evolutionary direction (optimizing objectives) to locate the CPF directly shaped by single-constraint boundaries. Subsequently, for constraints that merely hinder the population's progress, RCCMO searches from the anti-evolutionary direction (targeting the infeasible boundaries where hindering constraints intersect with the CPF) to effectively discover how these constraints obstruct and form the final CPF. Meanwhile, irrelevant constraints are intentionally bypassed. Furthermore, a series of specialized mechanisms are proposed to accelerate the algorithm's execution, reduce heuristic misjudgments, and dynamically adjust search directions in real time. Extensive experiments on 5 benchmark test suites and 29 real-world CMOPs demonstrate that RCCMO significantly outperforms seven state-of-the-art algorithms.
Decoupling Constraint from Two Direction in Evolutionary Constrained Multi-objective Optimization
Dec 30, 2025Real-world Constrained Multi-objective Optimization Problems (CMOPs) often contain multiple constraints, and understanding and utilizing the coupling between these constraints is crucial for solving CMOPs. However, existing Constrained Multi-objective Evolutionary Algorithms (CMOEAs) typically ignore these couplings and treat all constraints as a single aggregate, which lacks interpretability regarding the specific geometric roles of constraints. To address this limitation, we first analyze how different constraints interact and show that the final Constrained Pareto Front (CPF) depends not only on the Pareto fronts of individual constraints but also on the boundaries of infeasible regions. This insight implies that CMOPs with different coupling types must be solved from different search directions. Accordingly, we propose a novel algorithm named Decoupling Constraint from Two Directions (DCF2D). This method periodically detects constraint couplings and spawns an auxiliary population for each relevant constraint with an appropriate search direction. Extensive experiments on seven challenging CMOP benchmark suites and on a collection of real-world CMOPs demonstrate that DCF2D outperforms five state-of-the-art CMOEAs, including existing decoupling-based methods.
An Equivariant Graph Network for Interpretable Nanoporous Materials Design
Sep 19, 2025Nanoporous materials hold promise for diverse sustainable applications, yet their vast chemical space poses challenges for efficient design. Machine learning offers a compelling pathway to accelerate the exploration, but existing models lack either interpretability or fidelity for elucidating the correlation between crystal geometry and property. Here, we report a three-dimensional periodic space sampling method that decomposes large nanoporous structures into local geometrical sites for combined property prediction and site-wise contribution quantification. Trained with a constructed database and retrieved datasets, our model achieves state-of-the-art accuracy and data efficiency for property prediction on gas storage, separation, and electrical conduction. Meanwhile, this approach enables the interpretation of the prediction and allows for accurate identification of significant local sites for targeted properties. Through identifying transferable high-performance sites across diverse nanoporous frameworks, our model paves the way for interpretable, symmetry-aware nanoporous materials design, which is extensible to other materials, like molecular crystals and beyond.
StreamLink: Large-Language-Model Driven Distributed Data Engineering System
May 27, 2025Large Language Models (LLMs) have shown remarkable proficiency in natural language understanding (NLU), opening doors for innovative applications. We introduce StreamLink - an LLM-driven distributed data system designed to improve the efficiency and accessibility of data engineering tasks. We build StreamLink on top of distributed frameworks such as Apache Spark and Hadoop to handle large data at scale. One of the important design philosophies of StreamLink is to respect user data privacy by utilizing local fine-tuned LLMs instead of a public AI service like ChatGPT. With help from domain-adapted LLMs, we can improve our system's understanding of natural language queries from users in various scenarios and simplify the procedure of generating database queries like the Structured Query Language (SQL) for information processing. We also incorporate LLM-based syntax and security checkers to guarantee the reliability and safety of each generated query. StreamLink illustrates the potential of merging generative LLMs with distributed data processing for comprehensive and user-centric data engineering. With this architecture, we allow users to interact with complex database systems at different scales in a user-friendly and security-ensured manner, where the SQL generation reaches over 10\% of execution accuracy compared to baseline methods, and allow users to find the most concerned item from hundreds of millions of items within a few seconds using natural language.
Evolutionary training-free guidance in diffusion model for 3D multi-objective molecular generation
May 16, 2025Discovering novel 3D molecular structures that simultaneously satisfy multiple property targets remains a central challenge in materials and drug design. Although recent diffusion-based models can generate 3D conformations, they require expensive retraining for each new property or property-combination and lack flexibility in enforcing structural constraints. We introduce EGD (Evolutionary Guidance in Diffusion), a training-free framework that embeds evolutionary operators directly into the diffusion sampling process. By performing crossover on noise-perturbed samples and then denoising them with a pretrained Unconditional diffusion model, EGD seamlessly blends structural fragments and steers generation toward user-specified objectives without any additional model updates. On both single- and multi-target 3D conditional generation tasks-and on multi-objective optimization of quantum properties EGD outperforms state-of-the-art conditional diffusion methods in accuracy and runs up to five times faster per generation. In the single-objective optimization of protein ligands, EGD enables customized ligand generation. Moreover, EGD can embed arbitrary 3D fragments into the generated molecules while optimizing multiple conflicting properties in one unified process. This combination of efficiency, flexibility, and controllable structure makes EGD a powerful tool for rapid, guided exploration of chemical space.
Pay More Attention to the Robustness of Prompt for Instruction Data Mining
Mar 31, 2025Instruction tuning has emerged as a paramount method for tailoring the behaviors of LLMs. Recent work has unveiled the potential for LLMs to achieve high performance through fine-tuning with a limited quantity of high-quality instruction data. Building upon this approach, we further explore the impact of prompt's robustness on the selection of high-quality instruction data. This paper proposes a pioneering framework of high-quality online instruction data mining for instruction tuning, focusing on the impact of prompt's robustness on the data mining process. Our notable innovation, is to generate the adversarial instruction data by conducting the attack for the prompt of online instruction data. Then, we introduce an Adversarial Instruction-Following Difficulty metric to measure how much help the adversarial instruction data can provide to the generation of the corresponding response. Apart from it, we propose a novel Adversarial Instruction Output Embedding Consistency approach to select high-quality online instruction data. We conduct extensive experiments on two benchmark datasets to assess the performance. The experimental results serve to underscore the effectiveness of our proposed two methods. Moreover, the results underscore the critical practical significance of considering prompt's robustness.
AudioCIL: A Python Toolbox for Audio Class-Incremental Learning with Multiple Scenes
Dec 16, 2024Deep learning, with its robust aotomatic feature extraction capabilities, has demonstrated significant success in audio signal processing. Typically, these methods rely on static, pre-collected large-scale datasets for training, performing well on a fixed number of classes. However, the real world is characterized by constant change, with new audio classes emerging from streaming or temporary availability due to privacy. This dynamic nature of audio environments necessitates models that can incrementally learn new knowledge for new classes without discarding existing information. Introducing incremental learning to the field of audio signal processing, i.e., Audio Class-Incremental Learning (AuCIL), is a meaningful endeavor. We propose such a toolbox named AudioCIL to align audio signal processing algorithms with real-world scenarios and strengthen research in audio class-incremental learning.
Exploring structure diversity in atomic resolution microscopy with graph neural networks
Oct 23, 2024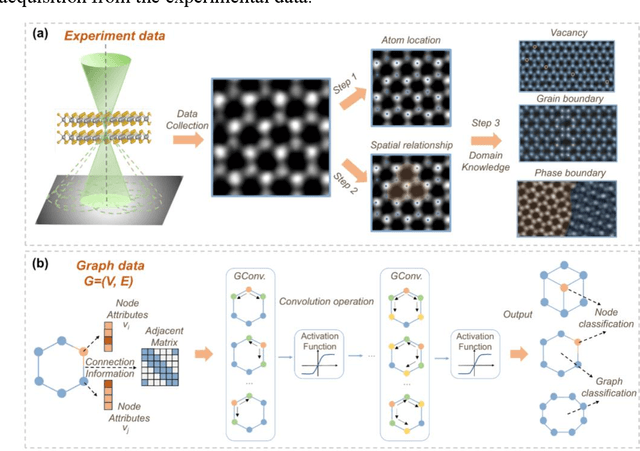
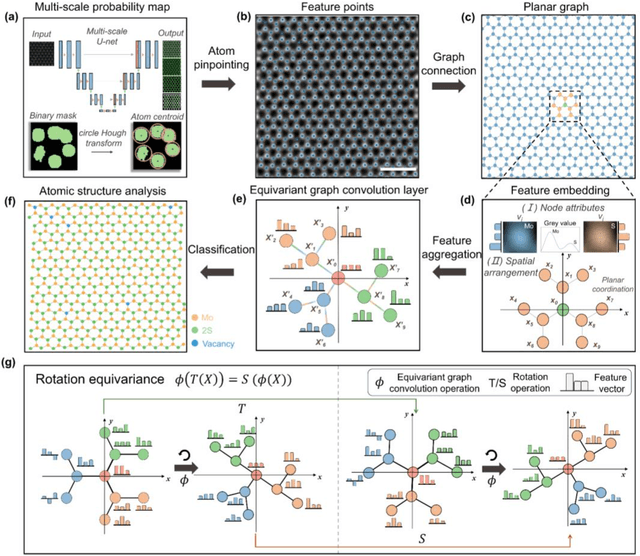
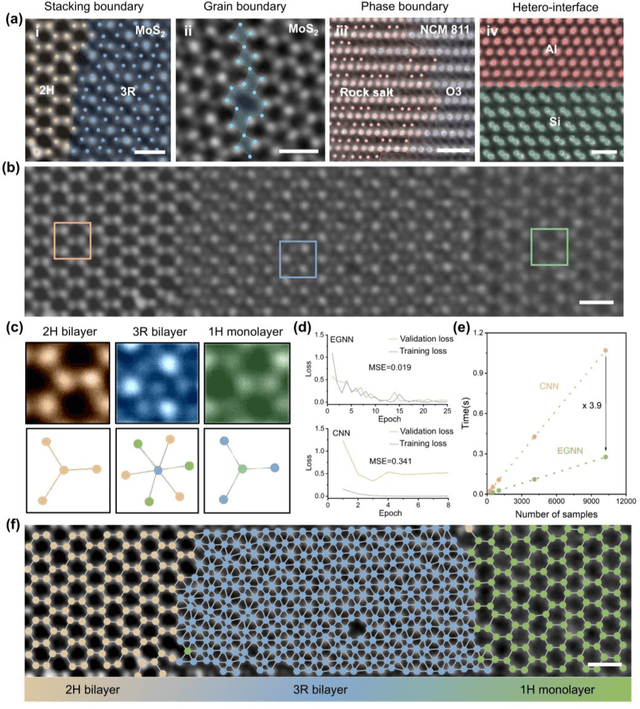
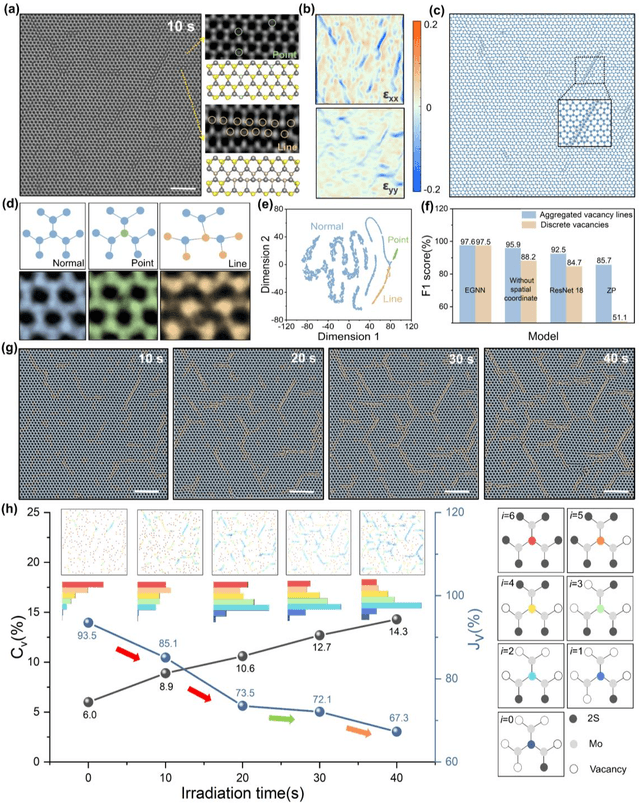
The emergence of deep learning (DL) has provided great opportunities for the high-throughput analysis of atomic-resolution micrographs. However, the DL models trained by image patches in fixed size generally lack efficiency and flexibility when processing micrographs containing diversified atomic configurations. Herein, inspired by the similarity between the atomic structures and graphs, we describe a few-shot learning framework based on an equivariant graph neural network (EGNN) to analyze a library of atomic structures (e.g., vacancies, phases, grain boundaries, doping, etc.), showing significantly promoted robustness and three orders of magnitude reduced computing parameters compared to the image-driven DL models, which is especially evident for those aggregated vacancy lines with flexible lattice distortion. Besides, the intuitiveness of graphs enables quantitative and straightforward extraction of the atomic-scale structural features in batches, thus statistically unveiling the self-assembly dynamics of vacancy lines under electron beam irradiation. A versatile model toolkit is established by integrating EGNN sub-models for single structure recognition to process images involving varied configurations in the form of a task chain, leading to the discovery of novel doping configurations with superior electrocatalytic properties for hydrogen evolution reactions. This work provides a powerful tool to explore structure diversity in a fast, accurate, and intelligent manner.