 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSilent Speech Interfaces in the Era of Large Language Models: A Comprehensive Taxonomy and Systematic Review
Mar 12, 2026Human-computer interaction has traditionally relied on the acoustic channel, a dependency that introduces systemic vulnerabilities to environmental noise, privacy constraints, and physiological speech impairments. Silent Speech Interfaces (SSIs) emerge as a transformative paradigm that bypasses the acoustic stage by decoding linguistic intent directly from the neuro-muscular-articulatory continuum. This review provides a high-level synthesis of the SSI landscape, transitioning from traditional transducer-centric analysis to a holistic intent-to-execution taxonomy. We systematically evaluate sensing modalities across four critical physiological interception points: neural oscillations, neuromuscular activation, articulatory kinematics (ultrasound/magnetometry), and pervasive active probing via acoustic or radio-frequency sensing. Critically, we analyze the current paradigm shift from heuristic signal processing to Latent Semantic Alignment. In this new era, Large Language Models (LLMs) and deep generative architectures serve as high-level linguistic priors to resolve the ``informational sparsity'' and non-stationarity of biosignals. By mapping fragmented physiological gestures into structured semantic latent spaces, modern SSI frameworks have, for the first time, approached the Word Error Rate usability threshold required for real-world deployment. We further examine the transition of SSIs from bulky laboratory instrumentation to ``invisible interfaces'' integrated into commodity-grade wearables, such as earables and smart glasses. Finally, we outline a strategic roadmap addressing the ``user-dependency paradox'' through self-supervised foundation models and define the ethical boundaries of ``neuro-security'' to protect cognitive liberty in an increasingly interfaced world.
UniSurg: A Video-Native Foundation Model for Universal Understanding of Surgical Videos
Feb 05, 2026While foundation models have advanced surgical video analysis, current approaches rely predominantly on pixel-level reconstruction objectives that waste model capacity on low-level visual details - such as smoke, specular reflections, and fluid motion - rather than semantic structures essential for surgical understanding. We present UniSurg, a video-native foundation model that shifts the learning paradigm from pixel-level reconstruction to latent motion prediction. Built on the Video Joint Embedding Predictive Architecture (V-JEPA), UniSurg introduces three key technical innovations tailored to surgical videos: 1) motion-guided latent prediction to prioritize semantically meaningful regions, 2) spatiotemporal affinity self-distillation to enforce relational consistency, and 3) feature diversity regularization to prevent representation collapse in texture-sparse surgical scenes. To enable large-scale pretraining, we curate UniSurg-15M, the largest surgical video dataset to date, comprising 3,658 hours of video from 50 sources across 13 anatomical regions. Extensive experiments across 17 benchmarks demonstrate that UniSurg significantly outperforms state-of-the-art methods on surgical workflow recognition (+14.6% F1 on EgoSurgery, +10.3% on PitVis), action triplet recognition (39.54% mAP-IVT on CholecT50), skill assessment, polyp segmentation, and depth estimation. These results establish UniSurg as a new standard for universal, motion-oriented surgical video understanding.
AI for Mycetoma Diagnosis in Histopathological Images: The MICCAI 2024 Challenge
Dec 25, 2025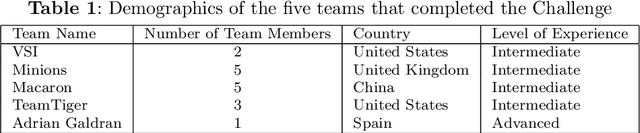
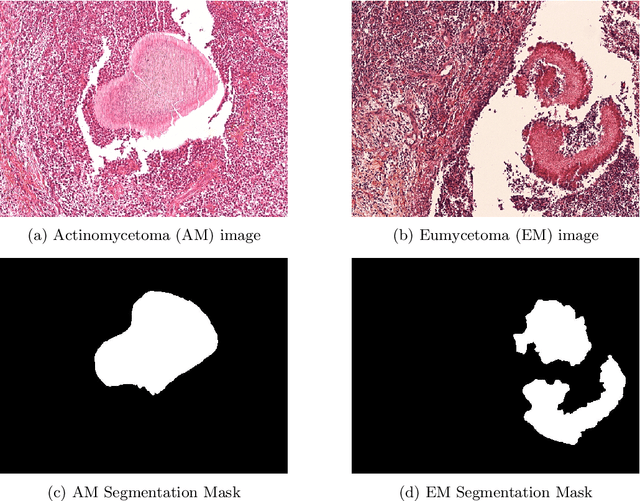
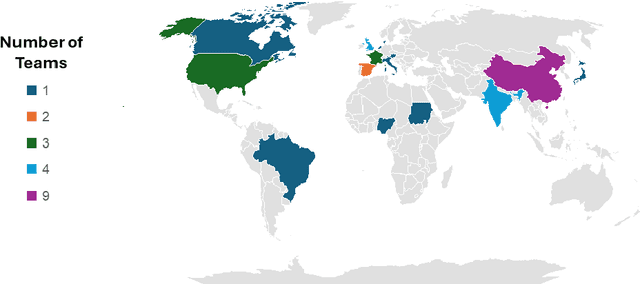

Mycetoma is a neglected tropical disease caused by fungi or bacteria leading to severe tissue damage and disabilities. It affects poor and rural communities and presents medical challenges and socioeconomic burdens on patients and healthcare systems in endemic regions worldwide. Mycetoma diagnosis is a major challenge in mycetoma management, particularly in low-resource settings where expert pathologists are limited. To address this challenge, this paper presents an overview of the Mycetoma MicroImage: Detect and Classify Challenge (mAIcetoma) which was organized to advance mycetoma diagnosis through AI solutions. mAIcetoma focused on developing automated models for segmenting mycetoma grains and classifying mycetoma types from histopathological images. The challenge attracted the attention of several teams worldwide to participate and five finalist teams fulfilled the challenge objectives. The teams proposed various deep learning architectures for the ultimate goal of this challenge. Mycetoma database (MyData) was provided to participants as a standardized dataset to run the proposed models. Those models were evaluated using evaluation metrics. Results showed that all the models achieved high segmentation accuracy, emphasizing the necessitate of grain detection as a critical step in mycetoma diagnosis. In addition, the top-performing models show a significant performance in classifying mycetoma types.
F2PASeg: Feature Fusion for Pituitary Anatomy Segmentation in Endoscopic Surgery
Aug 07, 2025Pituitary tumors often cause deformation or encapsulation of adjacent vital structures. Anatomical structure segmentation can provide surgeons with early warnings of regions that pose surgical risks, thereby enhancing the safety of pituitary surgery. However, pixel-level annotated video stream datasets for pituitary surgeries are extremely rare. To address this challenge, we introduce a new dataset for Pituitary Anatomy Segmentation (PAS). PAS comprises 7,845 time-coherent images extracted from 120 videos. To mitigate class imbalance, we apply data augmentation techniques that simulate the presence of surgical instruments in the training data. One major challenge in pituitary anatomy segmentation is the inconsistency in feature representation due to occlusions, camera motion, and surgical bleeding. By incorporating a Feature Fusion module, F2PASeg is proposed to refine anatomical structure segmentation by leveraging both high-resolution image features and deep semantic embeddings, enhancing robustness against intraoperative variations. Experimental results demonstrate that F2PASeg consistently segments critical anatomical structures in real time, providing a reliable solution for intraoperative pituitary surgery planning. Code: https://github.com/paulili08/F2PASeg.
Decadal analysis of sea surface temperature patterns, climatology, and anomalies in temperate coastal waters with Landsat-8 TIRS observations
Mar 07, 2025Sea surface temperature (SST) is a fundamental physical parameter characterising the thermal state of sea surface. The Thermal Infrared Sensor (TIRS) onboard Landsat-8, with its 100-meter spatial resolution, offers a unique opportunity to uncover fine-scale coastal SST patterns that would otherwise be overlooked by coarser-resolution thermal sensors. In this study, we first develop an operational approach for SST retrieval from the TIRS sensor, and subsequently propose a novel algorithm for establishing daily SST climatology which serves as the baseline to detect anomalous SST events. We applied the proposed methods to temperate coastal waters in South Australia for the ten-year period from 2014 to 2023. For ground validation purposes, a buoy was deployed off the coast of Port Lincoln, South Australia, to record in-situ time-series SST. The spatiotemporal patterns of SST in the study area were analysed based on the ten years of satellite-derived SST imagery. The daily baseline climatology of SST with 100 m resolution was constructed, which allowed for the detection and analysis of anomalous SST events during the study period of 2014-2023. Our results suggest the following: (1) the satellite-derived SST data, generated with the proposed algorithm, aligned well with the in-situ measured SST values; (2) the semi-enclosed, shallow regions of Upper Spencer Gulf and Upper St Vincent Gulf showed higher temperatures during summer and cooler temperatures during winter than waters closer to the open ocean, resulting in a higher seasonal variation in SST; (3) the near-shore shallow areas in Spencer Gulf and St Vincent Gulf, and regions surrounding Kangaroo Island, were identified to have a higher probability of SST anomalies compared to the rest of the study area; and (4) anomalous SST events were more likely to happen during the warm months than the cool months.
Exploring structure diversity in atomic resolution microscopy with graph neural networks
Oct 23, 2024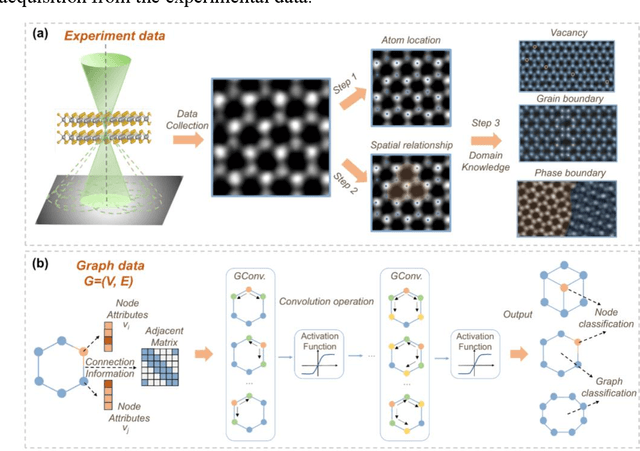
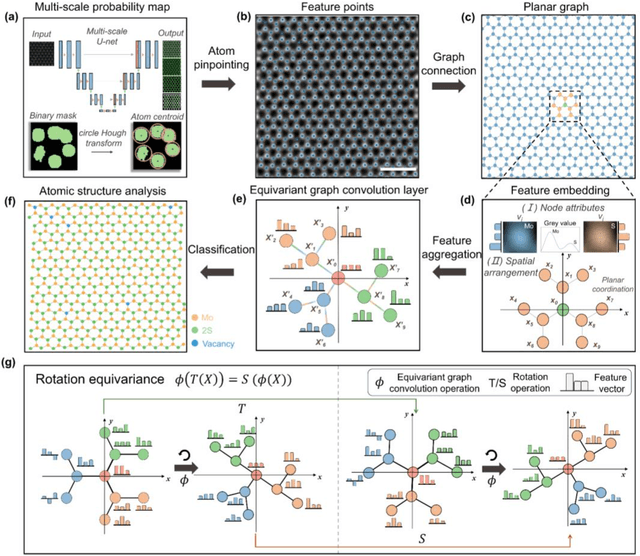
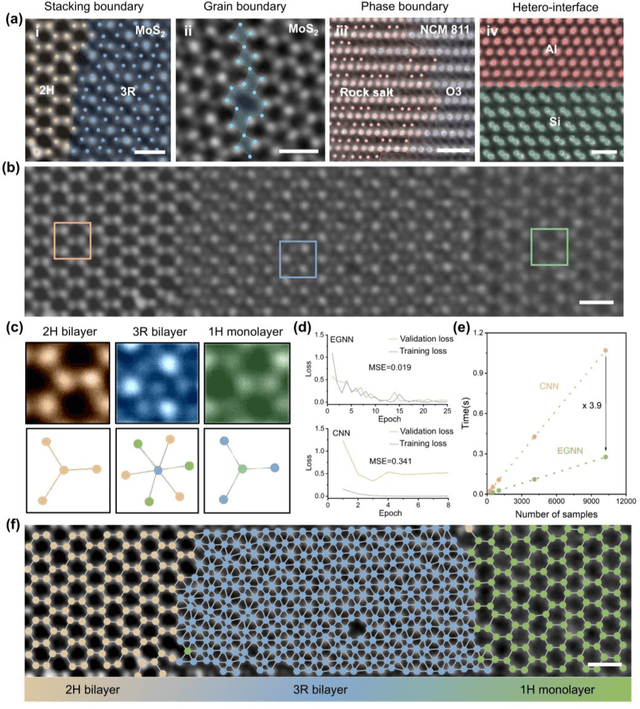
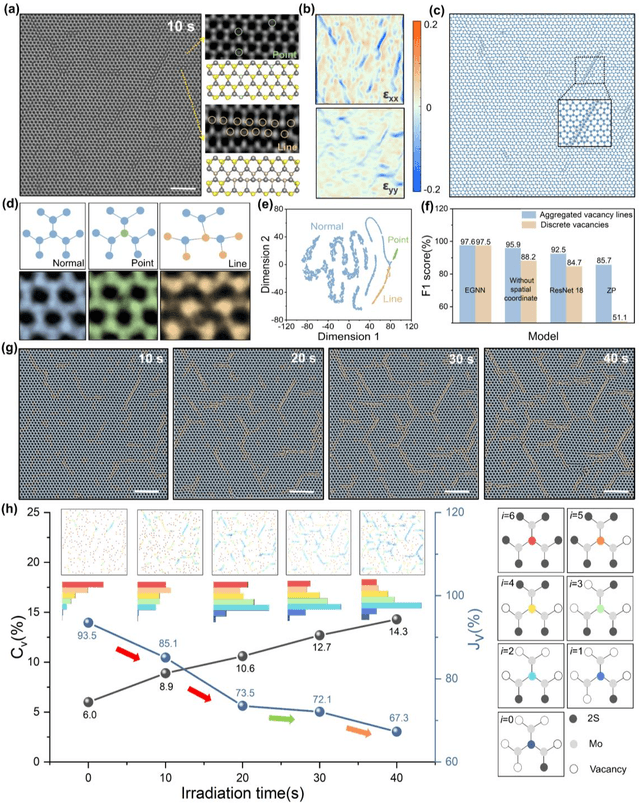
The emergence of deep learning (DL) has provided great opportunities for the high-throughput analysis of atomic-resolution micrographs. However, the DL models trained by image patches in fixed size generally lack efficiency and flexibility when processing micrographs containing diversified atomic configurations. Herein, inspired by the similarity between the atomic structures and graphs, we describe a few-shot learning framework based on an equivariant graph neural network (EGNN) to analyze a library of atomic structures (e.g., vacancies, phases, grain boundaries, doping, etc.), showing significantly promoted robustness and three orders of magnitude reduced computing parameters compared to the image-driven DL models, which is especially evident for those aggregated vacancy lines with flexible lattice distortion. Besides, the intuitiveness of graphs enables quantitative and straightforward extraction of the atomic-scale structural features in batches, thus statistically unveiling the self-assembly dynamics of vacancy lines under electron beam irradiation. A versatile model toolkit is established by integrating EGNN sub-models for single structure recognition to process images involving varied configurations in the form of a task chain, leading to the discovery of novel doping configurations with superior electrocatalytic properties for hydrogen evolution reactions. This work provides a powerful tool to explore structure diversity in a fast, accurate, and intelligent manner.
Wound Segmentation with Dynamic Illumination Correction and Dual-view Semantic Fusion
Jul 12, 2022
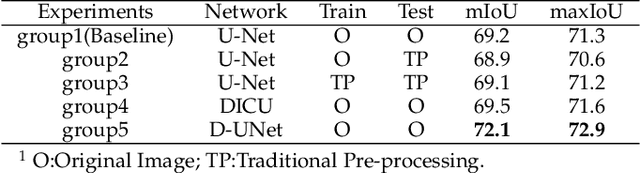
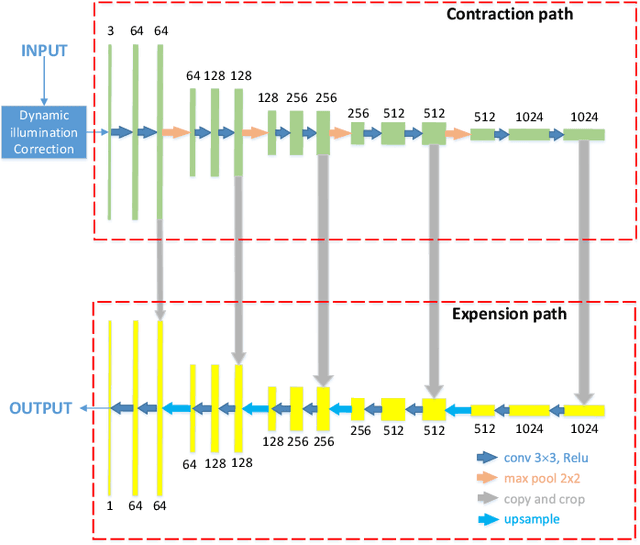

Wound image segmentation is a critical component for the clinical diagnosis and in-time treatment of wounds. Recently, deep learning has become the mainstream methodology for wound image segmentation. However, the pre-processing of the wound image, such as the illumination correction, is required before the training phase as the performance can be greatly improved. The correction procedure and the training of deep models are independent of each other, which leads to sub-optimal segmentation performance as the fixed illumination correction may not be suitable for all images. To address aforementioned issues, an end-to-end dual-view segmentation approach was proposed in this paper, by incorporating a learn-able illumination correction module into the deep segmentation models. The parameters of the module can be learned and updated during the training stage automatically, while the dual-view fusion can fully employ the features from both the raw images and the enhanced ones. To demonstrate the effectiveness and robustness of the proposed framework, the extensive experiments are conducted on the benchmark datasets. The encouraging results suggest that our framework can significantly improve the segmentation performance, compared to the state-of-the-art methods.
Trusted Multi-Scale Classification Framework for Whole Slide Image
Jul 12, 2022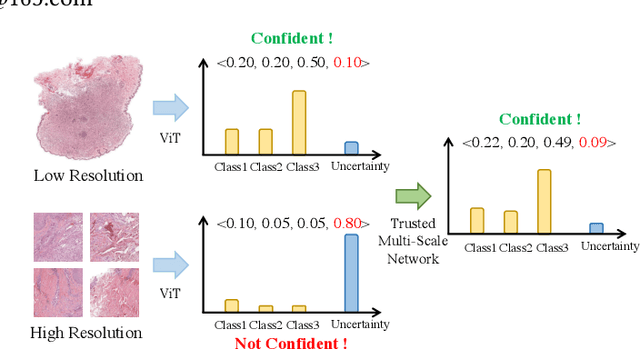


Despite remarkable efforts been made, the classification of gigapixels whole-slide image (WSI) is severely restrained from either the constrained computing resources for the whole slides, or limited utilizing of the knowledge from different scales. Moreover, most of the previous attempts lacked of the ability of uncertainty estimation. Generally, the pathologists often jointly analyze WSI from the different magnifications. If the pathologists are uncertain by using single magnification, then they will change the magnification repeatedly to discover various features of the tissues. Motivated by the diagnose process of the pathologists, in this paper, we propose a trusted multi-scale classification framework for the WSI. Leveraging the Vision Transformer as the backbone for multi branches, our framework can jointly classification modeling, estimating the uncertainty of each magnification of a microscope and integrate the evidence from different magnification. Moreover, to exploit discriminative patches from WSIs and reduce the requirement for computation resources, we propose a novel patch selection schema using attention rollout and non-maximum suppression. To empirically investigate the effectiveness of our approach, empirical experiments are conducted on our WSI classification tasks, using two benchmark databases. The obtained results suggest that the trusted framework can significantly improve the WSI classification performance compared with the state-of-the-art methods.
Underwater Acoustic Communication Channel Modeling using Reservoir Computing
May 30, 2022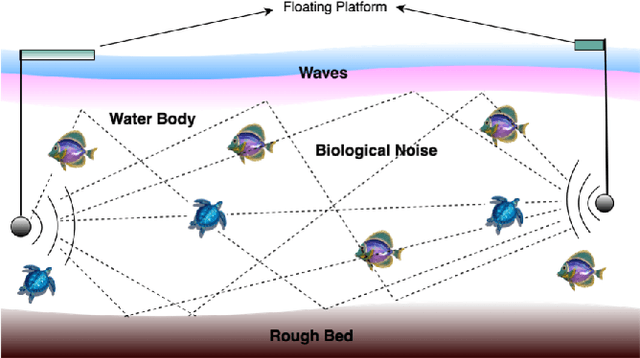
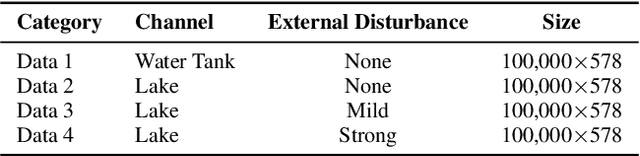
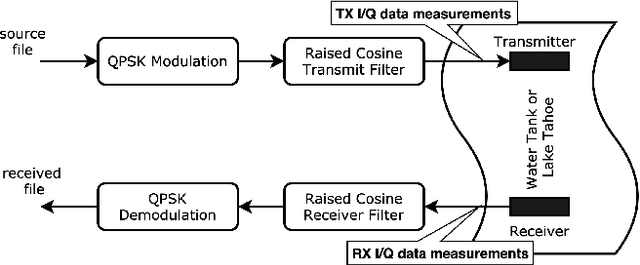

Underwater acoustic (UWA) communications have been widely used but greatly impaired due to the complicated nature of the underwater environment. In order to improve UWA communications, modeling and understanding the UWA channel is indispensable. However, there exist many challenges due to the high uncertainties of the underwater environment and the lack of real-world measurement data. In this work, the capability of reservoir computing and deep learning has been explored for modeling the UWA communication channel accurately using real underwater data collected from a water tank with disturbance and from Lake Tahoe. We leverage the capability of reservoir computing for modeling dynamical systems and provided a data-driven approach to modeling the UWA channel using Echo State Network (ESN). In addition, the potential application of transfer learning to reservoir computing has been examined. Experimental results show that ESN is able to model chaotic UWA channels with better performance compared to popular deep learning models in terms of mean absolute percentage error (MAPE), specifically, ESN has outperformed deep neural network by 2% and as much as 40% in benign and chaotic UWA respectively.
3D Shuffle-Mixer: An Efficient Context-Aware Vision Learner of Transformer-MLP Paradigm for Dense Prediction in Medical Volume
Apr 14, 2022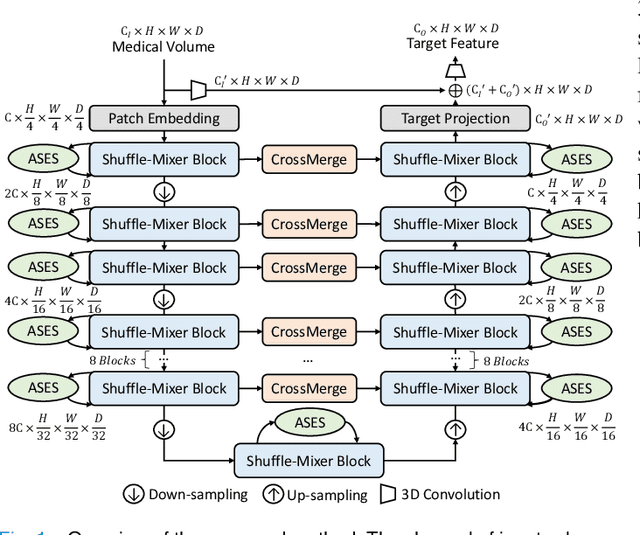
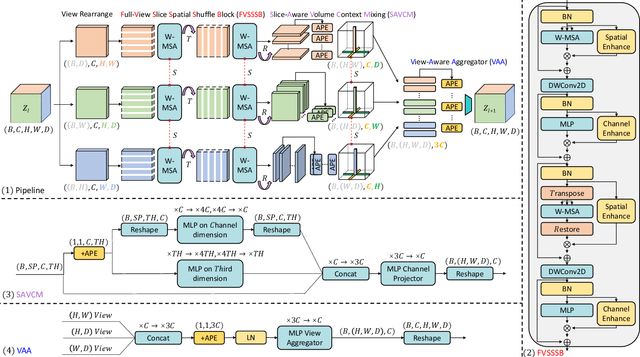
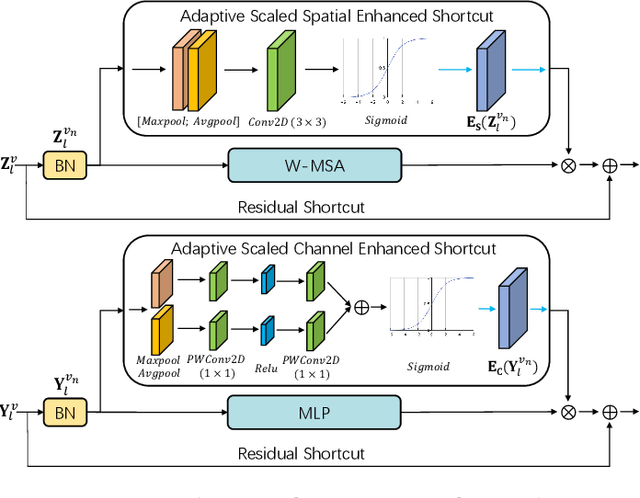
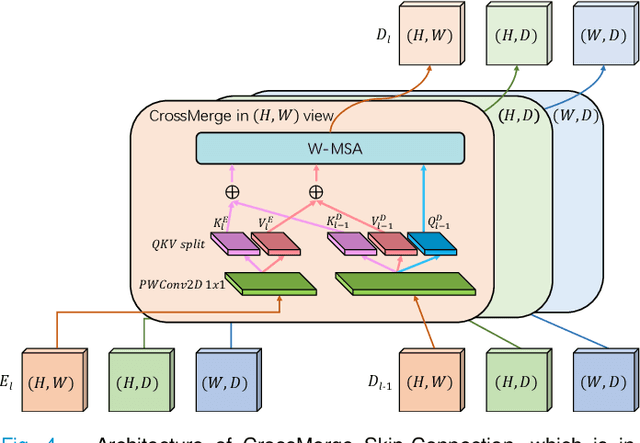
Dense prediction in medical volume provides enriched guidance for clinical analysis. CNN backbones have met bottleneck due to lack of long-range dependencies and global context modeling power. Recent works proposed to combine vision transformer with CNN, due to its strong global capture ability and learning capability. However, most works are limited to simply applying pure transformer with several fatal flaws (i.e., lack of inductive bias, heavy computation and little consideration for 3D data). Therefore, designing an elegant and efficient vision transformer learner for dense prediction in medical volume is promising and challenging. In this paper, we propose a novel 3D Shuffle-Mixer network of a new Local Vision Transformer-MLP paradigm for medical dense prediction. In our network, a local vision transformer block is utilized to shuffle and learn spatial context from full-view slices of rearranged volume, a residual axial-MLP is designed to mix and capture remaining volume context in a slice-aware manner, and a MLP view aggregator is employed to project the learned full-view rich context to the volume feature in a view-aware manner. Moreover, an Adaptive Scaled Enhanced Shortcut is proposed for local vision transformer to enhance feature along spatial and channel dimensions adaptively, and a CrossMerge is proposed to skip-connects the multi-scale feature appropriately in the pyramid architecture. Extensive experiments demonstrate the proposed model outperforms other state-of-the-art medical dense prediction methods.