 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHEROHE Challenge: assessing HER2 status in breast cancer without immunohistochemistry or in situ hybridization
Nov 08, 2021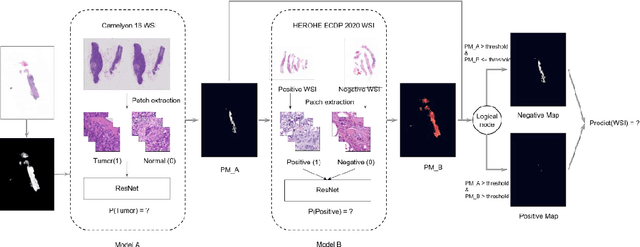
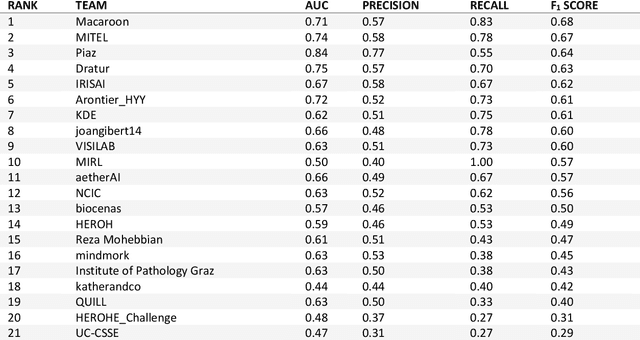
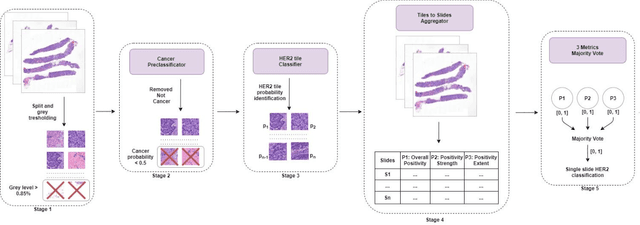
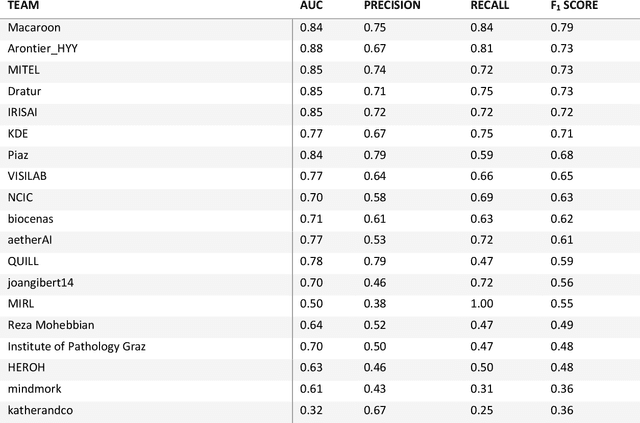
Breast cancer is the most common malignancy in women, being responsible for more than half a million deaths every year. As such, early and accurate diagnosis is of paramount importance. Human expertise is required to diagnose and correctly classify breast cancer and define appropriate therapy, which depends on the evaluation of the expression of different biomarkers such as the transmembrane protein receptor HER2. This evaluation requires several steps, including special techniques such as immunohistochemistry or in situ hybridization to assess HER2 status. With the goal of reducing the number of steps and human bias in diagnosis, the HEROHE Challenge was organized, as a parallel event of the 16th European Congress on Digital Pathology, aiming to automate the assessment of the HER2 status based only on hematoxylin and eosin stained tissue sample of invasive breast cancer. Methods to assess HER2 status were presented by 21 teams worldwide and the results achieved by some of the proposed methods open potential perspectives to advance the state-of-the-art.
DGSAN: Discrete Generative Self-Adversarial Network
Aug 24, 2019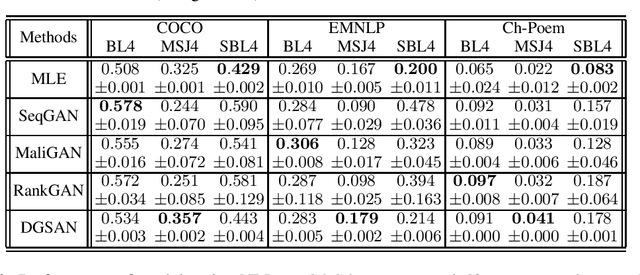

Although GAN-based methods have received many achievements in the last few years, they have not been such successful in generating discrete data. The most important challenge of these methods is the difficulty of passing the gradient from the discriminator to the generator when the generator outputs are discrete. Despite several attempts done to alleviate this problem, none of the existing GAN-based methods has improved the performance of text generation (using measures that evaluate both the quality and the diversity of generated samples) compared to a generative RNN that is simply trained by the maximum likelihood approach. In this paper, we propose a new framework for generating discrete data by an adversarial approach in which we do not need to pass the gradient to the generator. In the proposed method, the update of either the generator or the discriminator can be accomplished straightforwardly. Moreover, we leverage the discreteness of data to explicitly model the data distribution and ensure the normalization of the generated distribution and consequently the convergence properties of the proposed method. Experimental results generally show the superiority of the proposed DGSAN method compared to the other GAN-based approaches for generating discrete sequential data.
Jointly Measuring Diversity and Quality in Text Generation Models
May 20, 2019
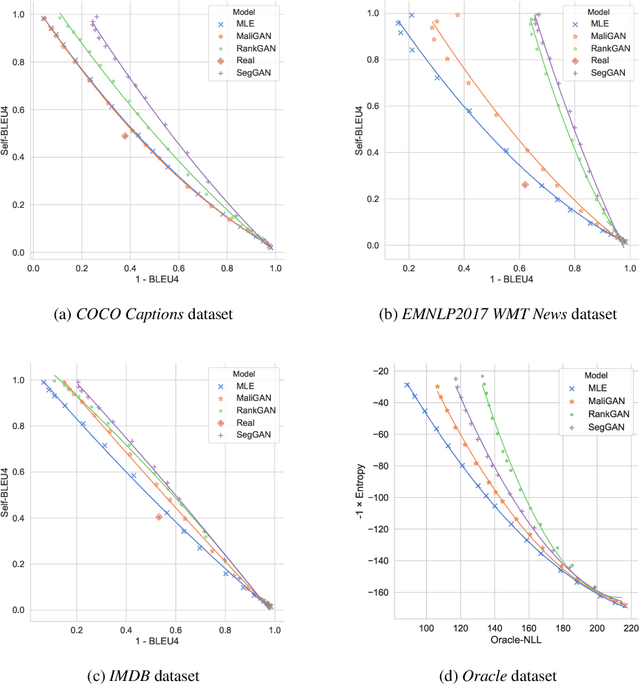

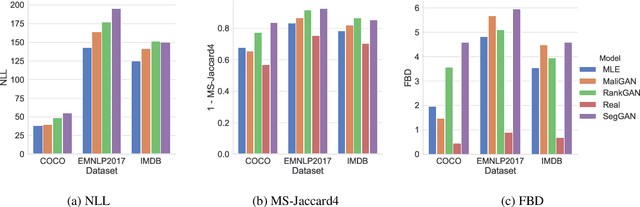
Text generation is an important Natural Language Processing task with various applications. Although several metrics have already been introduced to evaluate the text generation methods, each of them has its own shortcomings. The most widely used metrics such as BLEU only consider the quality of generated sentences and neglect their diversity. For example, repeatedly generation of only one high quality sentence would result in a high BLEU score. On the other hand, the more recent metric introduced to evaluate the diversity of generated texts known as Self-BLEU ignores the quality of generated texts. In this paper, we propose metrics to evaluate both the quality and diversity simultaneously by approximating the distance of the learned generative model and the real data distribution. For this purpose, we first introduce a metric that approximates this distance using n-gram based measures. Then, a feature-based measure which is based on a recent highly deep model trained on a large text corpus called BERT is introduced. Finally, for oracle training mode in which the generator's density can also be calculated, we propose to use the distance measures between the corresponding explicit distributions. Eventually, the most popular and recent text generation models are evaluated using both the existing and the proposed metrics and the preferences of the proposed metrics are determined.
Adversarial Classifier for Imbalanced Problems
Nov 21, 2018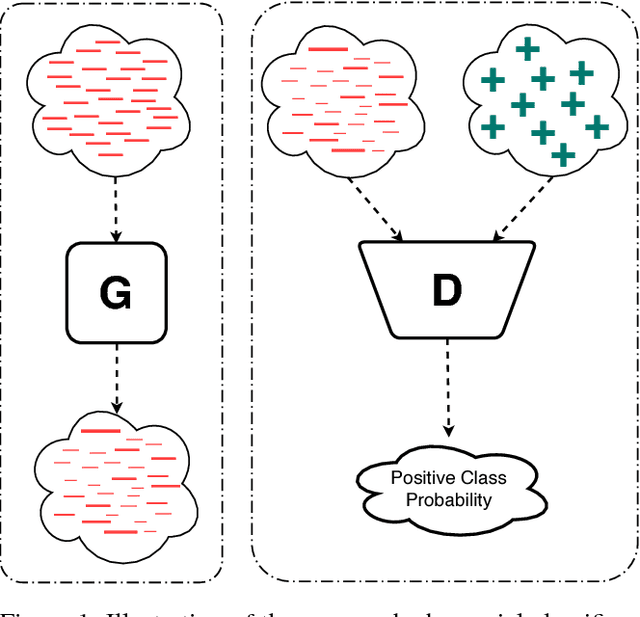
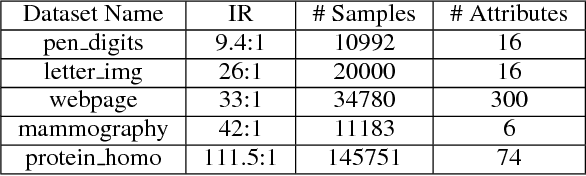
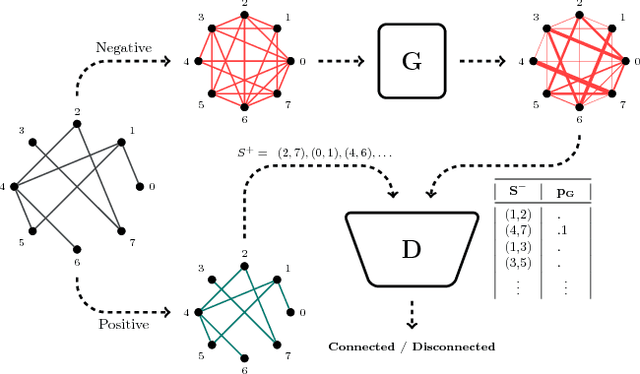
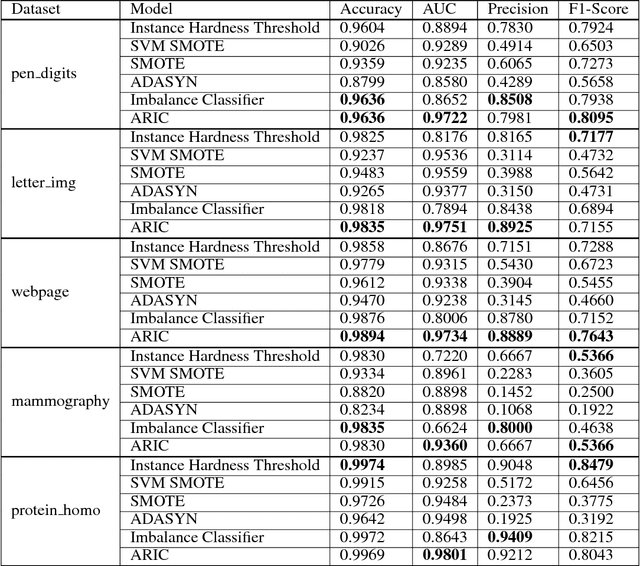
Adversarial approach has been widely used for data generation in the last few years. However, this approach has not been extensively utilized for classifier training. In this paper, we propose an adversarial framework for classifier training that can also handle imbalanced data. Indeed, a network is trained via an adversarial approach to give weights to samples of the majority class such that the obtained classification problem becomes more challenging for the discriminator and thus boosts its classification capability. In addition to the general imbalanced classification problems, the proposed method can also be used for problems such as graph representation learning in which it is desired to discriminate similar nodes from dissimilar nodes. Experimental results on imbalanced data classification and on the tasks like graph link prediction show the superiority of the proposed method compared to the state-of-the-art methods.